本文提出了 GenericAgent (GA),一种通用的自我演化大模型智能体系统。其核心贡献是提出了“上下文信息密度最大化”原则,通过极简工具集、分层记忆和自动化 SOP 蒸馏,在保持 SOTA 性能的同时显著降低了 Token 消耗。
TL;DR
在学术界追求“无限上下文”的当下,A3 Lab 的这篇论文反其道而行之:GenericAgent (GA) 证明了与其增大上下文窗口,不如提高单位 Token 的“决策密度”。它通过极简的 9 个原子工具、分层的记忆架构以及将成功经验“代码化”的演化机制,在大幅降低成本的同时,刷爆了多个长程任务基准。
背景定位:从“大力出奇迹”到“精细化运营”
当前的 LLM Agent(如 Claude Code, OpenClaw)普遍面临一个悖论:为了解决复杂问题,系统必须输入大量的 API 说明和历史日志;但这些冗余信息会触发 LLM 的“Lost in the Middle”效应,导致决策质量下降。GA 的出现标志着智能体设计从单纯依赖模型窗口,转向系统级的上下文工程(Context Engineering)。
痛点深挖:为什么你的智能体越跑越笨?
作者指出,长程任务失败的核心并非窗口不够大,而是:
- 注意力分散:无关的 HTML 标签、重复的思考过程占用了有限的有效注意力。
- 经验耗散:上一个任务踩过的坑,在下一个任务里还要重新踩一遍,Token 支出线性增长,能力却原地踏步。
- 工具膨胀:过多的专门化工具(如单独的搜索、过滤、匹配工具)增加了模型的决策熵值。
核心机制:信息密度最大化的四板斧
1. 极简原子工具集 (Tool Minimality)
GA 仅提供 9 个核心原子工具(如 file_read, code_run, web_scan)。
- 逻辑直觉:复杂的行为通过这些基础原子的“组合(Composition)”产生。这不仅减少了 Prompt 开销,更降低了模型因工具过多而产生误判的概率。
2. 四层分层记忆 (Hierarchical Memory)
记忆被划分为 L1(索引)、L2(事实)、L3(SOP)、L4(原始存档)。
- 原理:默认只在主 Context 中保留 L1 索引,模型只有在推断需要时,才会通过工具调用去拉取 L2/L3 的深度信息。这种“按需加载”保证了主内存的纯净性。
