本文提出了 Flow-OPD,这是首个将在线策略蒸馏(On-Policy Distillation, OPD)引入流匹配(Flow Matching)模型的后训练框架。该方法通过整合多个专精领域教师模型的稠密轨迹级监督,成功将 Stable Diffusion 3.5 Medium 的 GenEval 分数从 63 提升至 92,OCR 准确率从 59 提升至 94。
TL;DR
来自中科大、加州大学洛杉矶分校(UCLA)和香港中文大学的研究团队推出了 Flow-OPD。这是第一个将大语言模型(LLM)中大获成功的**在线策略蒸馏(On-Policy Distillation, OPD)引入到流匹配(Flow Matching)**文生图模型中的对齐框架。它通过多教师稠密监督,彻底解决了多任务对齐时的梯度干扰问题,在 SD 3.5 Medium 基础上实现了 OCR 和逻辑推理能力的跨越式提升。
背景定位:从标量奖励演进到稠密指导
在 T2I(文生图)领域,传统的强化学习对齐(如 GRPO 或 DPO)通常依赖一个标量的评测分数(Reward)。然而,图像生成是一个在高维空间寻找最优轨迹的过程,区区一个标量分数就像是导师只告诉学生“这幅画不及格”,却没说哪一笔画错了。
这种奖励稀疏性在多任务场景下尤为致命:当你试图让模型同时学会“精准写字(OCR)”和“唯美意境(Aesthetics)”时,模型往往会为了刷高 OCR 分数而牺牲构图,产生严重的 Reward Hacking(奖励作弊)现象。
痛点深挖:为什么简单的混合训练会失败?
论文通过实验证明,直接混合多个奖励函数进行 GRPO 训练会导致严重的性能崩坏(见下图)。
其核心病灶在于梯度干扰(Gradient Interference)。数学上,不同任务的梯度方向在参数空间中可能完全相反。当模型试图在一个共享的参数空间内同时讨好几个互斥的评价指标时,最终只能陷入一个各方平庸的局部最优解。
核心机制:Flow-OPD 的三板斧
1. 两阶段对齐策略
- Step 1: 培养专家。 先通过专一奖励的 GRPO 训练出各领域的“教书匠”(如专门负责写字的教师,专门负责审美的教师)。
- Step 2: 知识整合。 学生模型通过“冷启动”(SFT 或模型合并)建立基础,再接受多教师的联合调教。
