本文提出了 F-ACIL(因子感知组合迭代学习),这是一个旨在构建机器人通用数据飞轮的启发式框架。通过将高维机器人数据分解为物体、动作和环境等结构化因子空间,该方法在 Pick-and-Place 和 Open-and-Close 任务中以减少 5-10 倍数据量的代价,实现了超过 45% 的性能提升。
TL;DR
字节跳动 Seed 团队提出了 F-ACIL (Factor-Aware Compositional Iterative Learning),这是一个革新机器人数据收集与训练范式的框架。它通过将复杂的环境分解为“物体、动作、环境”三大因子维度,利用组合泛化的物理直觉,实现了在极少量演示数据(5-10倍缩减)下的高性能泛化,成功率提升 45% 以上。
背景定位:该工作是机器人学习(Robotic Learning)领域中从“盲目 Scaling”转向“结构化效率优化”的高水平突破,为解决真实世界数据采集昂贵问题提供了系统性方案。
痛点深挖:消失的“泛化性”与“维度灾难”
目前大模型驱动的机器人(VLA Models)表现受限于数据覆盖。开发者通常面临两难:
- 高斯分布陷阱:演示数据往往集中在少数常见场景(如固定光照、习惯性动作),形成长尾分布,导致模型一出实验室就“抓瞎”。
- 维度灾难:如果尝试均匀覆盖所有变量(物体种类 x 位置 x 角度 x 光照 x 背景),组合爆炸会导致所需数据量呈指数级增长,现实中根本无法完成。
作者认为:模型不需要见过所有组合,只需要见过关键因子的代表性组合。
核心方法论:F-ACIL 的“拆解”与“重组”
1. 结构化因子分解 (Factorized State Representation)
F-ACIL 将混乱的状态空间 拆解为三个主轴的笛卡尔乘积: 每个轴进一步细化,例如物体被分为:透明度(Texture)、几何形状(Geometry)和尺寸(Size)。
2. 顺序因子扩展与迭代搜索
与其同时在所有维度乱跑,F-ACIL 采用了 O → A → E 的顺序扩张策略。
