本文推出了 FinTradeBench,这是一个专门用于评估大语言模型(LLMs)在金融推理能力的基准测试集。它首次将公司基本面(Fundamentals)与市场交易信号(Trading Signals)深度集成,涵盖了纳斯达克100指数公司十年间的1,400个真实历史问题,是目前最贴近真实投资决策场景的测试集。
TL;DR
在金融投资领域,优秀的分析师不仅要看财报(Fundamentals),还要看盘面(Trading Signals)。然而,目前的 AI 测评集大多只考查前者。UCF 团队提出的 FinTradeBench 填补了这一空白。研究发现:强如 DeepSeek-R1,在面对“财报利好但股价阴跌”的冲突场景时,虽然比普通模型更强,但仍会被过多的检索信息“带偏”。
1. 痛点:被“阉割”的金融推理
目前的金融大模型评估存在一个巨大的误区:认为只要能看懂 SEC(美国证券交易委员会)的财报,AI 就能做投资。 实际上,真实的交易世界是高度异构的:
- 基本面(Fundamentals):基于会计准则,反应的是公司的“体质”,例如 ROA, Debt/Equity。
- 交易信号(Trading Signals):基于市场博弈,反应的是“情绪”和“趋势”,例如 RSI, MACD, 波动率。
作者通过 NVIDIA 的案例(下表)展示了现状:当被问及“2025年7月的股价回调是否是买入机会”时,绝大多数 LLM 根本无法正确识别当时的 RSI 或动量指标,甚至会产生时间线上的幻觉。

2. 核心架构:校准-规模化(Calibration-then-Scaling)
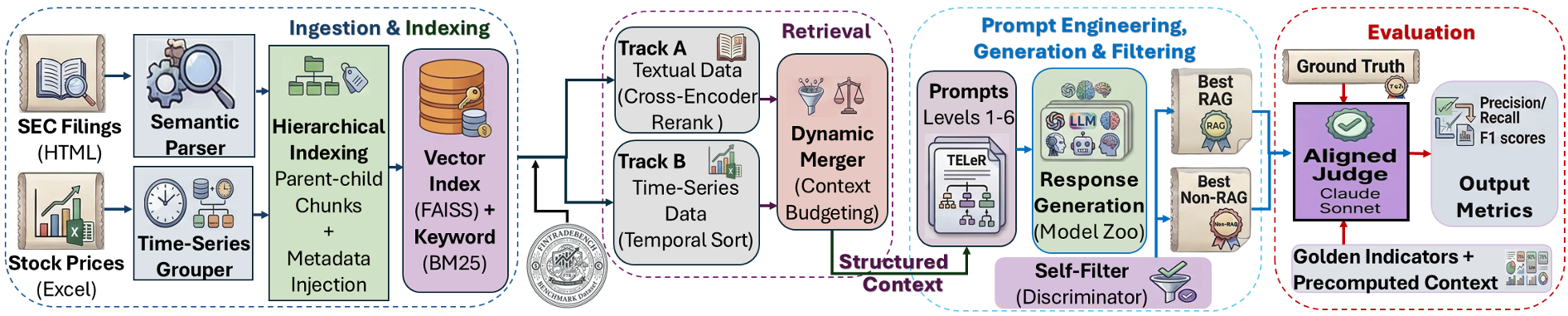
构建一个高质量的金融推理基准极其昂贵,因为需要昂贵的金融专家审核。作者提出了一套自动化的流水线:
- 专家建模:专家编写 150 个种子问题,并标注“黄金指标(Golden Indicators)”。
- 双轨检索(Dual-Track RAG):
- Track A:针对 SEC 文本,使用父子映射(Parent-Child Chunking)保留长上下文。
- Track B:针对行情数据,将数值序列转化为结构化表格。
- 多模型校准:使用 Claude-4.5 作为“裁判”,通过与人类专家的评分对齐(MAE < 10%),实现大规模自动化扩展。
3. 实验洞察:RAG 是一把“双刃剑”
通过对 DeepSeek、Llama 3.3、Gemini 等 14 个模型的测评,文章得出了几个令人惊讶的结论:
结论一:RAG 偏科严重
- 基本面推理(F-type):RAG 带来了巨大的提升。R1-Distill-Qwen 获益最高(+37%),因为模型在预训练阶段就见过大量 SEC 文本,检索起到了“锚定”作用。
- 交易信号(T-type):RAG 竟然起到了反作用!多个模型的表现下降了近 20%。 深度洞察:模型并不擅长直接解析检索到的原始行情表格(Raw Numerical Tables)。这种数据对模型来说像“乱码”,注入上下文窗口反而会产生干扰(Distraction)。
结论二:推理模型(Reasoning LLMs)的统治力
在最难的**混合推理(FT-type)**中,具备 Latent CoT 能力的模型(如 DeepSeek-R1 原型及其蒸馏版)展现了碾压优势。它们能够分配额外的计算量来权衡“财报利好”与“技术面走低”之间的冲突。

4. 深度洞察:理想与现实的鸿沟(Ideal RAG)
作者做了一个有趣的消融实验:如果我不给模型原始数据,而是给它预计算好的“理想 context”(比如直接告诉它 RSI 是 60.39,而不是让它在一堆价格里算),模型表现瞬间爆表。 结论:当前金融 AI 的瓶颈不在于理解力,而在于预处理能力。直接把 RAG 扔给原始行情序列是在浪费显存。
5. 总结与反思
FinTradeBench 揭示了金融 AI 进入实战的最后几公里障碍:
- 从检索转为计算:单纯靠向量检索文本无法解决数值推理,需要集成 Code Interpreter。
- 降低干扰:Llama 3.3(70B)在多信号场景下极易被长文本噪声分散注意力,如何提升模型在冗长金融文档中的“抗干扰”能力是关键。
这篇论文为未来的金融智能体(Financial Agents)指明了道路:不仅仅是读文档的学者,更应该是懂计算、能调和多方证据的决策者。