本文提出了 GSEM (Graph-based Self-Evolving Memory),一种用于增强临床推理能力的图结构自进化记忆框架。该方法通过构建双层记忆图组织临床经验,并结合适用性感知检索与反馈驱动的在线校准,在 MedR-Bench 等医疗基准测试中配合 DeepSeek-V3.2 达到了 70.90% 的 SOTA 平均准确率。
TL;DR
传统的 RAG(检索增强生成)在医疗领域常因“药不对症”导致推理失败。来自哈工大的研究团队提出了 GSEM (Graph-based Self-Evolving Memory),通过将临床经验转化为带权重的双层记忆图,实现了对经验适用边界的精准掌控。该方法不仅在 MedR-Bench 斩获 SOTA,更通过类似人类进化的“反馈-校准”机制,让模型越用越聪明。
1. 痛点:为什么传统的 RAG 救不了临床推理?
目前的 LLM 智能体在处理医学案例时,虽然能检索大量历史经验,但往往面临两大死穴:
- 边界失效 (Boundary Failure):检索到了相似案例,却忽略了关键的反指征(Contraindication),导致错误的治疗建议。
- 协作失效 (Collaboration Failure):同时检索出的多条经验彼此冲突,缺乏内在逻辑关联,导致推理过程支离破碎。
作者认为,经验不应是扁平的文本块,而应是具有结构化逻辑和动态权重的有向图。
2. 核心架构:双层记忆图 (Dual-layer Memory Graph)
