本文提出了 FILT3R,一种用于流式 3D 重建的无需训练(Training-free)的自适应隐空间滤波层。该方法将隐式状态更新建模为 Token 空间的随机状态估计,通过引入 Kalman 增益动态平衡历史记忆与新观测,在长序列(Long-horizon)任务中实现了显著的稳定性提升。
TL;DR
流式 3D 重建要求模型在有限内存下,通过不断更新隐状态(Latent State)来吸收新帧信息。然而,如何优雅地处理“喜新厌旧”与“固步自封”的矛盾?本文提出的 FILT3R 引入了**自适应 Kalman 滤波(AKF)**层,无需重训模型,通过在线估计 Token 级别的不确定性,实现了对历史记忆的精准保护与对场景变化的快速响应。在超长序列测试中,其定位与重建稳定性远超现有的覆盖策略和门控机制。
1. 痛点深挖:流式感知的“训练长度限制”
目前的 SOTA 流式重建框架(如 CUT3R)通常在短序列上训练,但在实际应用中,序列长度可能远超训练窗口。这时,简单的更新策略会暴露严重问题:
- 覆盖(Overwrite)策略:每一帧都暴力替换状态,导致严重的“灾难性遗忘”和累积误差。
- 启发式门控(Gating):虽然引入了注意力统计量来调节更新权重,但缺乏物理直觉和时序相干性。 一旦进入长 rollout,隐状态的漂移会导致几何结构的破碎和相机轨迹的崩溃。
2. 核心直觉:隐状态即“置信状态” (Belief State)
作者提出一个深刻的洞见:流式重建的循环状态本质上是一个 Belief State,而解码器产生的新 Token 只是一个带噪声的测量值(Measurement)。
基于此,FILT3R 将更新规则形式化为随机状态估计。核心公式如下:
- 过程模型:$ \mathbf{s}t = \mathbf{s}{t-1} + \mathbf{w}_t, \mathbf{w}_t \sim \mathcal{N}(0, \mathbf{Q}_t) $ (描述场景如何随时间演变)
- 测量模型:$ ilde{\mathbf{s}}_t = \mathbf{s}_t + \mathbf{v}_t, \mathbf{v}_t \sim \mathcal{N}(0, \mathbf{R}) $ (描述解码器预测的可靠性)
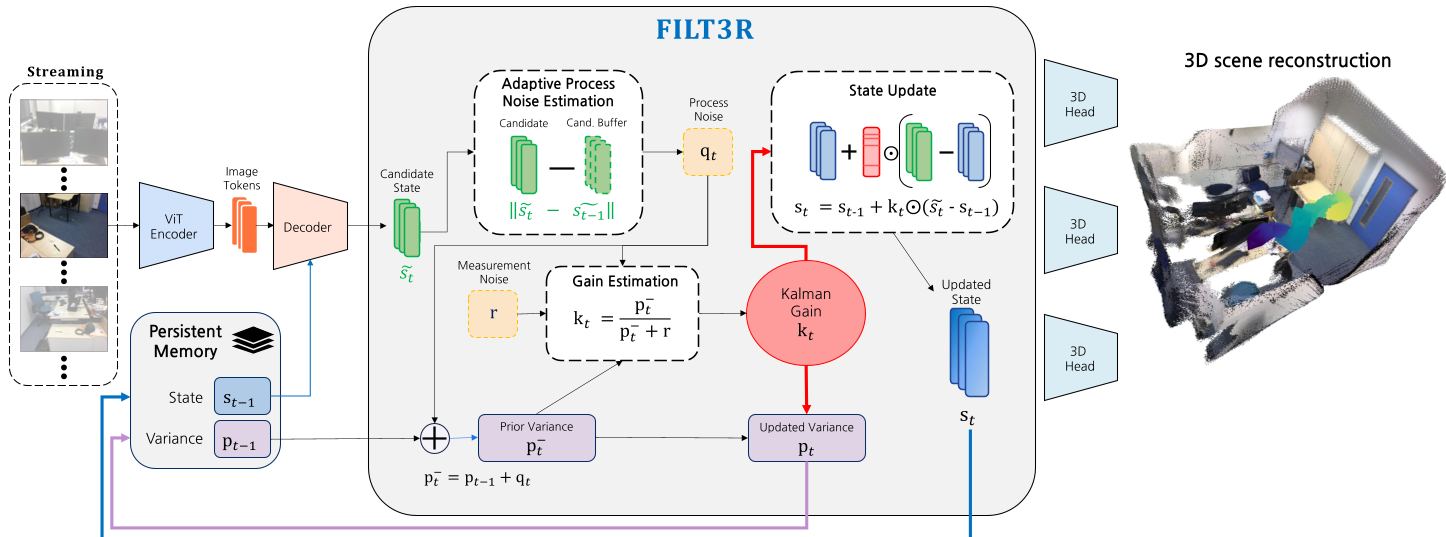 图 1:FILT3R 滤波层在流式框架中的嵌入位置,它作为插拔模块替换了传统的覆盖逻辑。
图 1:FILT3R 滤波层在流式框架中的嵌入位置,它作为插拔模块替换了传统的覆盖逻辑。
