本文提出了 GigaWorld-Policy,一个以动作为核心(Action-Centered)的高效世界-动作模型(World-Action Model, WAM)。该模型基于扩散 Transformer 架构,通过在训练中引入动作条件的未来视觉动态预测作为密集监督,显著提升了机器人策略的学习效率;在推理时,它支持可选的视频解码分支,实现了极低的控制延迟。
TL;DR
GigaAI 团队推出的 GigaWorld-Policy 成功打破了机器人“世界模型”部署难的瓶颈。它在训练时利用未来视觉预测(Future Video Prediction)提供高密度的物理监督,但在推理阶段却能“优雅地关掉”视频生成分支,直接输出动作序列。这种设计让它在保持世界模型高成功率的同时,比前代模型快了整整 9 倍,在真实场景中实现了极具竞争力的闭环控制性能。
1. 痛点深挖:稀疏监督与推理泥潭
目前机器人学界主要有两条技术路线:
- VLA 模型 (如 π0.5):通过模仿学习直接将图像映射到动作。缺点是监督信号太“干巴”,模型容易走捷径(Contextual Shortcuts),不理解动作背后的物理连续性。
- 世界模型 (WAM, 如 Motus):预测未来图像。虽然学得好,但在控制时需要像视频生成一样一帧帧扩散,速度慢得感人(通常 >3s/step),根本跟不上机械臂的实时响应需求。
GigaWorld-Policy 的核心直觉是:“理解物理演化”对于训练很重要,但对于推理,它应该是一个可选的信号而非负担。
2. 核心架构:因果遮掩下的“分治与统一”
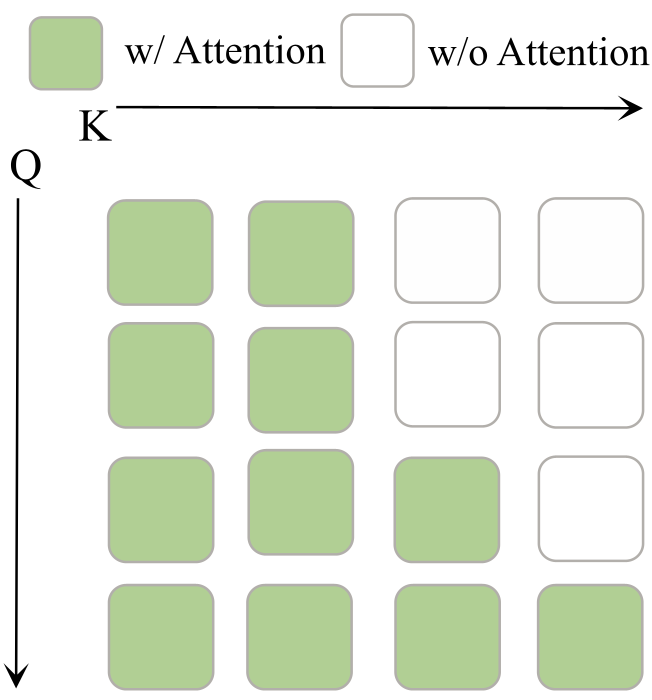
GigaWorld-Policy 基于 5B 参数的扩散 Transformer (Wan 2.2)。其最精妙的设计在于 Causal Self-Attention Mask(因果注意力遮掩):
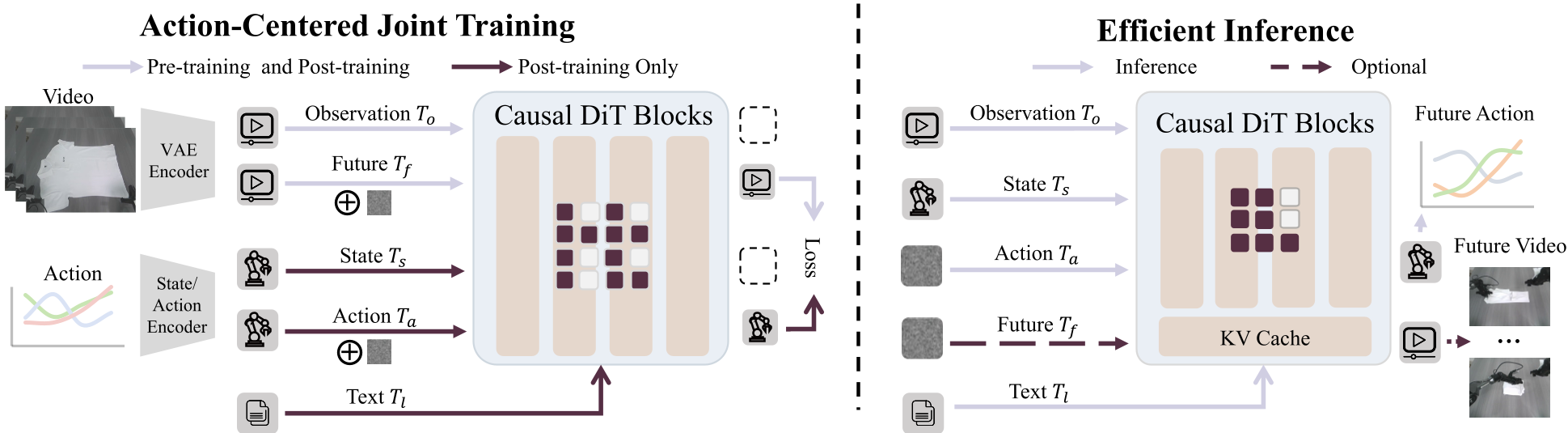
- 训练阶段:模型将当前观察 ()、本体状态 ()、动作 () 和未来视频 () 打包。通过特定的遮掩策略(见下图),确保 Action 只能看到当前,而 Video 可以看到 Action。这种物理上的“因果一致性”强制模型在预测视频的同时优化动作表征。
