GeoSR is a vision-language framework designed to enhance 3D spatial reasoning in both static and dynamic scenes. It achieves state-of-the-art performance by introducing "Geometry-Unleashing Masking" and "Geometry-Guided Fusion" to ensure that injected geometry tokens from 3D foundation models are actively utilized rather than ignored.
Executive Summary
TL;DR: Modern Vision-Language Models (VLMs) are surprisingly bad at understanding "where" things are in 3D space, often getting distracted by 2D appearance. GeoSR addresses this by forcing models to stop taking shortcuts. By masking 2D visual tokens and using a smart "Geometry-Guided Fusion" gate, GeoSR ensures that 3D structural information becomes the primary driver for spatial reasoning, leading to a massive +7.2% jump in dynamic spatial reasoning SOTA.
Background: This work moves beyond simple "token injection" to "active reasoning." It shifts the paradigm from just giving the model more data to ensuring the model actually knows how to use that data for 3D and 4D (spatiotemporal) tasks.
The Problem: The "Appearance Shortcut" Trap
The research team observed a frustrating phenomenon: adding geometry tokens to a VLM often does... nothing. In some dynamic video cases, it actually makes the model worse.
Why? Because VLMs are "lazy." They prefer 2D appearance shortcuts (e.g., "the object looks smaller, so it might be further") over complex 3D geometric calculations. If the 2D visual tokens are enough to guess an answer during training, the model ignores the expensive 3D geometry tokens entirely.
Methodology: Forcing the VLM to Think in 3D
GeoSR fixes this with a two-pronged attack:
1. Geometry-Unleashing Masking
To break the reliance on 2D shortcuts, GeoSR strategically masks parts of the 2D vision tokens during training.
- In Static Scenes: It uses random masking (MAE-style).
- In Dynamic Scenes: It uses an attention-based "relevance score" to mask the most critical 2D areas, literally forcing the model to look at the geometry stream to "fill in the blanks" for spatial relations.
2. Geometry-Guided Fusion
Instead of just adding or concatenating tokens (naive fusion), GeoSR uses a Gated Routing Mechanism. It calculates a token-wise weight ($\alpha$) that decides—channel by channel—how much the model should lean on visual vs. geometric evidence.
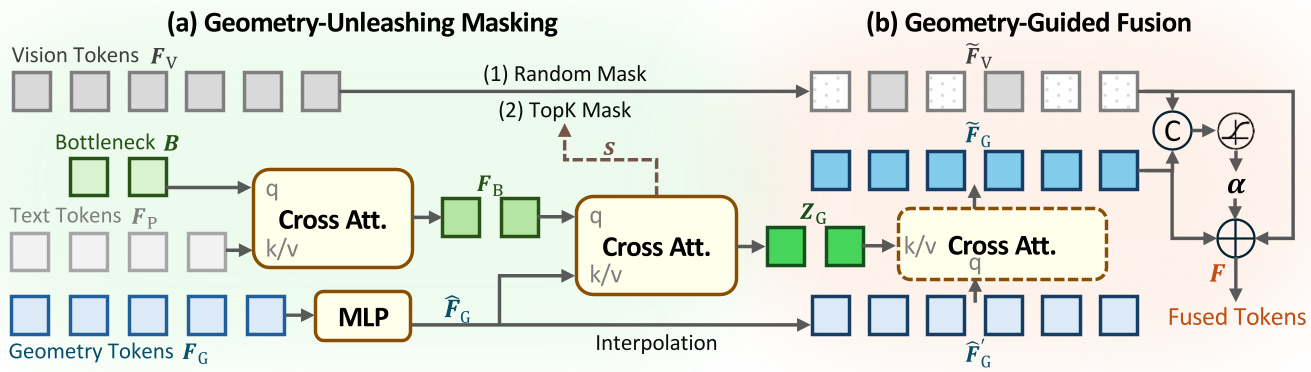 Figure: The GeoSR Architecture illustrating the Masking and Guided Fusion modules.
Figure: The GeoSR Architecture illustrating the Masking and Guided Fusion modules.
Experimental Performance
The experimental results prove that "forcing" the model pays off.
- Static Spatial Reasoning (VSI-Bench): GeoSR hit 51.9%, outperforming GPT-4o (47.8%) and previous specialists like VG-LLM.
- Dynamic Spatial Reasoning (DSR-Bench): This is where GeoSR truly shines. By capturing motion and depth cues through the π3 foundation model, it reached 66.1%, leaving the previous SOTA (GSM at 58.9%) in the dust.
