GenMask is a novel framework that adapts Diffusion Transformers (DiT) for segmentation by treating mask generation as a direct conditional generation task. By unifying image generation and segmentation under a single generative objective, GenMask achieves state-of-the-art performance on RefCOCO (83.3% oIoU) and ReasonSeg benchmarks while maintaining the original DiT architecture.
TL;DR
Forget complex feature extraction pipelines for diffusion-based segmentation. GenMask demonstrates that a Diffusion Transformer (DiT) can learn to "generate" black-and-white masks just as easily as it generates colorful RGB images. By treating segmentation as a direct conditional generation task and using a specialized high-noise sampling strategy, GenMask achieves SOTA results (83.3% oIoU on RefCOCO) without changing a single parameter in the original DiT backbone.
Background: The "Implicit" Bottleneck
To date, using Diffusion Models for segmentation has been an exercise in "feature mining." Researchers would take a frozen Stable Diffusion model, run a denoising loop, extract intermediate activations, and hook them up to a separate decoder. This is problematic because:
- Representation Mismatch: Diffusion models care about textures; segmentation cares about boundaries and labels.
- Pipeline Complexity: Operations like "diffusion inversion" are slow and cumbersome for real-time segmentation.
GenMask asks: Why not just train the DiT to output the mask directly?
Methodology: Bridging the LDM-Mask Gap
1. The Geometry of Masks
The core discovery of GenMask is the "robustness" of binary masks in the VAE latent space. Unlike natural images, which turn into unrecognizable static with high noise, binary masks maintain their global structure even at extreme noise levels.
Mathematically, the authors found that VAE representations of masks are linearly separable. Applying PCA to mask latents reveals that the first principal component almost perfectly reconstructs the original mask.

2. Time-Shift Sampling
To train a single DiT to handle both RGB images and binary masks, GenMask employs two distinct sampling schedules:
- Generation: Uses logit-normal sampling, focusing on intermediate noise levels where fine details are formed.
