本文提出了 Find, Fix, Reason (FFR),一种针对多模态大语言模型(MLLM)视频推理的上下文自我修复框架。该方法通过冻结的、集成工具的“老师”模型诊断推理错误,并为“学生”模型提供不泄露答案的微小证据补丁(Minimal Evidence Patch),通过 GRPO 优化算法实现性能突破。
TL;DR
在视频推理领域,大模型常常因“看漏了”或“想错了”细节而陷入瓶颈。本文提出的 FFR (Find, Fix, Reason) 框架,通过引入一个“老师”模型在大模型做错时提供手术刀般的上下文修复(Context Repair),帮助“学生”模型重新定位关键时空证据。实验表明,这种方法能让 7B 学生模型在多项基准测试中反超其 235B 的老师,且相比传统 SFT 和 RL 具有更强的逻辑内化能力。
背景定位:为何视频推理总是“差临门一脚”?
在当前 MLLM 的研究坐标系中,纯粹的**自探索强化学习(On-policy RL)**往往会受限于模型自身的“知识天花板”。就像一个学生对着难题死磕,如果他最初就忽略了某个关键条件,再怎么想也得不出正确答案。
现有的解决思路分为两派:
- 混合回放(Hybrid Replay):强行混入老师模型的推理轨迹,但由于视频数据的时空分布极其复杂,容易导致模型过于拟合文本套路(Shortcuts)而丧失泛化性。
- 工具集成(Tool-use):让模型自己去搜证据。但小模型往往感知力不足,经常在“搜证据-怀疑自己-再搜错”的怪圈里打转。
FFR 核心逻辑:不给标准答案,只给“放大镜”
FFR 的创新之处在于它将“老师”模型定位为一个观察层的干预者。
1. 寻找与修复 (Find & Fix)
当学生采样出的推理路径(Rollout)失败时,FFR 启动。老师模型不再直接告诉学生“答案是 B”,而是利用各种视觉工具(如 zoom_region 或 get_temporal_segment)找出关键信息所在的帧区间或空间范围,生成一个最小证据补丁 (Minimal Evidence Patch)。
- 例子:如果问题是“球撞到了什么?”,老师会提示“观察第 13-15 帧中手部释放物体的一瞬间”,而不是直接说“撞到了书”。
 Figure 1. FFR 流程图:老师诊断错误 -> 提取证据补丁 -> 学生二次推理并更新。
Figure 1. FFR 流程图:老师诊断错误 -> 提取证据补丁 -> 学生二次推理并更新。