3. 从 SOP 到代码的自我演化 (Self-Evolution)
这是 GA 最具创新性的部分。当智能体通过试错成功完成任务后,它会触发“反射(Reflection)”机制:
- 将零散的交互轨迹压缩为执行 SOP。
- 进一步将 SOP 编译为可直接运行的 Python 代码。
- 效果:后续遇到类似任务,智能体不再反复推理,而是直接调用“技能代码”,Token 消耗呈指数级下降。
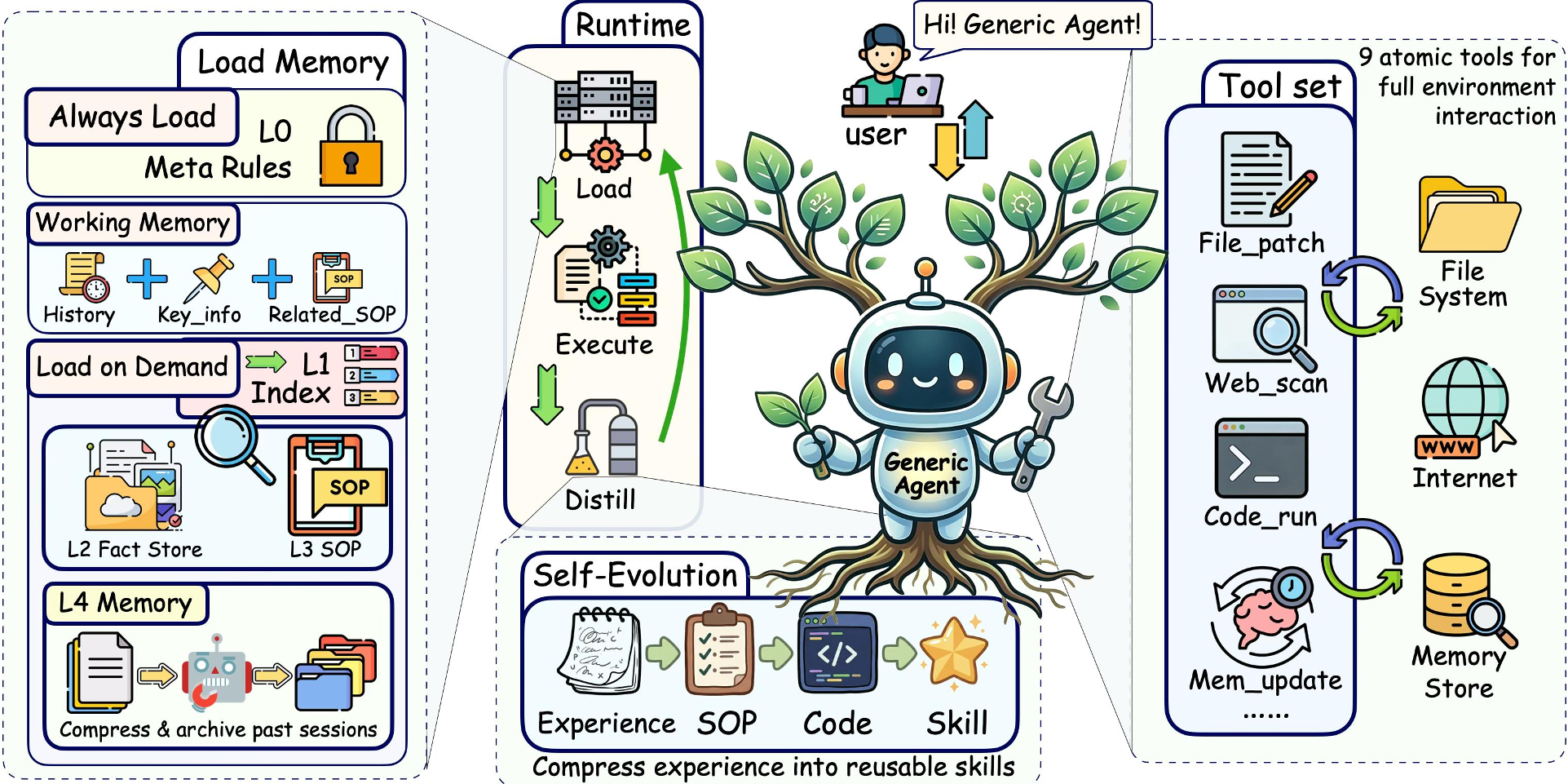
4. 上下文截断与压缩 (Truncation & Compression)
GA 引入了多级压缩方案:从工具输出的首尾截断,到针对历史消息中 XML 标签的“按需擦除”,确保上下文窗口严格服务于当前决策。
实验战绩:效率与性能的双重碾压
在 Lifelong AgentBench 等测试中,GA 表现出了惊人的收敛效率。
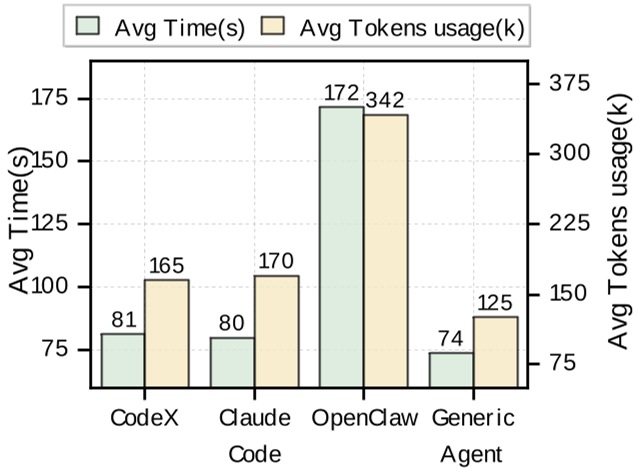
- 准确率:在多个 benchmark 上达到 100% 准确率。
- 成本优势:在反复执行同一类任务时,GA 的运行时长减少了 78.2%,Token 成本减少了 89.6%。相比之下,传统的 OpenClaw 往往在重复任务中依然维持高昂的 Token 支出。
深度洞察:智能体未来的样子
GA 给了我们一个深刻的启示:权限定义上限,而架构控制落地。
- Token 消耗不等于思考深度:在 Agent 领域,消耗 Token 越多往往意味着上下文管理越失败。
- 架构极简主义:GA 的核心代码仅 3300 行,智能体甚至能理解并修改自己的源代码。这种极简性是通往“架构级自进化”的入场券。
总结
GenericAgent 不是在堆砌功能,而是在做减法。它通过系统级的设计,将大模型从廉价的文本生成中解放出来,使其真正像一个经验丰富、懂得“精打细算”的专家。对于需要长期运行、实时响应且对成本敏感的企业级分布式 Agent 系统,GA 提供了一套极具说服力的标准化范式。
局限性注记:目前 GA 的自进化日志还部分依赖人工校验(Manual Curation),且对 CJK 字符的 Token 估算存在偏差。未来如何实现完全闭环的自评价演化,将是该路径的核心挑战。