本文提出了 Fus3D,一种无需相机校准、推理时间小于 3 秒的单向联多视图 3D 重构方法。该方法直接从预训练 Geometry Transformer(如 VGGT)的中间潜空间中解码密集有符号距离场(SDF),实现了从非结构化图像集合到完整 3D 几何的快速回归。
TL;DR
在 3D 重构领域,传统的“预测视图特征 -> 反投影 -> 几何融合”流程正在被颠覆。Fus3D 提出,与其在 3D 空间中费力地缝合带有噪声的单视图预测,不如直接利用预训练多视图 Transformer(如 VGGT)内部已经构建好的、逻辑连贯的“世界潜表征”。通过一个轻量级的体积提取模块,Fus3D 能够在 3 秒内从几张照片中直接生成完整的 SDF 几何,且在稀疏视图下表现出惊人的几何补全能力。
1. 痛点:为什么“先预测再融合”是死路一条?
当下的 SOTA 模型(如 DUSt3R, VGGT)在单视图深度估计上已经非常强大,但将它们转化为最终的 3D 模型时,通常依赖于后处理融合(如 TSDF Fusion 或 Poisson Reconstruction)。这种设计存在两个“先天缺陷”:
- 稀疏视角下的“洞”:如果模型只看到物体的正面,单视图预测无法推断背面。融合后的结果在未观测区域就是缺失的。
- 噪声积累:当输入图片增加到几十张时,每一张图微小的位姿或深度误差会在融合时交织,导致结果变得模糊或充满伪影。
Fus3D 的直觉是: Transformer 在处理多张图时,其层间的注意力机制(Self/Cross Attention)其实已经“理解”了物体的对称性和整体结构,只是我们以前只取了它的输出层,而浪费了它中间极其丰富的 3D 先验信息。
2. 核心机制:体积提取模块 (Volumetric Extraction)
Fus3D 的核心不再是回归像素级的深度,而是像“从水里捞东西”一样,从 2D 特征流中提取出 3D 体积。
2.1 架构设计
模型包含三个主要组件:
- Backbone:使用预训练的 VGGT,负责提取跨视图的联合特征。
- Extraction Transformer:这是灵魂所在。它初始化一个 的 3D 潜特征网格,然后将这些网格点作为 Query,分阶段去“访问”Backbone 中的 2D 特征(如图 3 所示)。
- 3D Decoder:一个简单的卷积上采样网络,将生成的特征网格映射为高分辨率()的 SDF。
