GlowQ is a novel group-shared low-rank approximation framework for quantized Large Language Models (LLMs) that introduces a shared right-factor matrix for modules within the same input-sharing group. It achieves SOTA recovery in low-bit (W4A16) regimes, matching the accuracy of independent per-layer correction methods while significantly reducing memory and latency overhead.
TL;DR
GlowQ redefines how we "fix" quantization errors in Large Language Models. Instead of slapping a unique low-rank correction module on every single layer (which is slow and memory-hungry), GlowQ groups modules that share the same input and uses a single, shared high-precision projection. The result? 37.4% higher throughput and lower perplexity compared to standard 4-bit quantization methods.
The Problem: The High Cost of Being Unique
Post-Training Quantization (PTQ) to 4-bits (W4A16) is the industry standard for LLM deployment. However, 4-bit weights often lead to accuracy degradation. Current state-of-the-art methods like L2QER and QERA fix this by adding a low-rank term: $W \approx W_q + AB$.
The catch? These methods treat every projection ($W_q, W_k, W_v$, etc.) as an island. They compute the high-precision product $A(BX)$ repeatedly. In a standard Transformer, $Q, K,$ and $V$ all look at the exact same input $X$. Computing $B_q X, B_k X,$ and $B_v X$ separately is logically redundant and computationally expensive. This "independence" is a bottleneck that prevents quantized models from reaching their full speed potential.
Methodology: Shared Projections and Covariance Alignment
1. The Group-Shared Insight
GlowQ’s core innovation is simple yet profound: If modules share an input, they should share the heavy lifting. In a Transformer block, the $Q, K,$ and $V$ projections are grouped. GlowQ learns a single $B_{shared}$ for the entire group.
- Inference: Compute $R = B_{shared} X$ once.
- Correction: Each module $i$ only performs a lightweight $A_i R$.
2. Why it Works: Covariance Alignment
You can't just average the errors. Real-world LLM activations are anisotropic (highly directional). GlowQ uses a data-aware objective: $$\min_{A, B} | (E_{cat} - AB) \Sigma_x^{1/2} |_F^2$$ By "whitening" the error matrix with the input covariance $\Sigma_x$, the shared factor $B$ is forced to align with the directions the model actually uses most frequently.
