GaussFusion 是一种利用几何感知视频生成技术提升 3D Gaussian Splatting (3DGS) 重建质量的新方法。它通过引入包含颜色、深度、法线、不透明度和协方差的 GP-Buffer,结合视频生成先验,显著消除了 3D 重建中的悬浮物(floaters)、闪烁和模糊,在多项新视角合成基准测试中达到 SOTA 水平。
TL;DR
斯坦福大学与 Zillow 研究团队联合推出的 GaussFusion,通过将 3D 重建参数(深度、法线等)渲染成 GP-Buffer 并驱动视频生成模型,完美解决了 3D Gaussian Splatting (3DGS) 中的悬浮物(floaters)和纹理模糊问题。它不仅跨越了“优化式”与“前馈式”重建的鸿沟,更通过模型蒸馏技术达到了 16 FPS 的惊人速度,让高质量 3D 修复变得实时可用。
1. 痛点深挖:为什么 3DGS 的伪影如此难搞?
尽管 3DGS 彻底改变了实时渲染的格局,但在野外(In the wild)场景下,它依然面临三大顽疾:
- 悬浮物 (Floaters):由于相机位姿误差或稀疏观测,空间中会生成莫名其妙的半透明碎片。
- 几何模糊 (Blur):在训练视角覆盖不到的区域,高斯球会过度拉伸(Needle-like),导致视觉崩坏。
- 范式不兼容:现有的修复模型要么只能修“优化出来的”3DGS,要么只能修“预测出来的”3DGS,缺乏一种通用的“整形医生”。
以往的方法如 Difix3D 或 GenFusion 仅依赖 RGB 渲染图进行修复。由于缺乏深度和法线信息,模型往往无法分辨:这是一个真实的物体,还是一个讨厌的悬浮伪影?
