GHOST (Gaussian Hand-Object SplaTting) is a fast, category-agnostic framework designed to reconstruct dynamic bimanual hand-object interactions from monocular RGB videos. It leverages 3D Gaussian Splatting and geometric priors to achieve state-of-the-art (SOTA) 3D accuracy and photorealistic rendering while being over 13x faster than previous methods.
TL;DR
Reconstituting how hands interact with objects in 3D from a single camera is a "Holy Grail" for AR/VR and Robotics. GHOST (Gaussian Hand-Object SplaTting) achieves this by ditching slow NeRF-based optimizations in favor of 3D Gaussian Splatting. By retrieving geometric "priors" from the cloud and using a smart "grasp-aware" alignment, GHOST delivers physically consistent, animatable 3D reconstructions 13 times faster than previous state-of-the-art methods.
The Problem: The Occlusion Nightmare
When you pick up a mug, your fingers hide parts of the mug, and the mug hides parts of your fingers. For a computer trying to "see" this in 3D from a 2D video, this is a nightmare.
- Scale Ambiguity: How big is the object relative to the hand?
- Missing Geometry: How do we reconstruct the back of the object we never see?
- Computational Cost: Previous category-agnostic methods (which don't need to know the object type beforehand) take up to 16 hours to process a single short clip.
Methodology: How GHOST Works
GHOST attacks these problems with a structured three-stage pipeline that elevates "raw" video into a high-fidelity 3D interaction.
1. Geometric Prior Retrieval
Instead of guessing what the hidden side of a box looks like, GHOST uses a Vision-Language Model (InternVL) to describe the object. It then searches the Objaverse (a massive 3D model database) to find a similar shape to act as a "guide" or prior.
2. Grasp-Aware Alignment
The system detects when a hand is actually "grasping" by measuring the correlation between hand and object motion. During these frames, it applies a Contact Loss, forcing the hand and object into a physically plausible alignment.
3. Joint Gaussian Optimization
This is where the magic happens. GHOST represents both the object and the hand as thousands of tiny 3D Gaussian discs.
- Hand-aware Background Loss: Prevents the system from "erasing" parts of the object that are currently hidden behind fingers.
- Geometric Consistency: Uses the retrieved 3D prior to "fill in the blanks" for occluded regions.
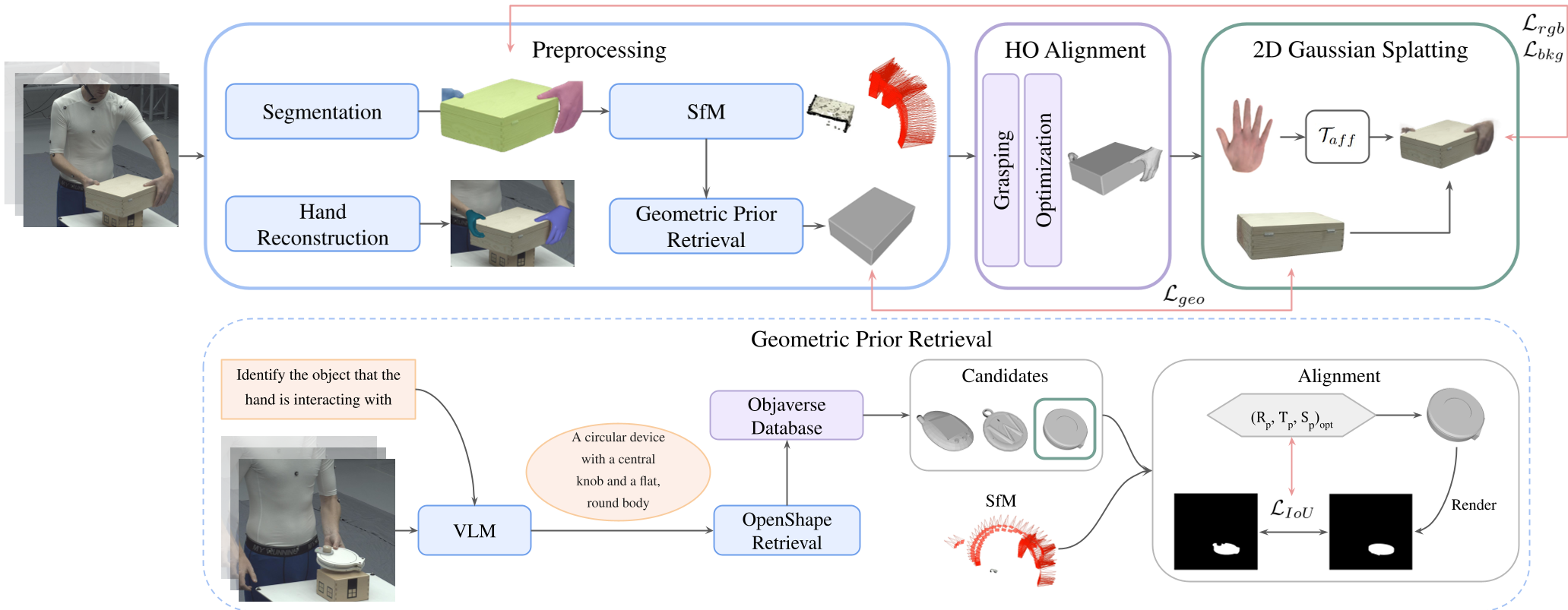 Figure: The GHOST pipeline—from prior retrieval to grasp-aware alignment and final Gaussian Splatting.
Figure: The GHOST pipeline—from prior retrieval to grasp-aware alignment and final Gaussian Splatting.
Experiments: SOTA Speed and Accuracy
The researchers tested GHOST on the ARCTIC and HO3D datasets. The results were clear:
- Interaction Quality: GHOST achieved nearly double the accuracy in hand-object distance metrics (CDr/CDl) compared to previous methods.
- Rendering: The 2D visual quality (PSNR) jumped from ~12.8 in HOLD to 25.93.
- Efficiency: The optimization time dropped from 16 hours to 1 hour.
 Figure: Visualizing the reconstruction. GHOST maintains realistic contact and surface completion even from novel viewpoints.
Figure: Visualizing the reconstruction. GHOST maintains realistic contact and surface completion even from novel viewpoints.
Why It Matters: Beyond the Numbers
GHOST isn't just a faster algorithm; it's a shift toward Category-Agnostic intelligence. It doesn't need to be pre-trained on a specific "mug" or "hammer." By combining real-time retrieval of 3D priors with the efficiency of Gaussian Splatting, it opens the door for:
- Teleoperation: Controlling robots in real-time.
- Immersive VR: Seeing your own hands interact with virtual objects with zero lag.
- In-the-wild MoCap: Reconstructing complex human activities from a simple smartphone video.
Conclusion
While GHOST still has limitations—such as relying on the quality of retrieved priors—it represents a massive leap forward. By bridging the gap between explicit geometry and neural rendering, it proves that physical plausibility and speed can coexist in the world of computer vision.
Takeaway: The future of 3D reconstruction lies in hybrid models that know how to "fill in the blanks" using prior world knowledge.