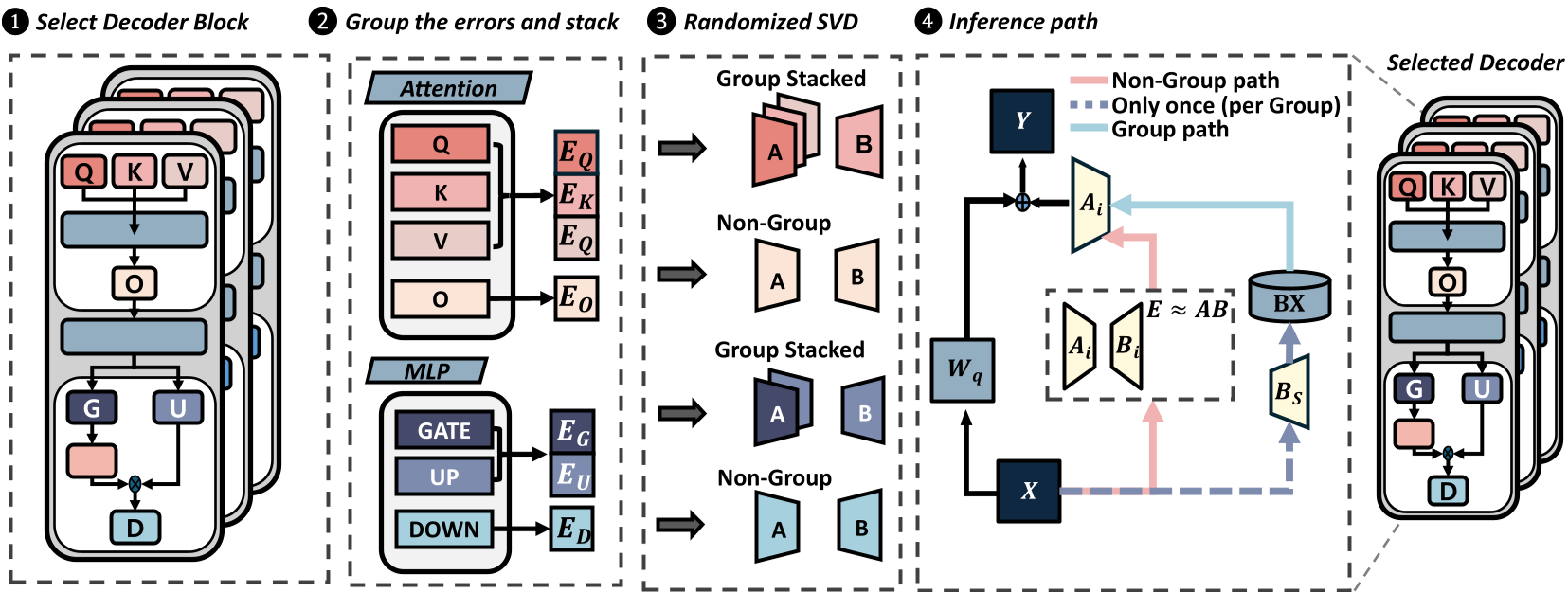
3. Scaling Up with QR-Reduced RSVD
To avoid the massive memory overhead of calculating SVD on tall matrices, the authors use a QR-reduced Randomized SVD. They compress the stacked error into a $d imes d$ core, perform a fast randomized sketch, and then lift the solution back. This makes the "calibration" phase feasible even for 30B+ models.
Experimental Results: Efficiency Meets Accuracy
GlowQ was tested against a battery of models including LLaMA 3, Qwen 2.5, and Mistral.
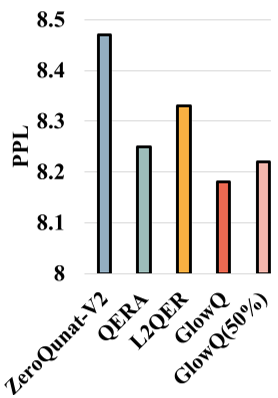
- SOTA Recovery: On LLaMA 3 8B, GlowQ achieved a perplexity of 6.59, outperforming both AWQ (6.64) and GPTQ (6.63) while being faster.
- Latency Gains: In LLaMA 2 13B tests, GlowQ-S (the selective version) reduced the Time-To-First-Byte (TTFB) by 23.4%.
- Throughput: The throughput (tokens per second) increased by 37.4% because the GPU no longer wastes cycles on redundant high-precision matmuls.
Deep Insight: Beyond Dense Models
One of the most impressive findings is GlowQ's performance on Mixture-of-Experts (MoE). In an MoE block, you have dozens of experts. Standard methods would add correction parameters to every expert. GlowQ uses a single $B_{shared}$ across all experts in a group, reducing the memory footprint of error correction by 63% while matching the accuracy of far more bloated methods.
Conclusion & Takeaways
GlowQ proves that "independent error correction" is a luxury we don't need. By exploiting the inherent grouping of operations in the Transformer architecture, we can have our cake and eat it too: the memory savings of 4-bit quantization with the speed of optimized kernels and the accuracy of high-precision models.
Key Takeaway for Practitioners: When designing low-rank adapters (LoRA) or quantization corrections, always look for shared input manifolds. If multiple weights act on the same activation, there is a "shared subspace" waiting to be exploited for massive efficiency gains.
Limitations: The "Selective Restore" policy (GlowQ-S) requires model-specific tuning (the "elbow point" on the PPL/Latency curve) to find the optimal trade-off. However, the default "GlowQ" (full restoration) still offers a significant speedup with no tuning required.