G A M E P L AY Q A is a novel benchmarking framework designed to evaluate Multimodal Large Language Models (MLLMs) in decision-dense 3D virtual environments. It features 2.4K diagnostic QA pairs derived from 9 multiplayer games, using a "Self-Other-World" entity decomposition and synchronized multi-video (POV) feeds to test agentic perception.
TL;DR
As we move toward a future of autonomous 3D agents, researchers from USC have introduced G A M E P L AY Q A, a benchmark that moves past "passive video watching" into the realm of agentic perception. By using high-speed 3D gameplay with synchronized multi-POV videos, they’ve created a "cognitive sandbox" that proves even the best models (GPT-5, Gemini 2.5) are still primitive when it comes to tracking multiple agents, counting occurrences, and maintaining temporal logic in fast-paced environments.
The Motivation: Why Watching TV Isn't Enough for Agents
Most current Video-QA benchmarks are like asking an AI to describe a slow-moving documentary. In reality, a robotic agent or a 3D virtual assistant operates in a world where things happen in milliseconds. This paper identifies the lack of "Decision Density" in current datasets.
The authors argue that true agentic perception requires three pillars:
- Self-Tracking: What am I doing right now? (Ammo, health, actions).
- Other-Agent Modeling: What are my teammates and enemies doing?
- World Grounding: What is changing in the environment (explosions, notifications)?
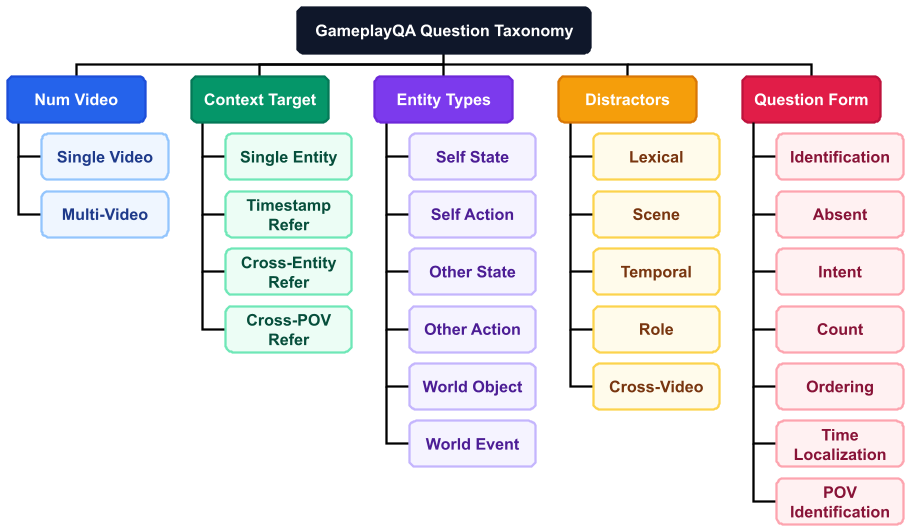
Methodology: The Self-Other-World Framework
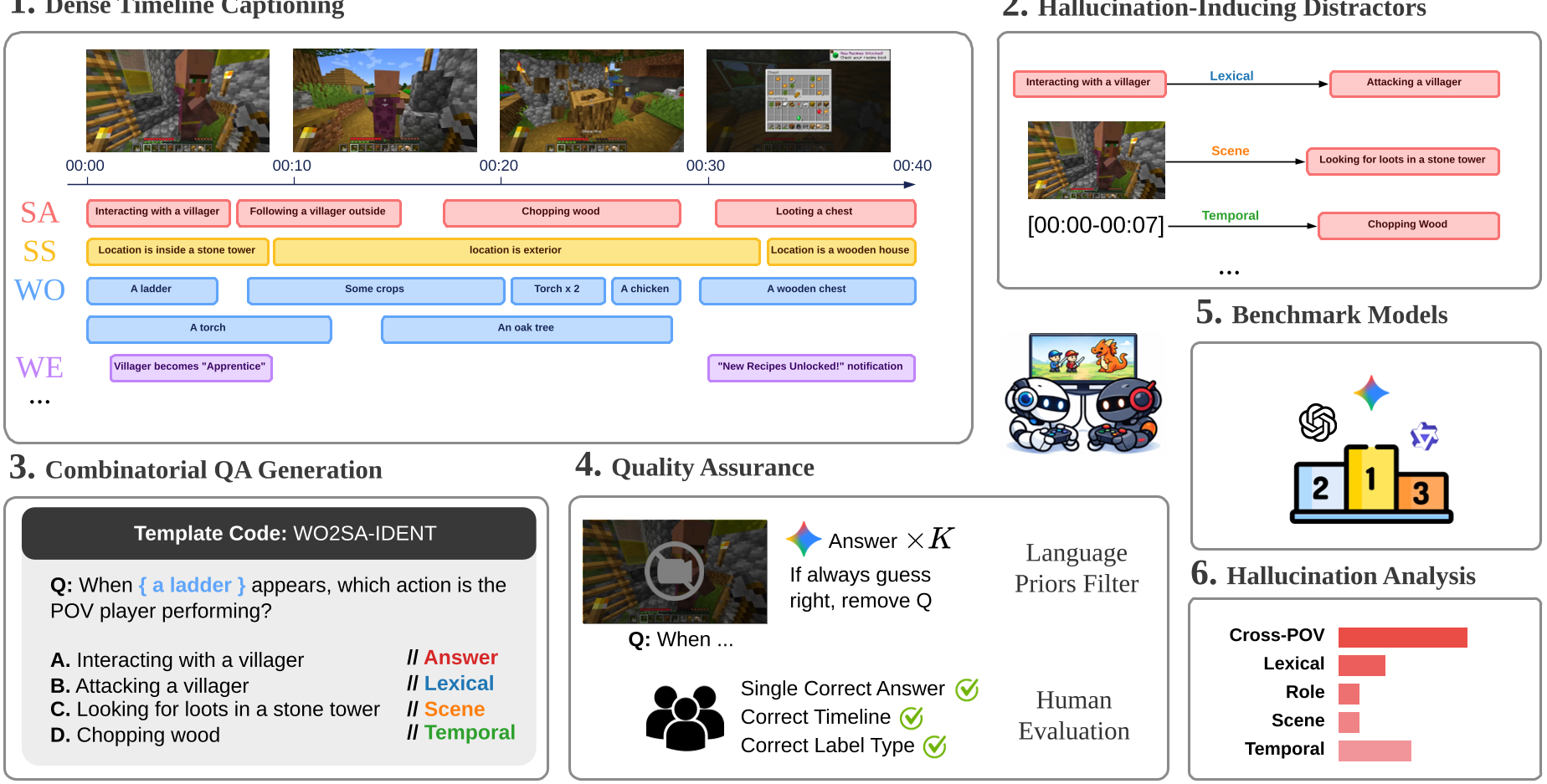
The core innovation is the Self-Other-World decomposition. Instead of flat captions, the authors use a multi-track timeline. Imagine a spreadsheet where every second has six tracks of data running in parallel.
The Diagnostic Pipeline
- Dense Annotation: Labeling at 1.22 labels/second—roughly 10x denser than standard sets.
- Combinatorial QA: A template system that generates 400K candidates, downsampled to 2.4K high-quality pairs.
