The paper introduces Generative Control as Optimization (GeCO), a time-unconditional flow matching framework that treats robotic action synthesis as iterative optimization over a stationary velocity field. By replacing rigid integration schedules with an adaptive convergence-based process, GeCO achieves SOTA performance on benchmarks like LIBERO and VLABench while being a plug-and-play replacement for VLA model heads.
TL;DR
Current robotic policies based on diffusion or flow matching are "computationally blind"—they spend the same amount of time thinking about moving an arm through empty space as they do performing surgery-level threading. GeCO (Generative Control as Optimization) breaks this by removing "time" from the generative equation. By learning a stationary velocity field where expert actions are stable attractors, GeCO allows the robot to "early exit" from simple tasks and "deliberate" on complex ones, while using the math of the field itself to detect when it's in a dangerous, unknown situation (OOD).
The Motivation: Why "Time" is a Burden for Robots
In standard Flow Matching or Diffusion, we learn a field . The variable acts as a "fictitious clock" that guides the denoising process from noise to action. This creates three critical failures:
- Inflexible Budgets: You must integrate from to . Stopping at gives you a half-baked, noisy action.
- Computational Waste: The model performs 20-50 forward passes regardless of whether the answer was obvious after step 2.
- Ghostly Geometry: Since the field changes at every , there is no single "potential well." You can't ask the model, "How sure are you about this action?" because the landscape is constantly shifting.
 Figure 1: GeCO vs. Standard Flow Matching. GeCO moves from a rigid time-schedule (top) to a stationary attractor landscape (bottom).
Figure 1: GeCO vs. Standard Flow Matching. GeCO moves from a rigid time-schedule (top) to a stationary attractor landscape (bottom).
Methodology: Generative Control as Optimization
GeCO's core insight is to learn a stationary velocity field .
1. Velocity Rescaling
To make this work, the authors introduced a rescaling schedule that decays to zero as the action approaches the expert data . This transforms the training objective so that ground-truth actions become stationary equilibrium points. If the robot is already at a good action, the velocity is zero.
2. Adaptive Inference
Instead of an ODE solver, GeCO uses gradient descent: Because the field is stationary, we can stop the moment . In a simple "reach" task, the robot might reach consensus in 3 steps. In a complex "nut assembly" task, it might take the full 30 steps to refine the alignment.
3. Intrinsic OOD Detection
This is perhaps the most elegant part. If the robot sees an observation it has never seen before (e.g., a hand blocking the camera), the learned field will be chaotic. The optimization will fail to find an equilibrium where the velocity vanishes. By measuring the "Final Residual Norm," the robot can autonomously decide: "I don't know what to do here; I should stop for safety."
Experimental Breakthroughs
The authors tested GeCO on the series (state-of-the-art Vision-Language-Action models) and physical hardware.
Efficiency vs. Performance
On the LIBERO benchmark, GeCO achieves higher success rates with 75% less computation than standard Rectified Flow. The "Computation Follows Complexity" analysis showed that NFE (Number of Function Evaluations) spikes exactly during bottleneck phases like grasping or object insertion, while remaining low during transit.
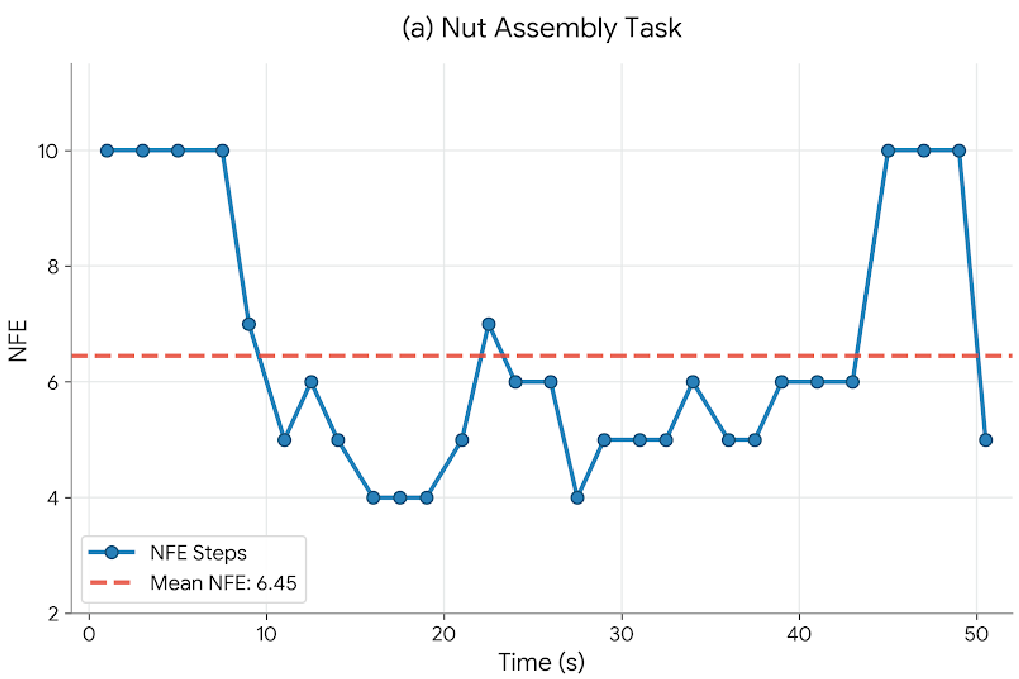 Figure 2: Real-time NFE allocation. Notice how the "compute" (purple bars) spikes during the precision-assembly phase.
Figure 2: Real-time NFE allocation. Notice how the "compute" (purple bars) spikes during the precision-assembly phase.
Real-World Precision
In physical "Nut Assembly" tasks requiring millimeter-level precision, a standard VLA model (G0 Plus) failed 90% of the time because its fixed 10-step schedule couldn't resolve the tight tolerances. GeCO, using the same backbone but an adaptive refinement, achieved a 70% success rate.
Critical Analysis & Future Outlook
GeCO represents a significant shift toward "System 2" thinking in robotics—where the model can choose to "ponder" more on difficult problems.
Limitations: While the optimization is intuitive, the paper's convergence guarantees are empirical. The Lipschitz constant of the field (controlled by hyperparameter ) is a delicate balance; if the field is too "sharp," optimization becomes unstable.
Conclusion: GeCO is a rare "win-win-win" in AI research. It is more efficient, more accurate, and inherently safer. By treating action generation as a journey toward an attractor rather than a race against a clock, we move closer to robots that can handle the nuanced complexities of the real world.