2. 在线路径蒸馏 (On-Policy Distillation)
这是本文的灵魂。不同于传统的离线蒸馏,Flow-OPD 让学生模型“主动探索”。
- 学生从当前策略采样生成图像。
- 任务路由 (Task Routing):根据 Prompt 类型(如写字、构图、审美),将生成的中间状态推给对应的专家。
- 稠密 KL 奖励:专家不只是给最终结果打分,而是针对生成过程中的每一个时间步 ,提供一个参考的速度场 。通过计算学生与专家在速度场上的 L2 距离,将其转化为稠密的 RL 奖励。
3. 流形锚点正则化 (MAR)
为了防止模型在追求功能性(如写字准确)时彻底丢掉画质,作者引入了一个“审美锚点”。即始终有一个冻结的艺术教师模型,作为全局的背景监督,确保学生模型生成的轨迹永远保持在高保真的图像流形内。
实验与结果:青出于蓝而胜于蓝
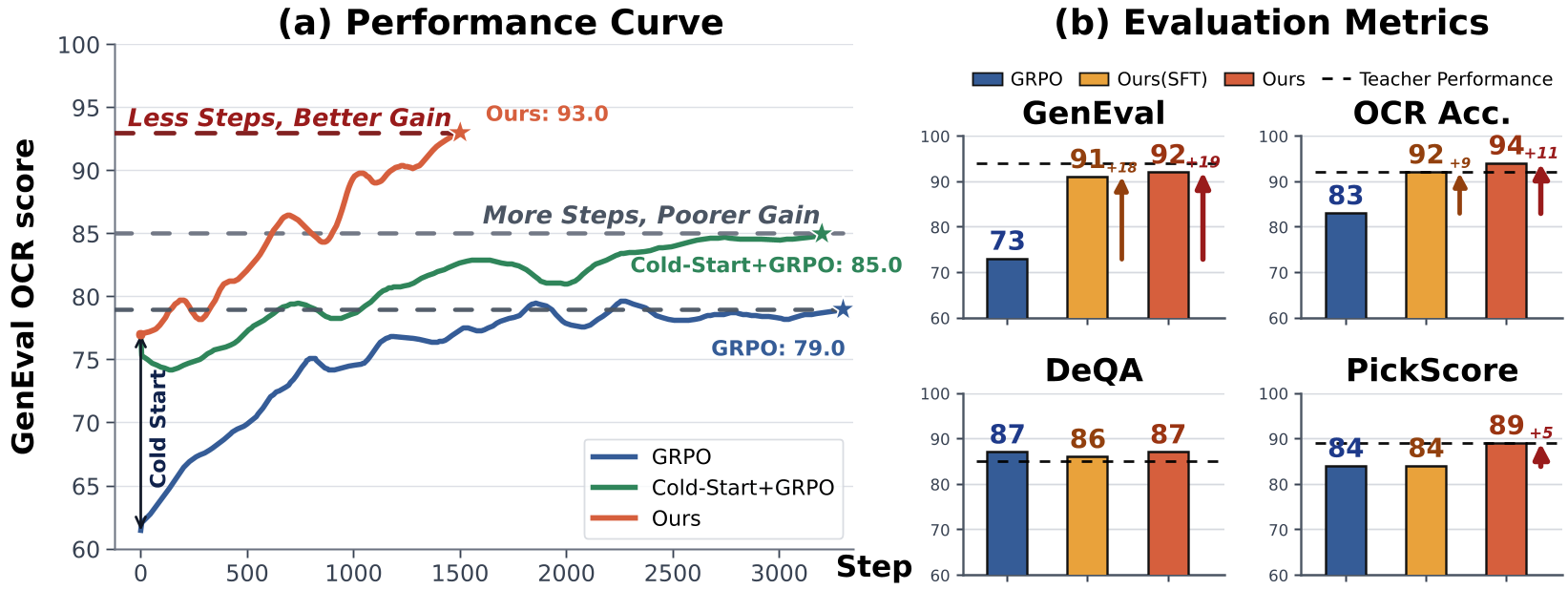
测试结果令人惊艳:Flow-OPD 在 GenEval 和 OCR Bench 等硬指标上,不仅大幅超越了基线 GRPO,甚至在某些情况下超过了它所学习的教师模型。

关键战绩:
- OCR 精度:从 59 提升到 94。
- GenEval 逻辑得分:从 63 提升到 92。
- 泛化性:在 T2I-CompBench 等分布外场景下表现出极强的健壮性。
深度洞察:为何能“溢出”教师的能力?
论文提出了一个有趣的观察:Teacher-Surpassing Effect。当学生模型同时接受多个专家的指点时,它在潜在的流匹配空间中学会了一套更加平滑、更具鲁棒性的表达方式。这种“博采众长”的过程消弭了单一教师可能存在的领域偏见,使得学生模型在复杂的交叉任务中表现得比任何一个单一专家都要好。
总结与局限
Flow-OPD 开启了文生图模型后训练的新范式:从“判别式反馈”转向“生成式引导”。
局限性:
- 结构一致性要求:目前的框架要求学生和教师具有相同的架构(如都是 SD 3.5 变体),以便进行步进式的监督。
- 算力开销:在线采样和多教师并行推理对训练算力提出了更高要求。
未来,Flow-OPD 这种“多专家协同进化”的思路,极有潜力成为打造视觉通用智能体(Generalist Model)的标准工具。