- 首先在物体空间(O)找到一组能让模型“开窍”的最小子集。
- 固定物体子集,再去动作空间(A)探索。
- 最后加入环境因子(E)。
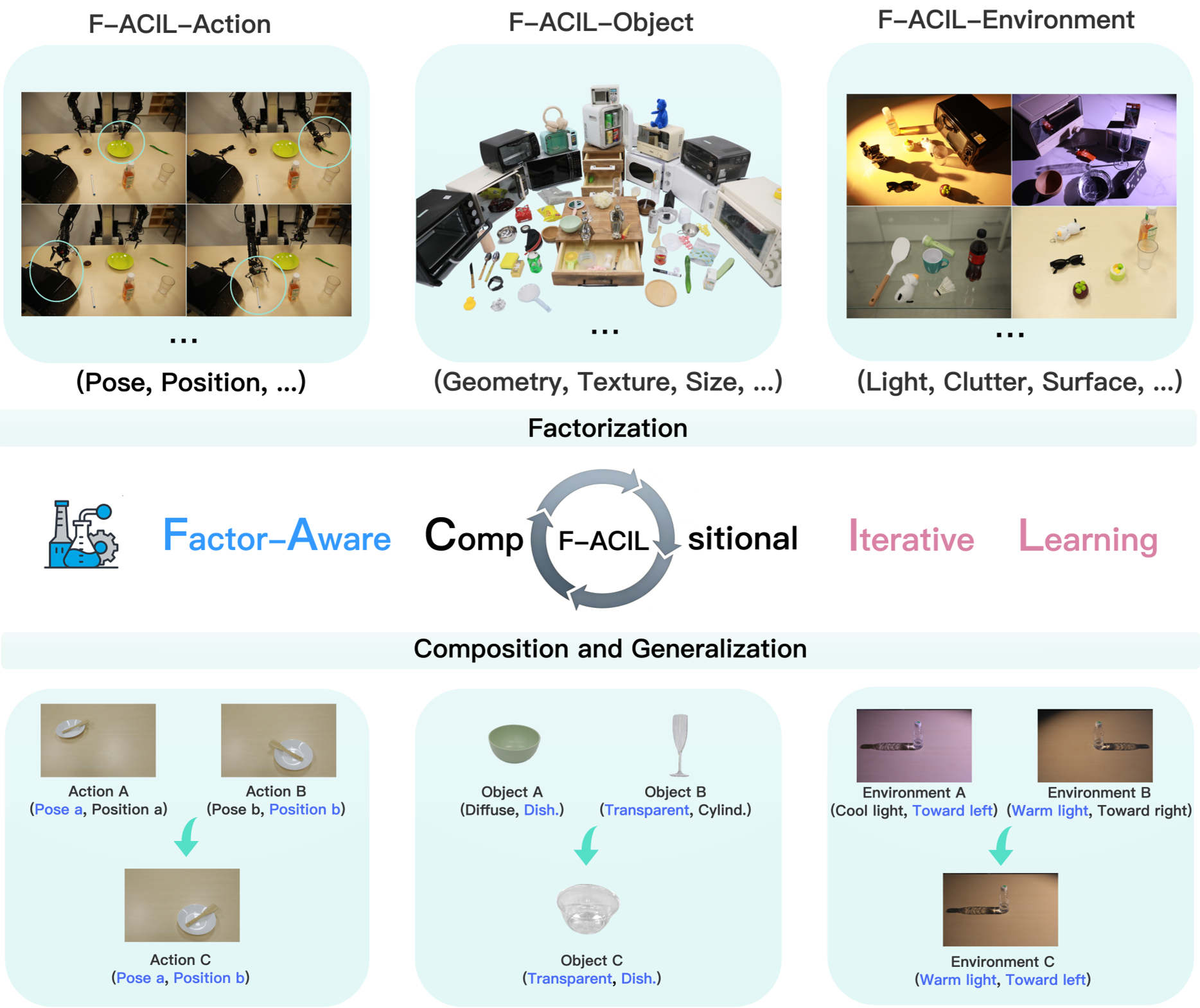
这种“降维打击”的方法,通过算法(Alg 1 & 2)不断寻找模型表现差的因子组合进行定向补课,从而用稀疏的点覆盖住整个连续空间。
实验战绩:效率的降维打击
研究团队在 Pick-and-Place 和 Open-and-Close 两类代表性技能上进行了真实世界验证。
泛化能力的“无损压缩”
实验发现,模型在缩减后的紧凑子集 上训练后,其在全乘积空间 OA 上的表现几乎没有衰减(见下图左)。这意味着:只要找对了个别“模范生”组合,模型就能举一反三。
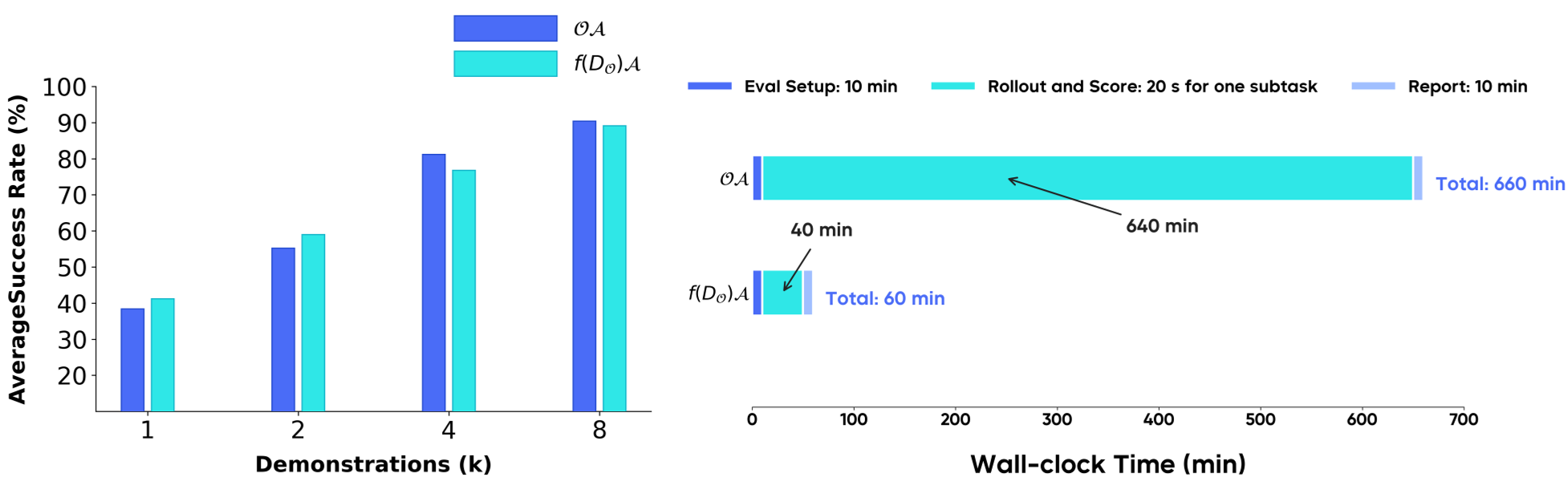
数据效率对比
- F-ACIL vs. Gaussian Baseline:在相同 45% 的成功率提升下,F-ACIL 仅需 2k-4k 数据,而基线需要超过 32k 数据。
- 数据飞轮提速:由于评估路径缩短,单次迭代速度提升了 16 倍。
深度洞察:为什么有效?
F-ACIL 成功的本质在于 Inductive Bias(归纳偏置) 的正确引入。
- 物理独立性:生活中的物体形状和光照方向往往是物理独立的。模型如果学到了“如何抓透明物”和“如何向左平移”,它自然应该能组合出“向左平移抓透明物”。
- 动态修正:通过
S 轴张量计算,算法能精准定位模型最弱的组合点,避免了垃圾数据的无效堆砌。
总结与展望
F-ACIL 证明了机器人学习不需要无穷无尽的“大数据”,而是需要“对的数据结构”。 局限性:目前的因子划分(如纹理、几何)仍带有一定的人为先验,未来若能通过自动化的视觉模型(如使用 VLM 自动打标签)进行无监督因子发现,该飞轮将更加自动化。
对于未来的 VLA 模型开发者来说,本文提供了一个明确信号:与其雇佣更多人去录 Demo,不如花精力设计一套科学的“因子采样策略”。