FineViT is a specialized vision encoder designed to enhance fine-grained perception in Multimodal Large Language Models (MLLMs). It utilizes a 0.86B parameter ViT architecture trained via a progressive three-stage strategy, achieving SOTA performance in long-context retrieval and significantly outperforming SigLIP2 and Qwen-ViT when integrated into MLLMs.
TL;DR
FineViT is a new visual foundation model that addresses the "visual detail amnesia" found in traditional CLIP encoders. By replacing noisy web-crawled captions with a massive dataset of 454M region-level recaptions and training through a progressive three-stage curriculum (MIM → Contrastive → LLM Alignment), FineViT achieves unprecedented accuracy in OCR, long-context retrieval, and spatial grounding.
The Motivation: Why CLIP is No Longer Enough
For years, Multimodal Large Language Models (MLLMs) have treated the visual encoder as a "static artifact"—usually a pre-trained CLIP model. However, this has led to a persistent performance ceiling:
- Resolution Compression: Resizing images to 224x224 or 336x336 acts as a lossy compression that "obliterates" details like small text or distant objects.
- Semantic Noise: Web-crawled captions (like LAION) are often brief, misaligned, or purely global, lacking the granular detail needed for dense spatial reasoning.
- Objective Mismatch: Contrastive learning focuses on global matching, while LLMs operate on autoregressive token prediction, creating a "modality gap" during alignment.
Methodology: The Progressive Unlocking Paradigm
FineViT moves away from "one-shot" pretraining in favor of a three-stage curriculum learning strategy:
Stage I: Foundational Geometry (MIM)
The model starts with Masked Image Modeling (MIM). By reconstructing masked patches, the encoder develops an early "physical sense" of object boundaries and geometric structures before seeing a single word of text.
Stage II: Semantic Grounding (Contrastive Learning)
Instead of raw web data, the authors recaption 1.56B images using an ensemble of MLLMs (Qwen2.5, InternVL). The training resolution is bumped to 448x448 native, and the text context length is extended from 77 to 256 tokens to accommodate these richer descriptions.
Stage III: The Local Specialist (FineCap-450M)
This is the "secret sauce." The authors curated FineCap-450M, the largest fine-grained dataset to date. It includes:
- Global Captions: Detailed scene descriptions.
- Local Captions: Region-specific descriptions (e.g., "the ribbed texture of the building surface").