GSEM 的核心在于其精妙的图结构设计,将经验(Experience)解构为两个维度:
- 实体层 (Entity Layer):模仿人类医生的临床路径,将每条经验拆解为:条件 (Cond.)、约束 (Constr.)、行动 (Act.)、依据 (Rat.)、结果 (Out.)。
- 经验层 (Experience Layer):定义了经验之间的演化关系。每个节点都有一个质量分 Q,每一条边都有一个权重 W。
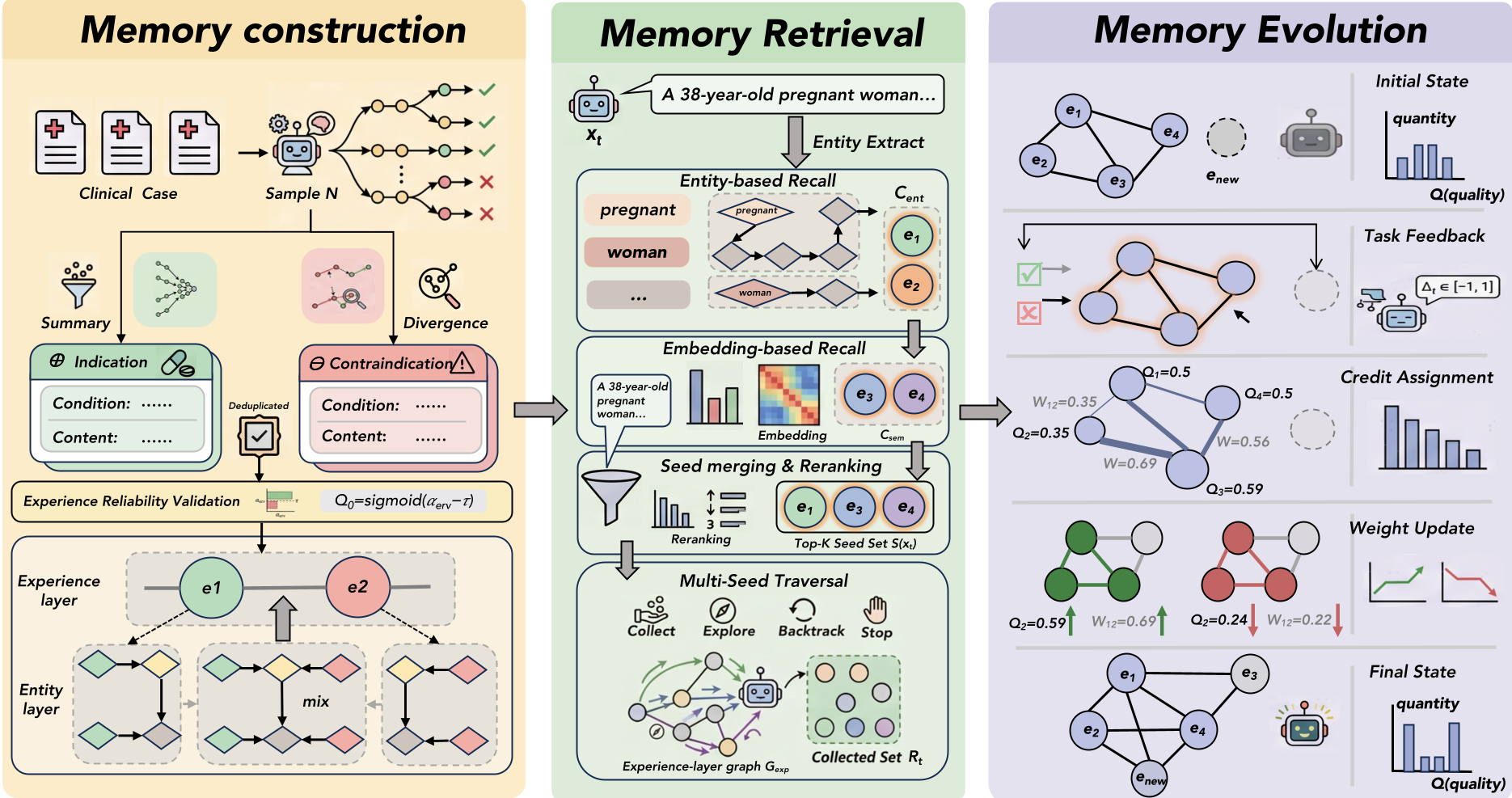 图 1:GSEM 三阶段流水线:从轨迹中提取经验、基于图遍历检索、到基于反馈的自进化。
图 1:GSEM 三阶段流水线:从轨迹中提取经验、基于图遍历检索、到基于反馈的自进化。
3. 绝招:适应症与禁忌症的自进化
不同于一般方法只存“成功的案例”,GSEM 专门提取禁忌症 (Contraindication)。通过对失败轨迹的对比分析,模型学会了“哪些坑不能踩”。
自进化机制 (Self-Evolving) 是其灵魂:
- 在线校准:每完成一笔任务,系统根据结果反馈(Delta)实时调整节点 Q 和边权 W。
- 性能引导:如果某两条经验同时使用多次且效果拔群,它们之间的 W 就会增加;反之则削弱,甚至将低质经验剔除。
4. 实验战绩:统治医疗推理基准
在 MedR-Bench 和 MedAgentsBench 两个极具挑战性的榜单上,GSEM 展现了压倒性优势。
