本文提出了 GenMask,一种将分割任务直接转化为生成任务的 DiT 适配方法。该方法通过在 RGB 空间直接生成黑白掩码,并在 RefCOCO 和 ReasonSeg 等多个基准测试上取得了 SOTA 性能,实现了生成与分割任务的统一训练。
TL;DR
在视觉感知领域,长期以来分割(Segmentation)被视为判别任务,而扩散模型(Diffusion)被视为生成任务。传统做法是“借用”扩散模型的特征。GenMask 提出了一种截然不同的思路:为什么不直接让 DiT 把分割掩码“画”出来?
该工作证明,只需通过调整噪声采样策略和引入简单的 VAE Shortcut,原生的 DiT 架构即可在不改变参数结构的前提下,通过标准的生成训练目标达成 SOTA 级别的分割精度。
1. 痛点:为什么“借用”特征不是最优解?
目前利用生成模型(如 Stable Diffusion)做分割的主流范式是 Feature Extraction:
- 冻结扩散模型,输入图像,提取中间层的特征。
- 设计一个复杂的 Decoder,将这些隐藏特征映射回分割掩码。
这种方式存在两个致命陷阱:
- 表示错位:生成模型预训练是为了建模像素细节和纹理,而分割需要的是紧凑的、语义级别的预测。
- Pipeline 臃肿:频繁的特征反转(Inversion)或多步骤激活聚合极其耗时,且无法充分利用生成模型的优化梯度。
2. 核心直觉:掩码与图像的 Latent 差异