- 推理阶段:模型只需对 部分进行 Flow Matching 采样。由于不再需要预测数以百计的视觉 Token,计算量骤降。
3. 课程学习方案:从互联网视频到机械臂
为了让模型具备深厚的物理直觉,作者设计了三步走计划:
- Foundation:初始化自通用视频生成模型,继承人类对世界的常识。
- Embodied Pre-training:在 10,000 小时的机器人视频和人类手部交互视频(Ego4D 等)上练就“火眼金睛”,学习跨视角的一致性和交互动力学。
- Post-training:在特定机器人的标注轨迹上进行微调,完成从“看客”到“执行者”的转变。
4. 实验验证:又快又稳
在 RoboTwin 2.0 仿真环境的 50 个复杂任务中,GigaWorld-Policy 展现了压倒性的优势。
关键战绩指标:
- 推理速度:360ms/step,比 Motus 的 3231ms 快了近一个量级。
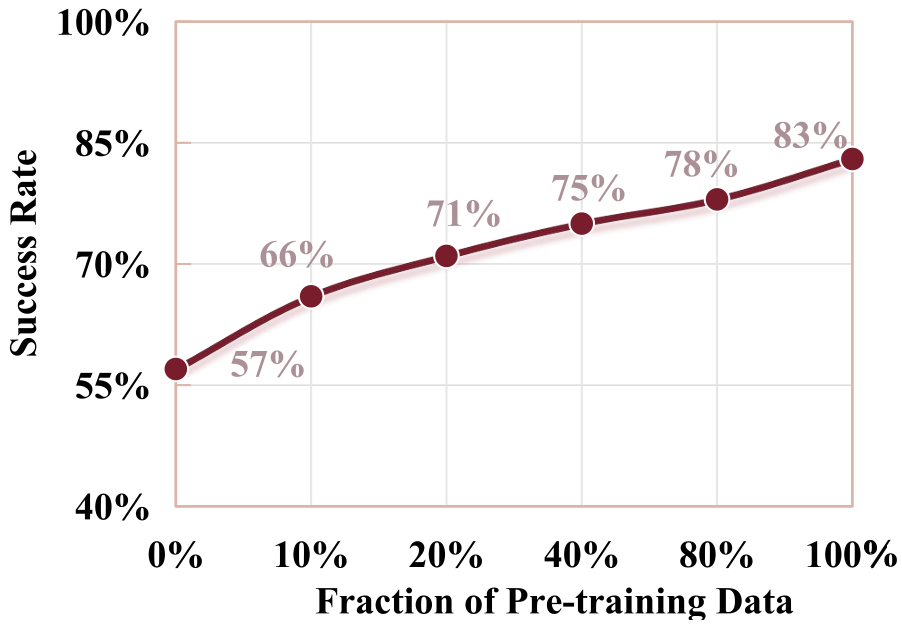
- 数据效率:在真实世界任务中,仅需 10% 的数据量即可达到基线 VLA 模型使用 100% 数据时的表现(见下图数据效率对比)。
- 泛化能力:在“扫垃圾”、“扫码”等需要精准对齐的真实任务中,平均成功率达到 83%,远超 Cosmos-Policy 等同类模型。
5. 深度洞察与总结
GigaWorld-Policy 的成功揭示了具身智能的一个重要趋势:世界模型不一定非要用来“生成”未来,它更大的价值在于作为一种“高维正则项”。
局限性:
- 虽然支持多视角,但目前的视觉输入仍需拼接成 Composite Image,可能存在空间分辨率的损失。
- 对于极长周期的任务,单纯依赖 Action Chunking 而不进行闭环视频回放,可能会在极端长程任务中丢失全局目标感。
未来展望:
这种“训练耦合、推理去耦”的策略,极有可能成为未来工业级机器人 Foundation Model 的标准范式。它既保留了大模型的推理深度,又兼顾了嵌入式设备的实时需求。