- OCR & Document Data: Fine-grained text coordinates for natural scenes and documents.
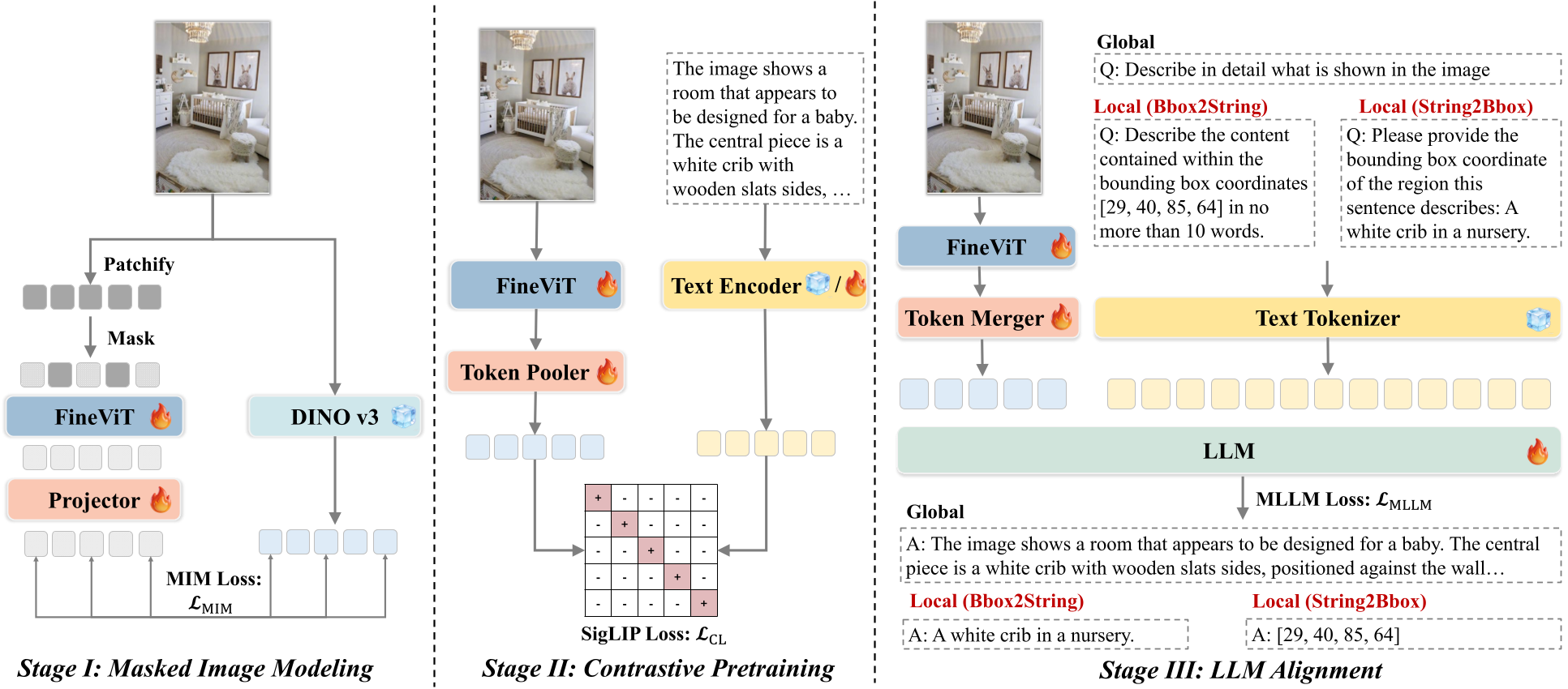 Figure 1: FineViT's progressive training paradigm from MIM to Multi-Granularity Alignment.
Figure 1: FineViT's progressive training paradigm from MIM to Multi-Granularity Alignment.
Key Breakthrough: Long-Context Retrieval
One of the most impressive feats of FineViT is its ability to handle "paragraph-length" visual queries. In datasets like DCI and Urban-1K—where queries describe specific, minute details of a scene—FineViT destroys the previous SOTA.
| Model | DCI T2I (Long Text) | Urban-1K T2I | | :--- | :--- | :--- | | SigLIP2-so400m | 66.8 | 75.6 | | FixCLIP-L | 74.2 | 96.3 | | FineViT (Ours) | 84.8 | 99.1 |
 Figure 2: FineViT demonstrates superior alignment between long, complex text descriptions and intricate visual layouts.
Figure 2: FineViT demonstrates superior alignment between long, complex text descriptions and intricate visual layouts.
Experimental Results: Performance in MLLMs
When integrated into MLLMs (renamed FineViT-VL), the model shows that "better vision leads to better reasoning." In OCR and Document tasks (DocVQA, ChartQA), it surpasses much larger models by preserving high-resolution spatial features.
- Local Perception Gain: +11.31% average margin over SigLIP2 when paired with Qwen3-1.7B.
- Ablation Insight: Unfreezing the visual backbone (Stage III) is critical for "local" tasks where exact positioning is required, whereas a frozen backbone suffices for simple classification.
 Figure 3: Ablation study showing the massive impact of Stage III alignment on OCR and Grounding scores.
Figure 3: Ablation study showing the massive impact of Stage III alignment on OCR and Grounding scores.
Critical Analysis & Conclusion
FineViT represents a shift in the AI community's focus from "more parameters" to "better data representation." By treating the visual encoder as an evolving component rather than a static one, the researchers have solved many of the grounding and OCR hallucinations that plague current multimodal models.
Limitations: Currently, FineViT is restricted to static images. The next challenge is applying this dense, fine-grained perception to video data, where temporal dynamics add another layer of complexity to local feature tracking.
Summary Takeaway: If you want your MLLM to "see" better, stop using noisy global captions. The path to fine-grained perception lies in dense, region-level recaptions and a progressive training recipe.