GenMask 的作者发现了一个非常有趣的物理直觉:二值掩码(Binary Mask)在 VAE 空间中极度稳健。

如上图所示,当对自然图像加入极高噪声时,内容会迅速崩塌变成噪点;但对于二值掩码,即便在高噪声下,物体的轮廓和位置依然依稀可见。通过 PCA 分析发现,掩码在 VAE Latent 空间中几乎是线性可分的。
Insight:既然掩码在高噪声下如此稳定,我们就可以在训练时让分割任务集中在“极高噪声”区域,而让正常的图像生成负责“中低噪声”区域。
3. 方法论:统一生成的 GenMask
GenMask 基于 WAN-2.1 的 DiT 架构,其核心改动在于以下三点:
3.1 架构:保持原汁原味
模型由一个 VLM(Qwen2.5-VL)作为指令编码器,DiT 作为主干网络。为了补足像素级的纹理细节,作者引入了输入图像的 VAE Latent 作为 Low-level Shortcut。
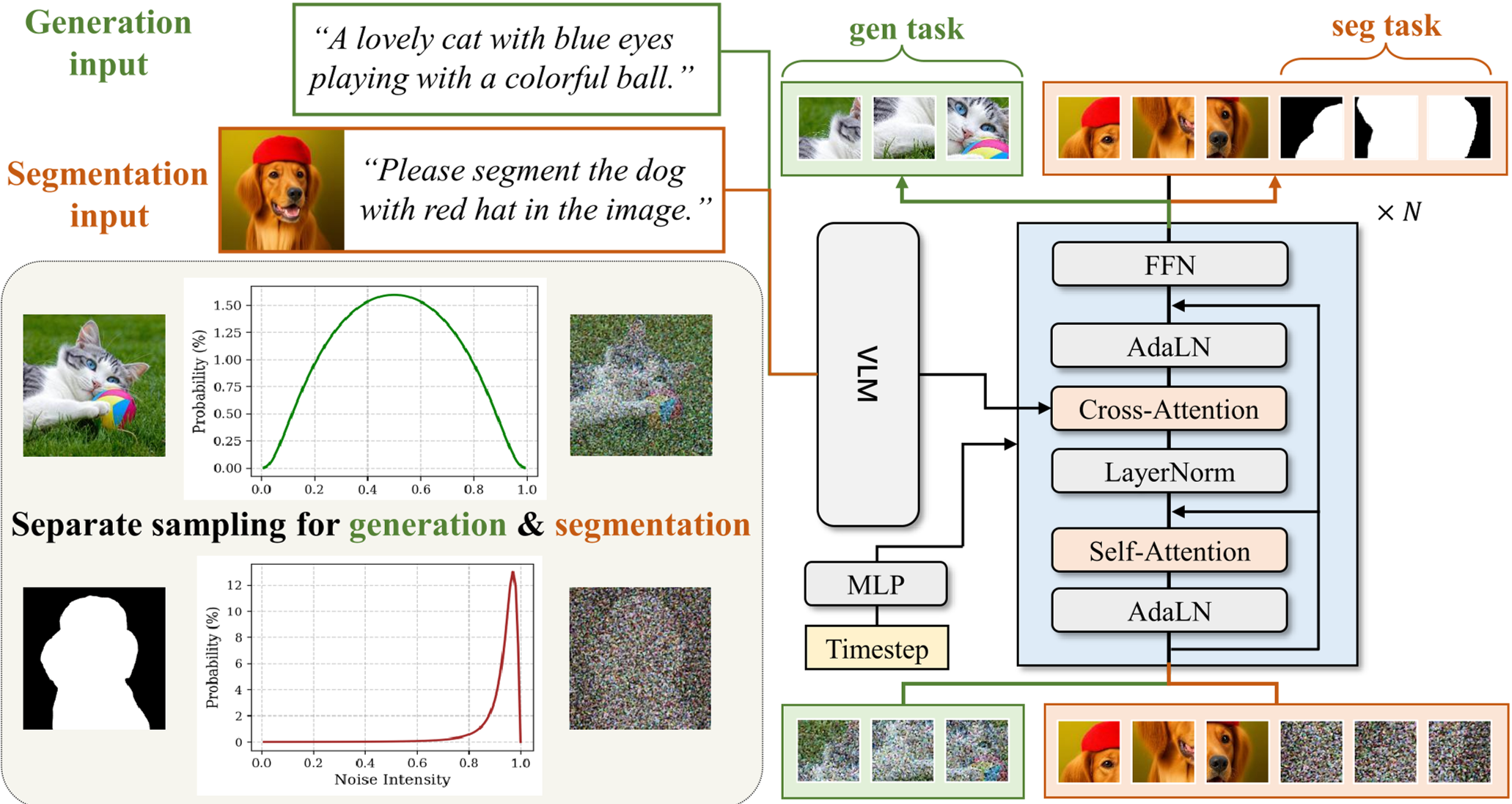
3.2 采样:极端长尾的时间步策略
这是本文最精妙的设计。传统生成任务偏好中间段噪声(中间段提供的学习信号最强),但 GenMask 为分割任务设计了一个极端长尾分布:
- 90% 的样本集中在高噪声区域()。
- 这种采样策略让模型学会了在极度模糊的信息中“找轮廓”。
3.3 推理:单步直达
由于模型在极高噪声下训练得非常充分,推理时根本不需要像生成图像那样进行多步 Denoising。设置 ,一次 Forward Pass 就能直接输出掩码,速度与传统判别模型齐平。
