The paper introduces VEGA-3D (Video Extracted Generative Awareness), a plug-and-play framework that repurposes pre-trained video diffusion models as "Latent World Simulators" to provide 3D spatial priors for Multimodal Large Language Models (MLLMs). By extracting spatiotemporal features from intermediate denoising stages of models like Wan2.1, it achieves SOTA performance on 3D scene understanding, spatial reasoning, and embodied AI benchmarks.
TL;DR
Researchers from HUST and Baidu have discovered that video generation models (like Wan2.1) are "secret" experts in 3D geometry. They introduced VEGA-3D, a framework that treats these generators as Latent World Simulators. By plugging generative features into MLLMs, they fixed "spatial blindness" in AI—enabling models to understand distance, direction, and physical layouts without ever seeing a single piece of explicit 3D data (like LiDAR).
The Problem: Why Your AI is "Spatially Blind"
Most AI models today use encoders like CLIP or SigLIP. These are great at recognizing what is in an image (e.g., "a chair"), but terrible at knowing where it is in 3D space or how it relates to other objects.
Previous attempts to fix this relied on:
- Explicit 3D Data: Expensive and hard to collect.
- Geometric Scaffolding: Lifting 2D to 3D via complex math that often fails in the real world.
The authors of VEGA-3D propose a different path: What if we use the physics already learned by video generators? To generate a video of a moving car, a model must understand occlusion and depth, or the car would look like a flickering ghost.
Methodology: Repurposing the Generator
VEGA-3D operates on the principle that Diffusion Transformers (DiT) maintain high multi-view consistency.
1. The Latent World Simulator
Instead of just using the final image, the model injects noise into a video latent and watches as the DiT tries to "denoise" it. The intermediate representations (specifically at around 30% noise) contain the richest geometric information.
2. Adaptive Gated Fusion
Generative features (physics) and semantic features (labels) are different. VEGA-3D uses a token-level gate to decide, for every part of the image, whether to listen to the "Physics Expert" (the generator) or the "Label Expert" (the discriminative encoder).
 Fig. 1: The VEGA-3D architecture showing the dual-branch visual encoding and the gated fusion mechanism.
Fig. 1: The VEGA-3D architecture showing the dual-branch visual encoding and the gated fusion mechanism.
Experiments: Breaking the SOTA
The results are striking across three major domains:
- 3D Scene Understanding: Massive gains in ScanRefer and ScanQA. The model is much better at answering questions like "Is the table to my front-left?"
- Spatial Reasoning: Outperformed proprietary models like GPT-4o on the VSI-Bench, which tests things like "Appearance Order" and "Relative Distance."
- Embodied AI: In robotic manipulation (LIBERO), adding these priors helped the robot interact with objects more reliably.
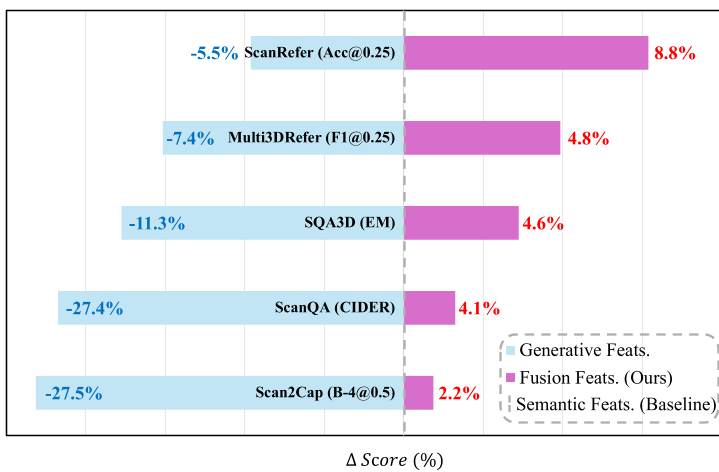 Fig. 2: Quantitative evidence showing the positive correlation between multi-view consistency and downstream reasoning performance.
Fig. 2: Quantitative evidence showing the positive correlation between multi-view consistency and downstream reasoning performance.
Key Insight: The "DiT" Advantage
A fascinating finding in the paper is that Transformers (DiT) beat UNets for 3D priors. Conventional UNet-based video models (like SVD) have a local "bias"—they focus on nearby pixels. DiT models use global attention, allowing them to link a 3D point from Frame 1 to Frame 32 with nearly 96% consistency.
Conclusion & Future Work
VEGA-3D proves that we don't necessarily need more 3D labels to build "AI that understands the world." Instead, we can harvest the physical laws already captured in the billions of parameters of video generators.
Limitations: The main drawback is the increased inference cost of running a heavy diffusion backbone. However, as the authors suggest, the next step is distillation—shrinking these powerful 3D priors into tiny, efficient encoders that can run on a robot's local hardware.
Takeaway: If you want your model to understand space, stop giving it more photos—start giving it a sense of "World Physics" through video generation.