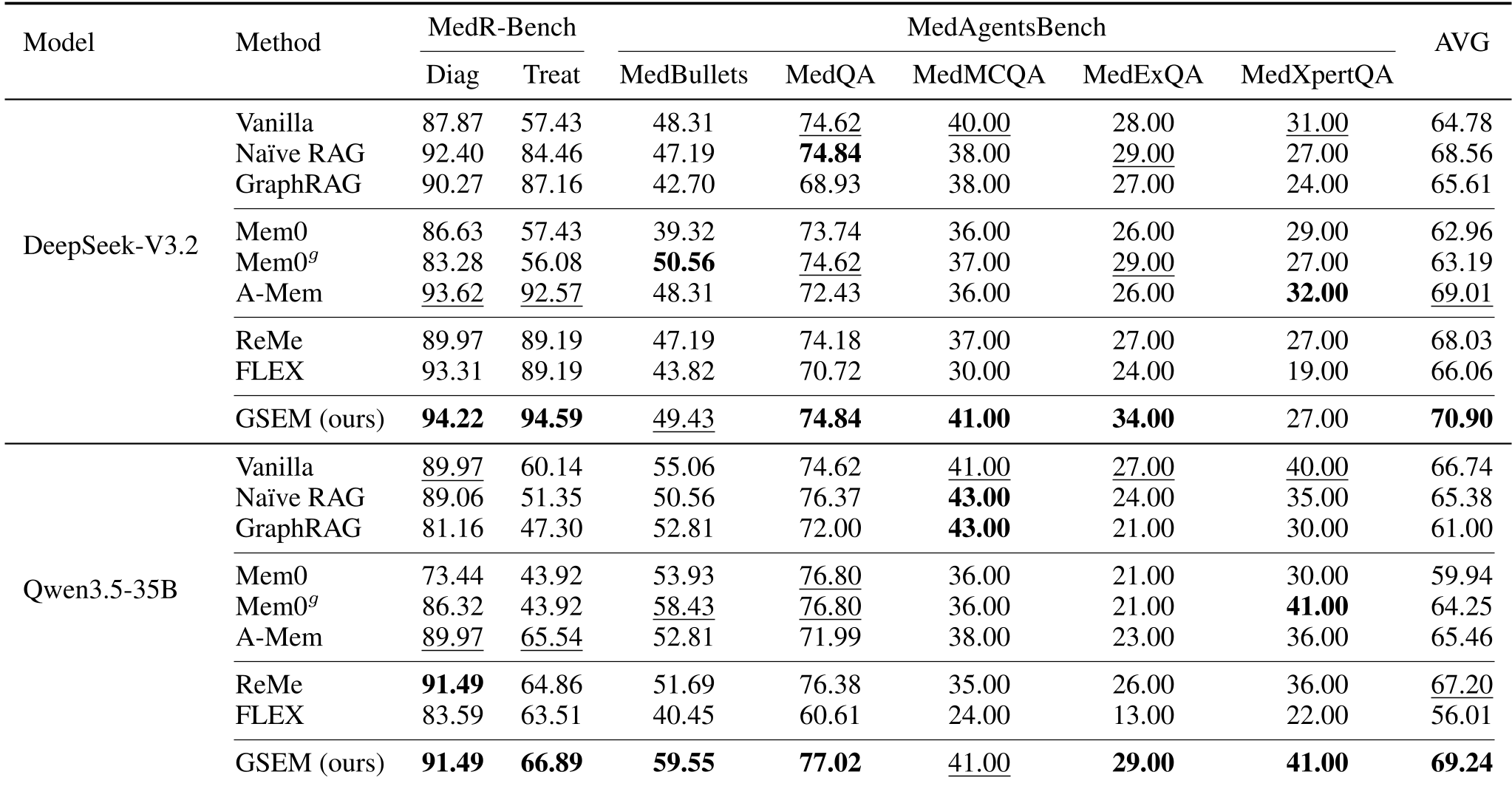 表 1:GSEM 在 DeepSeek 和 Qwen 两个底座模型上均显著超越了 Naive RAG 和 GraphRAG。
表 1:GSEM 在 DeepSeek 和 Qwen 两个底座模型上均显著超越了 Naive RAG 和 GraphRAG。
有趣的是,实验发现 Generator 的能力上限决定了最终表现,而 Retriever 的效率决定了部署成本。 GSEM 即使搭配较小的检索器,也能通过优秀的图拓扑实现高精度的经验定位。
5. 深度洞察:经验的“极化”现象
通过分析进化过程(图 2),研究者发现经验的分值 Q 会随着时间推移出现明显的极化效应:好经验脱颖而出,有毒经验被迅速压制。这种“优胜劣汰”使得检索过程日益聚焦于高价值子图。
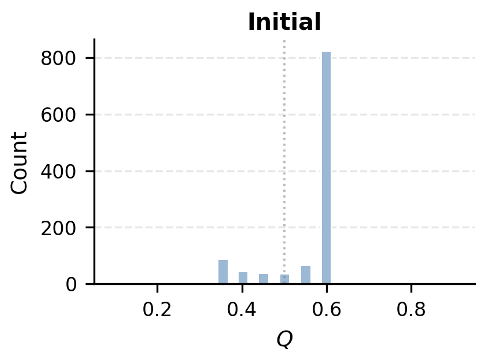 图 2:随时间演化的节点质量 Q 分布,可以看到其区分度显著增强。
图 2:随时间演化的节点质量 Q 分布,可以看到其区分度显著增强。
6. 总结与局限
GSEM 为医疗 AI 提供了一个可解释、可进化的长效记忆范式。尽管它目前在自动评估中表现出色,但其在真实临床多步交互、长期随访场景中的鲁棒性仍需专家介入验证。
** takeaway**:经验不仅是知识的堆砌,更是关系的动态平衡。GSEM 的出现预示着从“简单提取”到“结构化反思”的 RAG 2.0 时代已经开启。