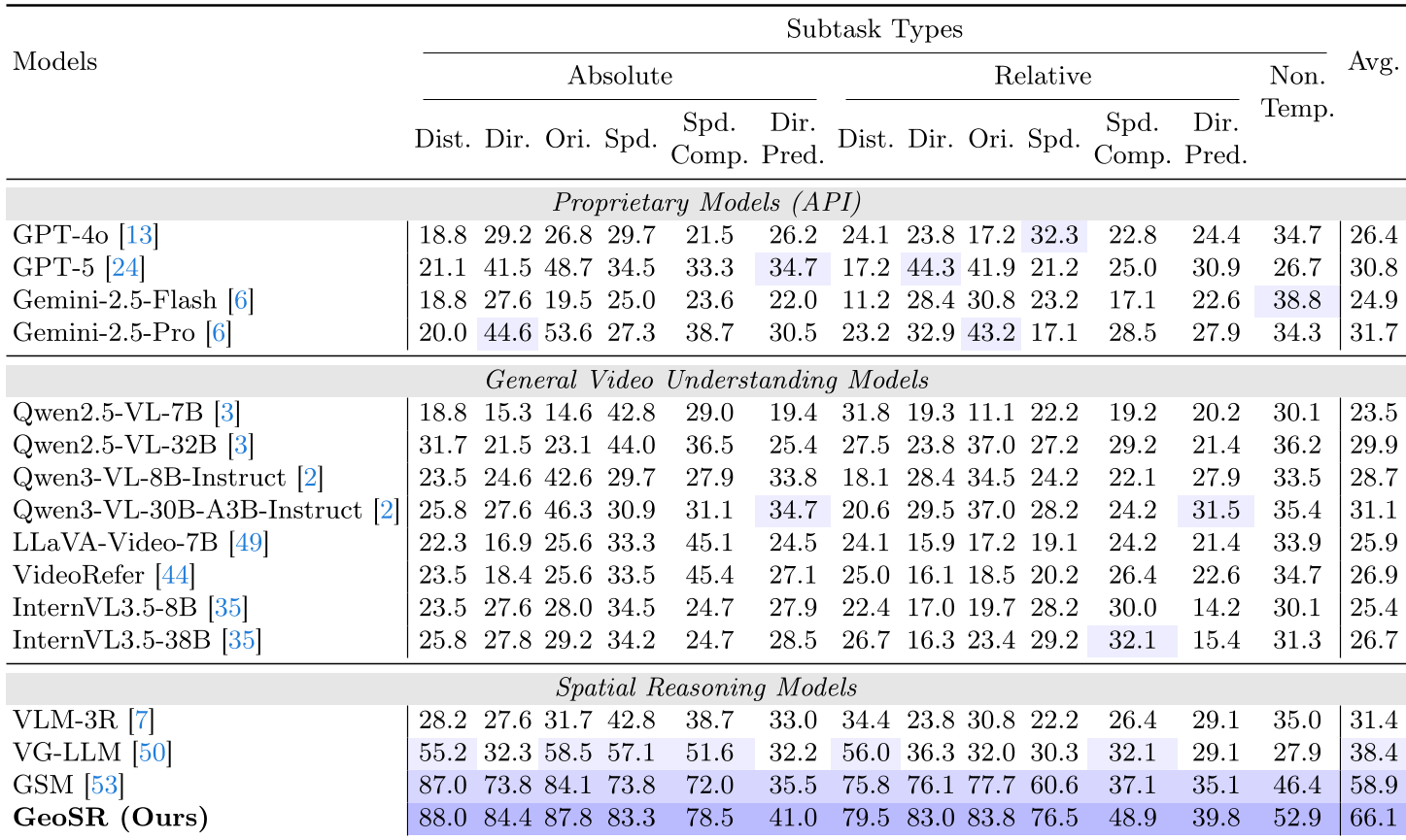 Table: Comparison of GeoSR against General and Spatial Reasoning VLMs on dynamic tasks.
Table: Comparison of GeoSR against General and Spatial Reasoning VLMs on dynamic tasks.
Deep Insight: Why it Works
The "Ablation Study" (Table 3 & 4 in the paper) reveals the secret sauce:
- Without Masking, the model defaults to 2D shortcuts.
- Without Gated Fusion, the geometric signal gets "diluted" by the overwhelming visual signal. Only when combined does the model treat the geometry as actionable evidence.
This suggests that for the next generation of "Embodied AI" or "World Models," simply having a big transformer isn't enough—we need inductive biases that prioritize structural logic over pixel correlation.
Conclusion & Future Outlook
GeoSR demonstrates that geometry can and should matter. While current benchmarks still have some label ambiguity, the framework provides a robust blueprint for integrating 3D foundation models into general-purpose VLMs. The future of AI spatial intelligence lies in this "forced" multi-modal synergy.
For more details, visit the Project Page.