2. 核心机制:GP-Buffer 与几何适配器 (GA)
GaussFusion 的核心直觉在于:让生成模型“看到”几何。
GP-Buffer:3D 信念的像素化投影
作者提出了 GP-Buffer,它不只是外观的记录,而是 3D 信息的全景视图:
- 颜色 (C) 与 不透明度 (A):基础外观。
- 深度 (D) 与 法线 (N):显式空间结构。
- 逆协方差 (U):作者的一个天才设计,用来量化局部几何的不确定性。协方差越异常的地方,通常就是伪影所在。
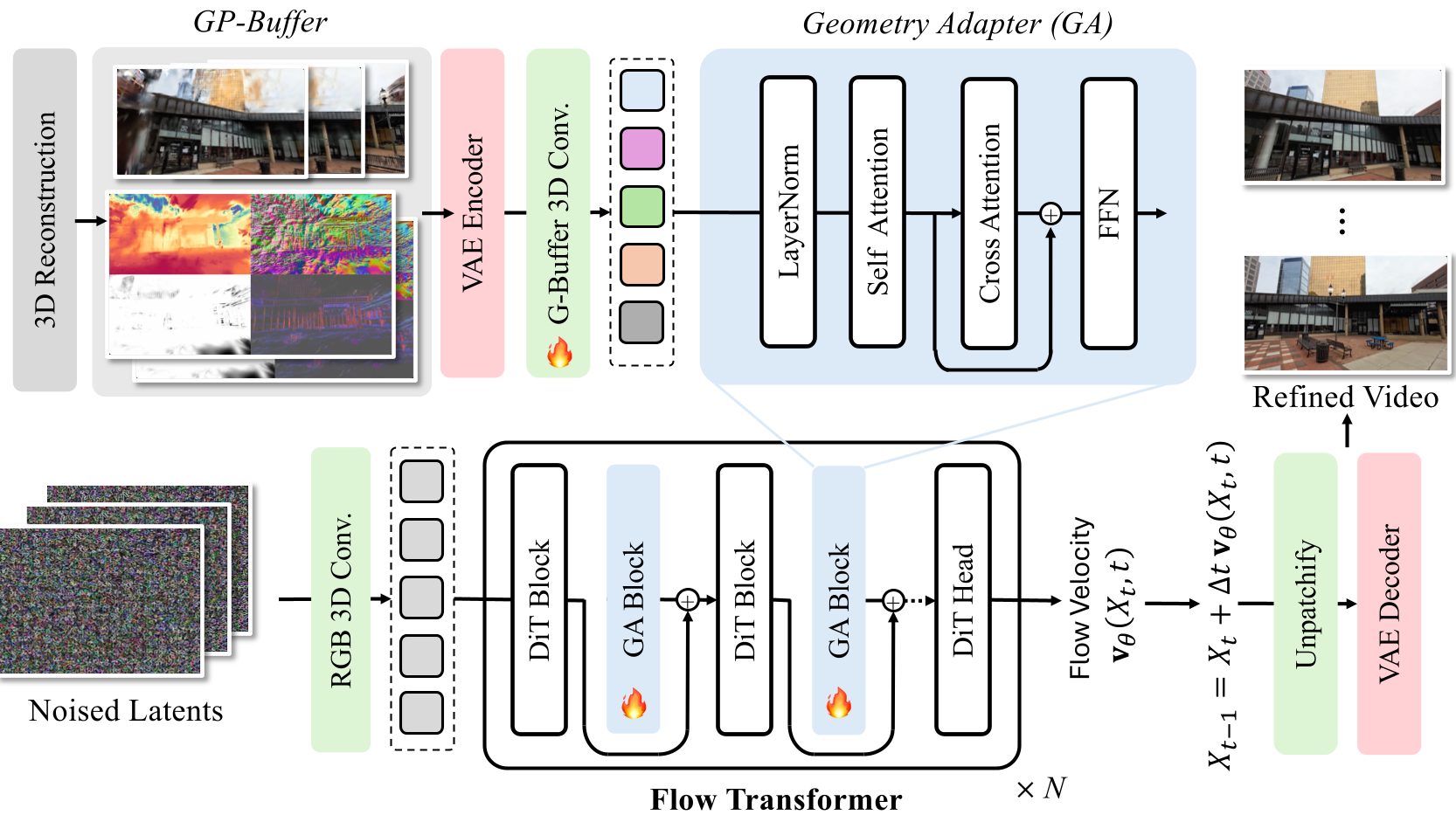 图 1:GaussFusion 架构。GP-Buffer 通过 3D 卷积编码后,经由 Geometry Adapter 注入 DiT 网络。
图 1:GaussFusion 架构。GP-Buffer 通过 3D 卷积编码后,经由 Geometry Adapter 注入 DiT 网络。
Geometry Adapter (GA)
不同于简单的特征相加,GA 模块作为一个侧分支(Parallel side-network),通过交叉注意力机制(Cross-Attention)将几何特征注入预训练的视频生成器(Wan-2.1)。这意味着模型在生成每一帧时,都在不断参考输入的 3D 结构,从而保证了生成的连贯性。
3. 实验战绩:全方位的压制
GaussFusion 在处理极端稀疏视角(仅保留 5% 帧)时展现了惊人的鲁棒性。
- SOTA 对比:在 DL3DV 数据集上,其 PSNR 达到 22.5dB,远超 ExploreGS 和 GenFusion。