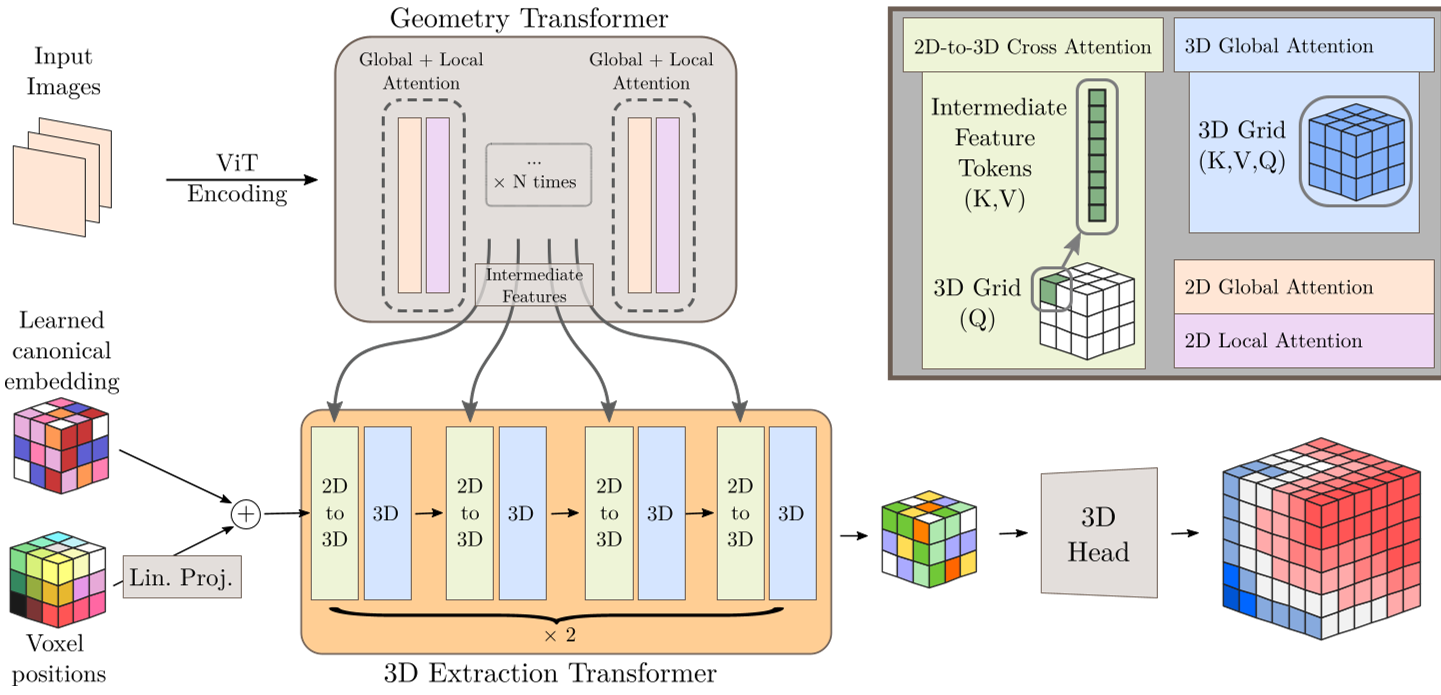
2.2 有效性感知监督 (Validity-aware Supervision)
在训练中,真实世界的 3D 数据往往不是完美的“流形”(如物体有破洞)。Fus3D 引入了 Eikonal 掩码,在梯度不连续或符号模糊的区域自动降级为“无符号距离(Unsigned Distance)”监督,这大大增强了模型处理大规模、非完美数据集(如 Objaverse)的能力。
3. 实验战绩:速度与质量的飞跃
3.1 稀疏视图补全
如图 1 所示,即使只有 2 张输入视图,由于 Fus3D 提取的是 Transformer 的联合先验,它能自动完成物体的背面补全。相比之下,传统的 VGGT + TSDF 只能得到残缺的薄片。
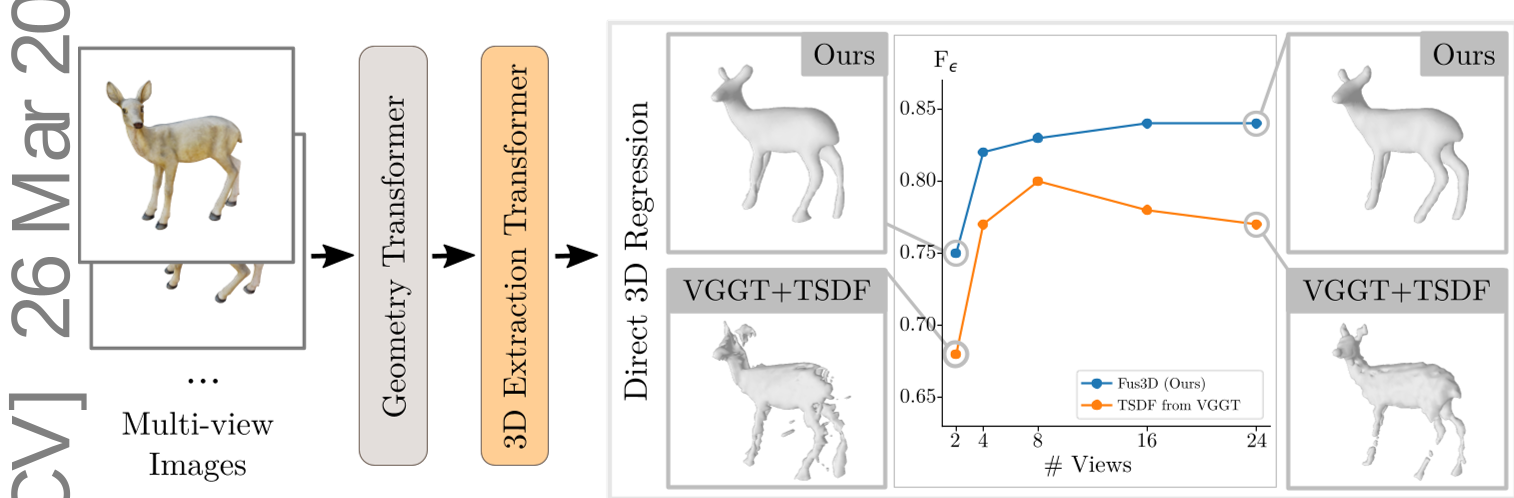
3.2 随视图数量的线性扩展
最令人惊喜的是其稳定性。随着视图增加,VGGT+TSDF 的 F-score 往往会因为噪声累积而下降;而 Fus3D 能够持续利用新信息,在 F-score 和倒角距离上保持领先(见图 5)。
4. 深度洞察:潜空间里到底有什么?
作者对提取出的 3D 潜特征()进行了 PCA 分析。结果发现(见图 9),主成分的颜色分布在同类物体上高度一致。这说明:体积提取模块并不是在机械地堆砌像素,而是真的构建出了一套具备语义一致性的 3D 表征。 特征网格的特定位置甚至对物体的特定部位(如人脸、四肢)产生了响应。

5. 总结与未来展望
Fus3D 成功消除了 2D Transformer 和 3D 重构任务之间的“最后一公里”障碍。它证明了 “Latent-based Lifting”(潜空间提升)优于 “Result-based Fusion”(结果空间融合)。
目前的局限:
- 由于采用了密集的 3D 网格,受显存限制分辨率仅为 ,细节上可能略有平滑。
- 未来方向:引入稀疏卷积(Sparse Convolution)或多尺度上采样,同时将 3D 特征提取模块更好地与 Backbone 融合(变成“可读写”的 Spatial Memory),这将是通往高精度、实时全场景重构的关键。
本文由资深学术主编重构。更多技术细节请参考原论文:arXiv:2603.25827v1。