4. 实验表现:SOTA 与可视化展示
GenMask 在 RefCOCO 系列和 ReasonSeg 挑战赛上展现了统治力。
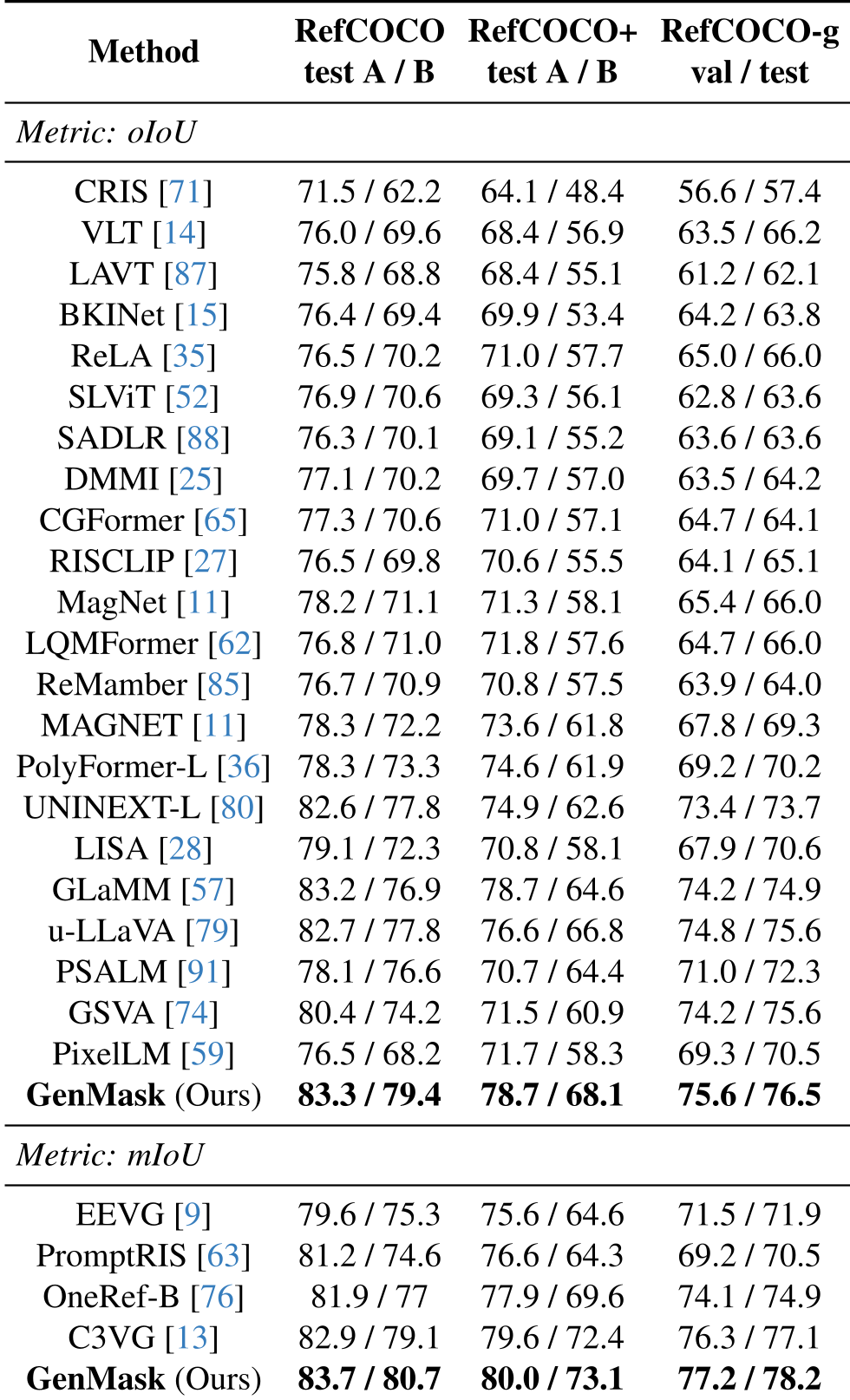
- 性能:在 RefCOCO-g 基准上,GenMask 相比之前的 LISA 等 LLM-based 分割模型,oIoU 提升了 5-6 个点。
- 混合训练:将生成数据与分割数据按 1:1 比例混合训练,能显著提升分割任务的泛化能力。
可视化案例
无论是简单的物体指代,还是涉及“胡须男做滑稽动作”这类复杂的推理分割,GenMask 都能精准锁死目标。

5. 总结与深度洞察
GenMask 成功地将分割适配简化为了一个特殊的“图像生成”子任务。这种范式转变(Paradigm Shift)带来几个启发:
- 归纳偏置(Inductive Bias)仍然重要:尽管是通用架构,但针对掩码特性调整噪声采样频率是成功的关键。
- 大模型的潜力:预训练的视频/图像生成模型蕴含的几何理解能力远超我们想象。
局限性:尽管目前在静态图像上表现卓越,但对于视频中的时序一致性分割,GenMask 是否能保持同样的确定性仍需进一步验证。
关键词:GenMask, Diffusion Transformer, Segmentation, SOTA, Rectified Flow.