本文提出了 Action-State Consistency(动作-状态一致性)作为评估世界动作模型(WAMs)可靠性的核心指标。该方法通过度量预测未来观测与执行动作后实际观测之间的对齐程度,实现无需显式奖励模型的测试时动作选择(Test-time Selection)。
TL;DR
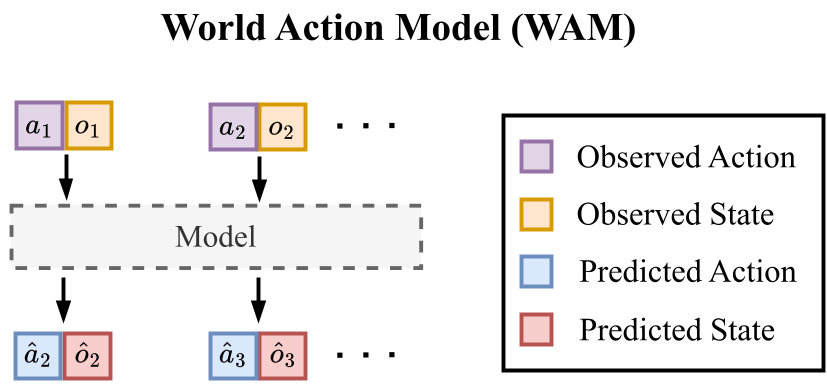
在机器人领域,世界动作模型(World Action Models, WAMs)正成为一种新范式,它们不仅预测“该做什么”(Action),还想象“会发生什么”(Future Observation)。然而,这些“白日梦”真的靠谱吗?本文提出了 Action-State Consistency 概念,揭示了预测未来与真实执行之间的一致性才是决定任务成败的关键,并据此设计了一种无需奖励函数的测试时评估策略。
1. 背景:视觉逼真不等于动力学正确
现有的 Vision-Language-Action (VLA) 模型通常直接输出动作。为了更智能,研究者引入了 WAMs,让模型在执行前先“预演”未来。但是,目前大多数评估指标关注的是生成的图片像不像真实的(Visual Realism),而非动作与状态转换是否匹配。
作者指出,一个不可靠的 WAM 可能会生成一段视觉上非常丝滑、但完全无视输入动作物理反馈的视频(例如预测门开了,但实际动作根本没碰到门把手)。这种动力学不兼容是机器人任务失败的隐形杀手。
2. 核心机制:Action-State Consistency
作者通过定量度量预测状态 与真实状态 之间的相似度,定义了一致性分数: 其中 是在 VAE 潜空间计算的 MSE。其核心逻辑是:如果模型真正理会了物理规律,那么在相同动作驱动下,预测的未来应与真实观测高度重合。
WAM 的两种范式
- Joint-Prediction (联合预测): 动作和未来观测在统一分布中生成(如 Cosmos-Policy)。
- Inverse-Dynamics (逆动力学): 先预测未来状态,再反推达成该状态所需的动作(如 LingBot-VA)。
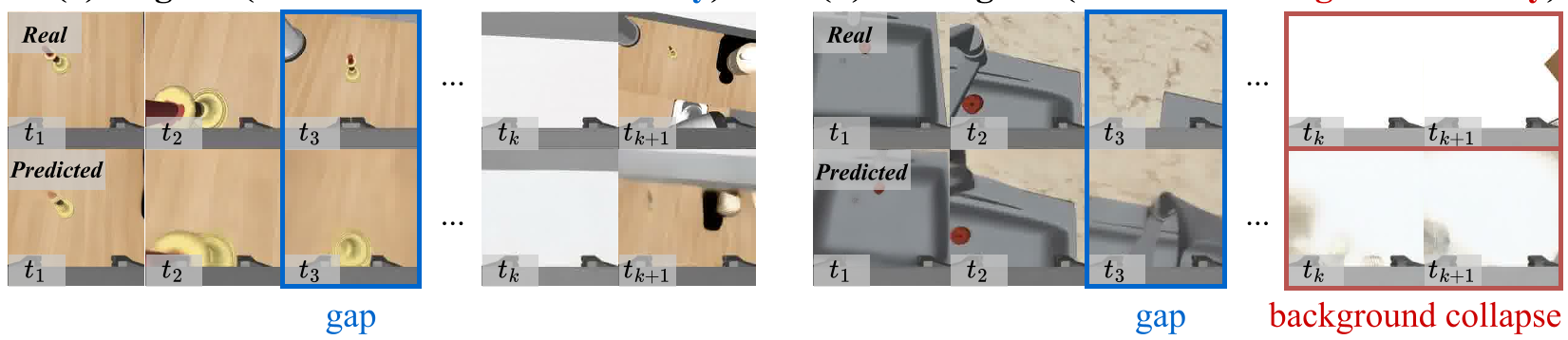