3. 方法论详解:自适应过程噪声与固定测量锚点
FILT3R 成功的关键在于其不对称的自适应策略:
- 在线估计 $Q_t$:通过计算连续候选状态之间的时间漂移(Temporal Drift),并使用 EMA 进行流级别的归一化。当检测到剧烈漂移(如相机快速转动)时,增大过程噪声,从而提高 Kalman 增益,让模型“多看新证据”。
- 固定 $R$:作者发现,如果同时自适应 $Q$ 和 $R$,会产生正反馈耦合导致系统不稳定。固定 $R$ 作为一个“稳定性锚点”,体现了预训练解码器本身的固有不确定性。
- 方差收缩(Confidence Accumulation):在稳定场景下,随着证据累积,Token 的后验方差 $p_t$ 会以 $O(1/t)$ 的速率衰减。这意味着模型对旧有记忆越来越自信,从而抑制了噪声的注入。
4. 实验结果:长程时代的统治力
实验在 TUM-RGBD、Bonn 和 7-Scenes 等多个数据集上展开,重点考察了超出训练长度(300-1000 帧)的表现。
关键发现:
- 轨迹稳定性:在 TUM-800 序列上,FILT3R 的 ATEorig(起始对齐绝对轨迹误差)仅为 0.107,比之前最好的 TTT3R (0.214) 降低了一半。
- 几何一致性:实验结果显示,FILT3R 能够生成更连贯的几何体,避免了 TTT3R 在长序列中常见的表面碎片化问题。
 表 1:TUM-RGBD 长序列相机位姿估计对比,FILT3R 在各项指标上均刷新了记录。
表 1:TUM-RGBD 长序列相机位姿估计对比,FILT3R 在各项指标上均刷新了记录。
 图 2:定性重建对比。可以看到 FILT3R(右侧)在回环和长程序列中保持了更好的几何一致性(红色框内)。
图 2:定性重建对比。可以看到 FILT3R(右侧)在回环和长程序列中保持了更好的几何一致性(红色框内)。
5. 深度洞察与总结
FILT3R 的核心价值在于它提供了一个可解释的、端到端的滤波器视角来重新审视 Transformer 的循环记忆。
- 为什么它比重置(Reset)策略好? 重置会丢弃上下文并导致尺度跳变,而 FILT3R 通过方差传播保留了全局一致的信念。
- 局限性:目前主要针对 3D 重建任务,对于更通用的视频理解或长文本建模,其 Token 级的各向同性方差假设是否依然成立仍需验证。
总结 (Takeaway):FILT3R 证明了经典控制理论中的 Kalman 滤波精神并未过时。在神经网络难以泛化的长程推理任务中,引入具有显式物理含义的不确定性传播机制,是提升流式模型鲁棒性的“银弹”。