- Segmentation: Uses an extreme long-tailed distribution. Since masks are so robust, the model only learns meaningful "labeling" logic when the noise is high enough to challenge the linear separability. 90% of segmentation training happens at $t > 0.85$.
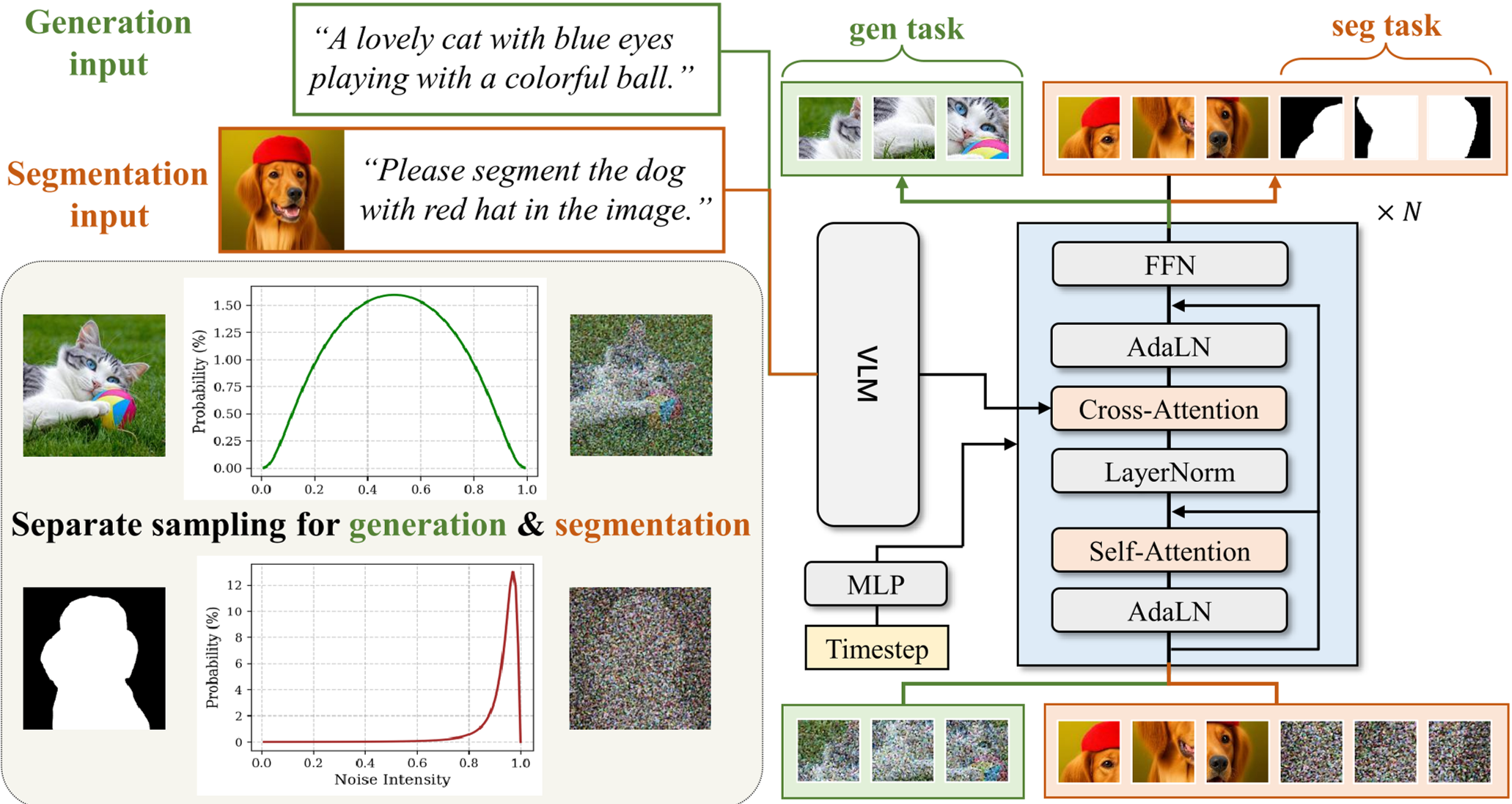
3. Architecture: VLM + DiT
The system uses Qwen2.5-VL as an instruction encoder. To ensure the DiT doesn't lose spatial precision (since VLMs are high-level), the authors inject a "VAE shortcut"—the latent representation of the input image—concatenated with the noise.
Experiments: SOTA Achievement
GenMask doesn't just simplify the architecture; it wins on performance. On the RefCOCO series, it consistently beats specialized "LMM-Segmentation" models like LISA.
| Method | RefCOCO (oIoU) | RefCOCO+ (oIoU) | RefCOCO-g (oIoU) | | :--- | :--- | :--- | :--- | | LISA | 79.1 | 70.8 | 67.9 | | GLaMM | 83.2 | 78.7 | 74.2 | | GenMask (Ours) | 83.3 | 78.7 | 75.6 |
Key Insights from Ablation Studies:
- One-Step Inference: Because the model is trained on extreme noise, it can generate a mask in a single forward pass (t=1). It doesn't need the iterative denoising required for images.
- Joint Training: Mixing in text-to-image generation data actually improves segmentation performance, suggesting that the "creative" capacity of the model aids its "understanding" of object boundaries.

Critical Analysis & Future Work
GenMask represents a significant shift toward Generative Unified Models. By removing the need for a separate "segmentation head," we move closer to a world where "Vision-Language-Action" models use the same weights for everything.
Limitations:
- Currently relies on a frozen VAE. If the VAE hasn't seen specific unusual mask shapes, the reconstruction might be slightly blurred.
- Computationally heavy: Using a 7B VLM + 1.3B DiT for simple segmentation is "overkill" compared to a ResNet-based U-Net, though necessary for high-level reasoning.
Conclusion: GenMask proves that the "Optimization Gap" between generative pretraining and discriminative adaptation is a choice, not a necessity. By aligning the task format to the generative objective, we unlock the full power of Diffusion Transformers.