- Structured Distractors: When a model gets a question wrong, we know why. Did it confuse the player with the enemy (Role confusion)? Did it see something that happened 10 seconds ago (Temporal confusion)? Or did it just hallucinate (Scene confusion)?
Experiments: Where Do Frontier Models Break?
The researchers tested 16 models including GPT-5 and Gemini 2.5. The results reveal a clear hierarchy of difficulty:
- L1 (Basic Perception): Models are decent (~61% accuracy).
- L2 (Temporal Reasoning): Performance drops as soon as "how many times" or "in what order" is asked.
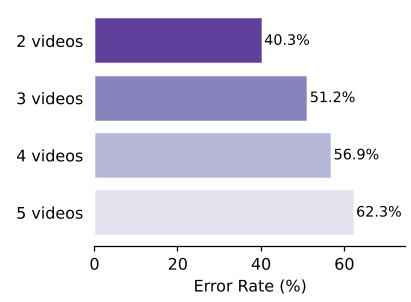
- L3 (Cross-Video Understanding): This is the death zone. When models have to sync information across two different players' screens, accuracy plummets to 49%.
Key Findings:
- The "Other-Agent" Gap: Models are significantly worse at tracking other players (Other-Action) than tracking world objects. This suggests a lack of "Theory of Mind" or entity-based attention.
- Game Pace Matters: Models performed much better on Minecraft (slow) than on Counter-Strike 2 (fast). As the frames-per-decision increases, the MLLM's internal representation collapses.
- Counting is Broken: "Occurrence Count" was the hardest task, with a measly 36.5% average accuracy. Models cannot yet "count" events over time reliably.
Critical Analysis: The Road Ahead
While G A M E P L AY Q A is a massive step forward, it identifies its own frontier: Intent. While the benchmark asks "Why did the player do X?", it doesn't yet ask "What should the player do next?"
The paper also highlights a sobering reality: Human-AI Gap. Humans still outperform the best models by nearly 10-15% on average, particularly in complex multi-POV scenarios where we naturally "stitch" different perspectives together into a single global state.
Conclusion
G A M E P L AY Q A proves that being "good at video" isn't enough for the next generation of AI. To be an agent, a model needs to understand concurrent events, attribute roles correctly, and navigate the high decision density of a 3D world. This benchmark provides the first rigorous "Gym" for these capabilities.