2. 推理与内化 (Reason & Internalize)
学生带着补丁重新推理。为了防止学生对补丁产生依赖(变成“不给提示就不会做”),作者在 GRPO 算法中设计了 RIR (Robust Improvement Reward),并加入了一个 Patch Tax (补丁税) $\kappa$。如果学生是靠补丁才做对的,奖励分数会比完全独立做对要低,以此推动模型在训练过程中将寻找这类证据的能力转化为内在的感知逻辑。
实验战果:以小博大的“反杀”
FFR 在四大推理榜单和四大通用理解榜单上表现惊人。
- 碾压 SFT:相比于直接在老师的轨迹上做全量微调(SFT),FFR 的干预机制更有效。它证明了模型需要的是“如何去寻找证据”的启发,而非“正确答案长什么样”。
- 跨规模越级:基于 Qwen3-VL-8B 的学生模型在 Video-Holmes 指标上跑到了 48.7,远超其 32B 老师的 42.6。
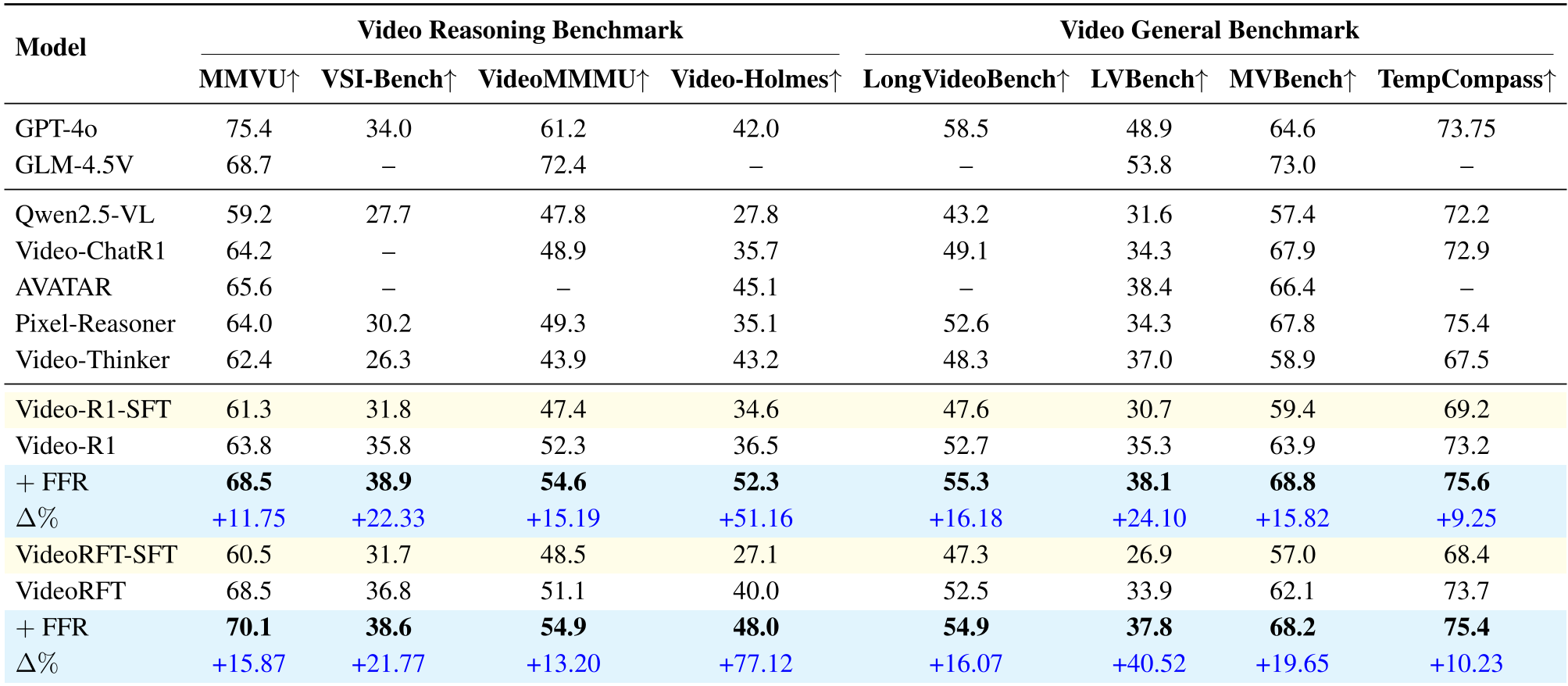 Figure 2. 关键结果展示:FFR 在各项基准测试中相比 Video-R1 和其他 RFT 方法的显著提升。
Figure 2. 关键结果展示:FFR 在各项基准测试中相比 Video-R1 和其他 RFT 方法的显著提升。
深度洞察:为什么这种方法更稳健?
作者在消融实验中揭示了一个关键点:视觉上下文(Visual Context)是推理的命门。 如果不提供视觉证据(只提供文本指导),性能会大幅下降(Video-Holmes 下降 10 分)。这说明视频推理的本质瓶颈在于“感知与意图的对接”。
此外,FFR 成功规避了答案泄露 (Answer Leakage)。通过结构化负向提示词(Negative Prompting),老师提供的补丁即便给人类看,人类也无法直接猜出答案,这种设计确保了学生必须真实地重走一遍视觉处理逻辑。
局限性与展望
FFR 虽然有效,但目前依赖于一个强大的冷冻(Frozen)老师模型,其推理成本在训练初期较高。作者指出,未来的方向在于自蒸馏(Self-distillation),即如何让学生模型在掌握了这套搜索证据的逻辑后,能够反过来进行自我修正,摆脱对外部 API 老师的依赖。
对于开发者而言,FFR 提供了一种极其轻量化的手段:不需要海量的数据重标注,只需要利用现有的闭源高能力模型作为教师,就能在特定垂直领域的视频推理中大幅提升小模型的表现。