3. 诊断发现:背景坍缩(Background Collapse)
研究发现,一致性并不是在任何时候都“越大越好”。作者识别出一种有趣的失效模式:Background Collapse。
当机器人卡住不动(Stalled)时,预测会退化为静态的背景,因为静态视频最容易被预测。此时,模型的“动作-状态一致性”因为预测任务变简单而显得异常高,但实际上并没有在完成任务。通过监测 Latent Change Magnitude(潜空间变化幅度),可以有效识别并剔除这种虚假的一致性。
4. 应用:价值无关的共识策略 (Future Consensus)
既然一致性能预示成功,能否用它来指导决策?作者提出 Future Consensus 策略:
- 采样 个候选分支。
- 计算所有分支预测未来的均值作为“共识”。
- 选择那个与其预测未来与共识最接近的分支进行执行。
这种方法不需要耗时的环境重置(Reset),也不需要训练复杂的 Value Head 或 Reward Model,完全在模型推理阶段完成优化。
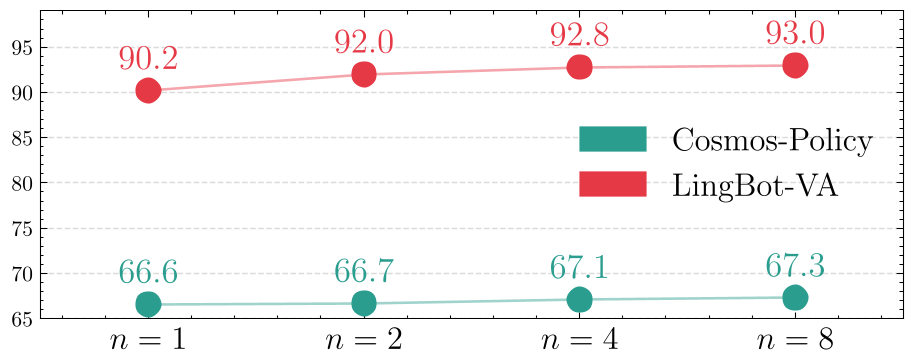
5. 实验分析:一致性能带来多大提升?
在 RoboCasa (单臂厨房任务) 和 RoboTwin 2.0 (双臂协作任务) 上,该策略展示了卓越的泛化性。
- 成功率分离:实验曲线显示,成功路径的一致性显著高于失败路径,其 AUC 预测效力极强。
- 性能增长:随着采样分支 的增加,成功率呈现明显的 Scaling Law 趋势。
6. 编辑深度洞察
这篇论文最深刻的 Insight 在于将“自洽性”引入了具身智能。过去我们依赖环境反馈(Reward)来优化,但环境反馈往往是稀疏且滞后的。本文证明了模型内部的逻辑闭环(即:我预测的动作一定要能推导出我预测的画面)本身就是一种极强的监督信号。
虽然目前仍受限于“背景坍缩”导致的误报,但其提出的 Future-Consensus 为解决 LLM/VLA 在物理世界中的“幻觉”问题提供了一条极其高效的路径。未来,一致性 aware 的 WAM 模型或许能像 LLM 的思维链一样,不仅输出答案,还能自我纠错。