本文提出了 PIXAR,一个针对多模态大模型(VLM)图像篡改检测的新型基准与任务框架。核心贡献是将篡改检测从粗粒度的“物体遮罩(Mask)”重新定义为基于像素、具备语义与语言感知能力的细粒度任务,并发布了包含 42.7 万对图像的 SOTA 基准。
TL;DR
传统的图像篡改检测(Tampering Detection)一直玩着“猜盒子”的游戏:给出一个粗略的物体遮罩(Mask),告诉模型这块可能坏了。但本文指出,生成式 AI 的魔爪早已伸向了 Mask 之外。PIXAR 项目彻底抛弃了 Mask 这种过时的代理,直接利用像素级差异图和多模态解释,建立了一套全新的检测标准。
1. 痛点:Mask 标注的三个致命缺陷
目前大多数检测基准(如 SID-Set, TrainFors)都使用物体的语义 Mask 作为 Ground Truth。然而,在生成式 AI 泛滥的今天,这种做法会产生以下问题:
- 内外失配:编辑信号在物理空间并非均匀分布。Mask 内大量背景像素根本没动(False Positive),而 Mask 边缘因重光照、缝隙处理产生的人工痕迹却被忽略(False Negative)。
- 微观缺失:细小的颜色微调或材质改变,在粗放的 Mask 标注下被淹没。
- 语义断层:模型只知道“哪里变了”,却不知道“变了什么”和“为什么变”。
 图 1:左图显示传统 Mask 与真实篡改像素(红色点)之间的显著偏移,右图为 PIXAR 提出的像素级精准对齐。
图 1:左图显示传统 Mask 与真实篡改像素(红色点)之间的显著偏移,右图为 PIXAR 提出的像素级精准对齐。
2. 核心方法:回归像素差分与多模态协同
为了解决上述痛点,作者提出了 PIXAR (Pixels, Metadata, and Meanings) 框架:
2.1 像素级标签生成 (Difference Map Grounding)
不再依靠物体轮廓,而是通过以下公式直接从源图 和生成图 提取差异: 再通过可调阈值 转化为二进制掩码 。这种设计允许研究者通过调节 来平衡是对“微小扰动”敏感还是对“高置信度修改”敏感。
2.2 训练框架:定位 + 分类 + 描述
PIXAR 不仅仅是一个分类器。它采用了一个多头架构,同时优化五个 Loss:
- :负责像素级的精准定位。
- :多标签分类,识别篡改物体的语义(如猫、车)。
- :生成自然语言描述(如“背景被替换,但主体保留”)。
- :全局真/伪判定。