- 极致速度:通过 DMD(Distribution Matching Distillation)技术,模型从原本需要 30-50 步的扩散过程压缩到了 4 步。
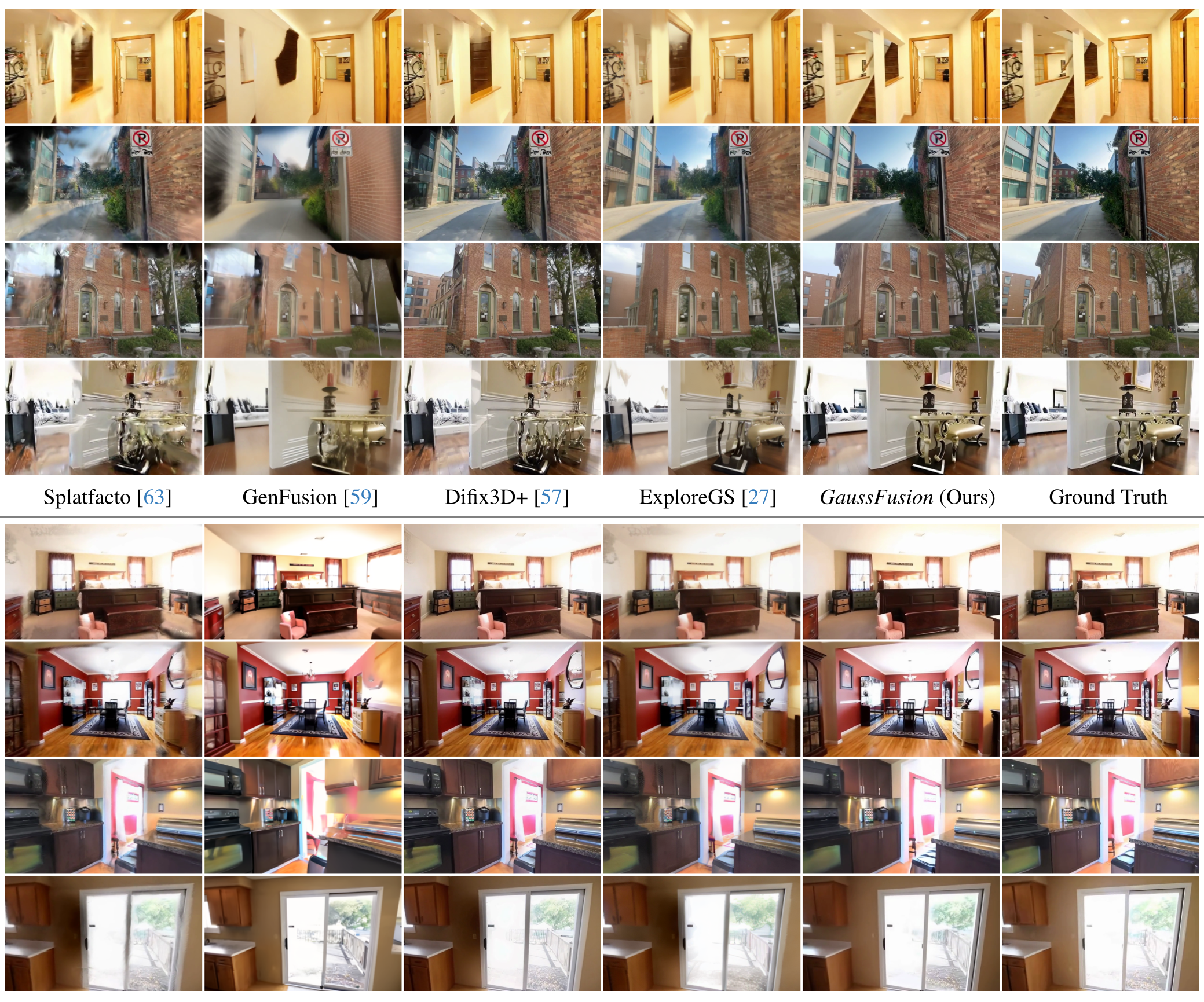 图 2:定性对比。可以看到原始渲染(Noisy)中充满了空洞和模糊,而 GaussFusion 生成的结果(Refined)几乎完美还原了地毯和家具的纹理。
图 2:定性对比。可以看到原始渲染(Noisy)中充满了空洞和模糊,而 GaussFusion 生成的结果(Refined)几乎完美还原了地毯和家具的纹理。
4. 深度洞察:伪影模拟的力量
为什么 GaussFusion 的泛化性这么好?答案在于其伪影模拟管线。 作者并没有简单地加高斯噪声,而是通过操纵 3DGS 的训练过程(如减少优化步数、使用错误的点云初始化、引入前馈模型的偏差等)人为制造出“真实的伪影”。这种“以假乱真”的策略让模型见过各种翻车现场,因此在面对真实世界的复杂数据时表现自如。
5. 局限性与展望
虽然 GaussFusion 在静态场景和常规视角下表现卓越,但在面对剧烈运动模糊或超长视频序列(超过 81 帧)时,仍依赖滑动窗口平衡一致性。未来,如果能实现视频生成模型对 3D 场景参数的在线直接更新(Direct 3D Update),我们将能看到更加梦幻的实时 3D 内容修正。
总结 (Takeaway): GaussFusion 标志着 3D 重建进入了“生成式增强”时代。它不再强求采集阶段的完美,而是通过强大的 AI 后处理,化腐朽为神奇,为 VR/AR 场景的低成本构建开辟了新路径。