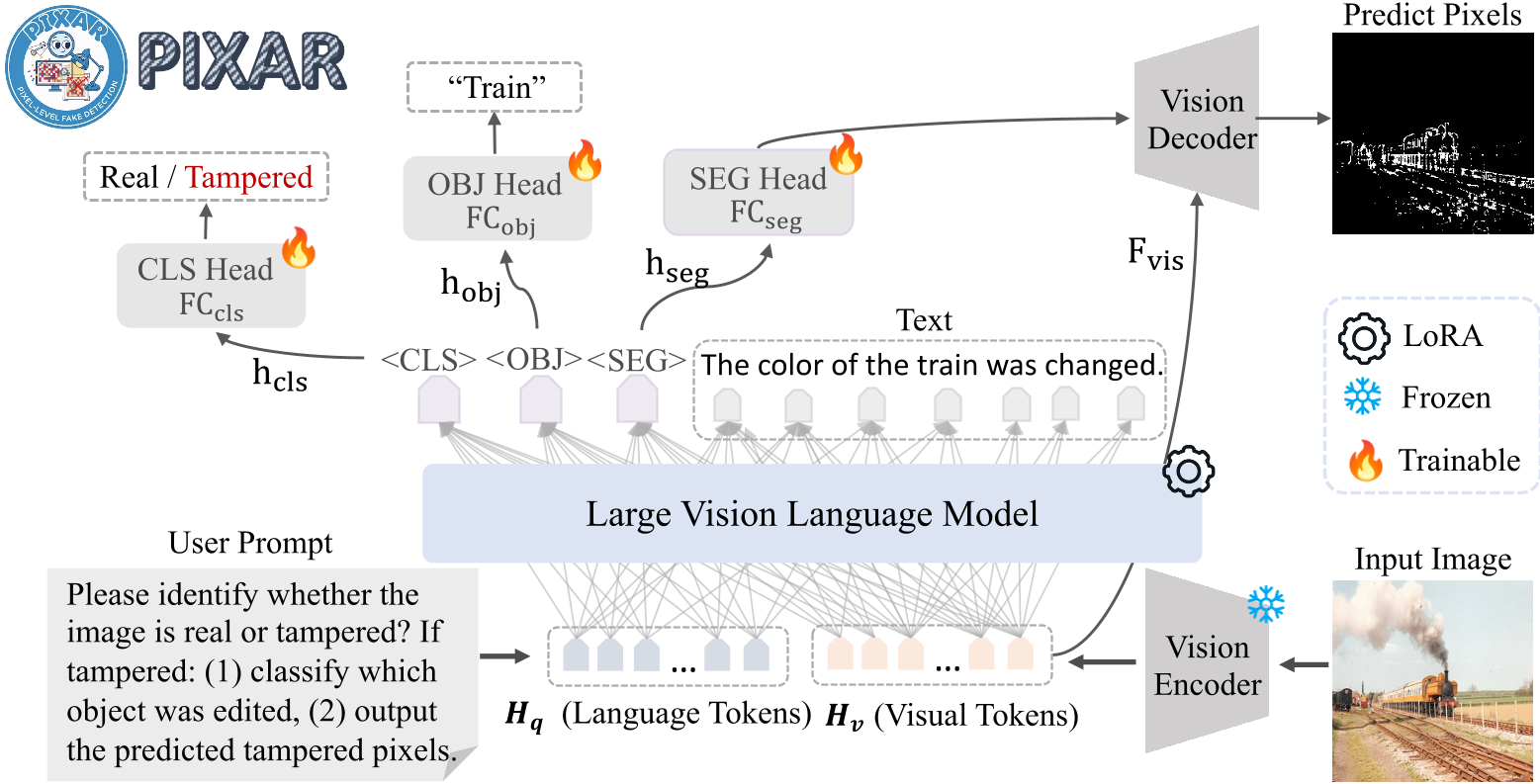 图 2:PIXAR 的多任务训练框架,集定位、分类与自然语言描述于一体。
图 2:PIXAR 的多任务训练框架,集定位、分类与自然语言描述于一体。
3. PIXAR 基准:规模与多样性
PIXAR 发布了超过 38 万对 训练数据和 4 万对 测试数据。其卓越性体现在:
- 8 种篡改类型:不限于简单的物体删除,还包括材质改变、运动模糊修改、颜色微调等。
- 严格的保真度检查:通过 VLM (Qwen3) 自动评分和 10 位专家人工复审,确保篡改后的图片在视觉上几乎无破绽。
- 多模型验证:测试集由 Flux.2, Gemini 3, GPT-Image-1.5, Qwen 等多种主流大模型生成,专门测试检测器的泛化力。
 图 3:PIXAR 涵盖的 8 种细粒度篡改类型示例。
图 3:PIXAR 涵盖的 8 种细粒度篡改类型示例。
4. 实验结果:无懈可击的提升
作者在 PIXAR 对现有的强基线(如 SIDA, LISA, FakeShield)进行了重新评估:
- 检测精度:相比 SIDA-7B,PIXAR-7B 的 IoU 提升了 11.2%,Recall 显著增强。特别是在检测“Mask 边缘外”的人工痕迹时,PIXAR 优势巨大。
- 零样本泛化:即便训练集主要基于 Qwen 模型,PIXAR 在检测 GPT 或 Gemini 生成的图片时,性能依然稳健,证明其捕捉到了 AIGC 在像素层面的某种“共性指纹”。
 表 1:PIXAR 系列模型在语义分类与像素定位上全面碾压此前最优的 SIDA 方法。
表 1:PIXAR 系列模型在语义分类与像素定位上全面碾压此前最优的 SIDA 方法。
5. 深度洞察:为什么我们要关心“语义”?
为什么检测一个伪造图需要知道“它是一个橘子”? 作者认为,语义理解为定位提供了先验约束。单纯的像素差分可能包含相机噪声、对齐误差等干扰,但如果模型知道“这是一个物体的替换”,它就会迫使定位头去寻找更具物体形状感的聚集区域(Concentrated regions),从而过滤散乱的噪声。
6. 局限与总结
PIXAR 虽然大幅提升了检测上限,但对于极端微小的编辑(阈值 极低时)或光照几乎完美融合的情况,检测依然十分困难。 总结:PIXAR 的出现标志着图像取证从此告别“遮罩驱动”时代,正式跨入“多模态像素驱动”时代。这不仅为研究人员提供了一个更难、更准的靶场,也为未来 VLM 的安全性审计指明了方向。