The paper introduces EgoPoint-Ground, the first large-scale multimodal dataset for egocentric deictic visual grounding, containing over 15k interactive samples. It also proposes SV-CoT, a Spatial-reasoning-based Visual Chain-of-Thought framework that achieves SOTA performance by reformulating grounding as a structured inference process.
TL;DR
Researchers from Tsinghua University and Apple have released EgoPoint-Ground, a massive dataset of 15,000+ samples focused on "pointing-based" visual grounding in first-person views. They also introduced SV-CoT, a reasoning framework that mimics human spatial deduction, boosting object localization accuracy by 11.7% over traditional Multimodal Large Language Models (MLLMs).
The Problem: The Ambiguity of "That One"
In current AI research, Visual Grounding (VG) is mostly a "bystander" task. You give a model a photo and a description like "the red apple on the left," and it finds it. But in the real world—wearing AR glasses or interacting with a robot—we don't talk like that. We point our finger and say, "What is this?" or "Give me that."
Existing models fail here because:
- Linguistic Ambiguity: "This" means nothing without a spatial vector.
- Viewpoint Challenges: Egocentric (first-person) views involve hand occlusions and drastic perspective shifts.
- Missing Physics: Most MLLMs treat coordinates as simple text tokens rather than geometric rays.
Methodology: SV-CoT (Spatial-Visual Chain-of-Thought)
Instead of asking the model to "guess" the box in one go, the authors force the model to think through the geometry using a structured reasoning chain.
1. The Three-Step Rationalization
- Intent Parsing: The model analyzes the hand orientation to create a directional primitive (a vector).
- Trajectory Simulation: It simulates a "virtual ray" from the fingertip into the scene, pruning any objects that don't intersect this path.
- Spatio-semantic Verification: Finally, it cross-references the remaining candidates with the linguistic query to pick the winner.
 Figure: The SV-CoT pipeline reformulating grounding as a structured inference process.
Figure: The SV-CoT pipeline reformulating grounding as a structured inference process.
The EgoPoint-Ground Dataset
To train and test this, the authors built the first high-fidelity egocentric benchmark. It’s a hybrid mix of:
- Real-world data: Captured via RayNeo smart glasses.
- Synthetic data: LMM-generated challenging scenarios.
- Edited data: Transforming third-person COCO images into first-person pointing scenes.
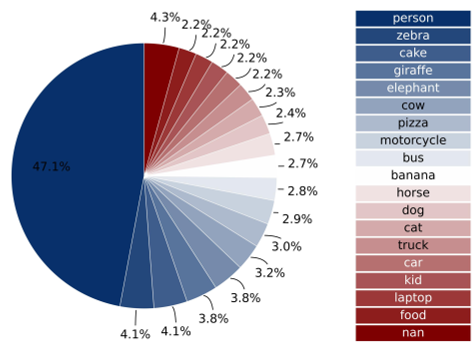 Figure: Distribution of categories in EgoPoint-Ground, showing a focus on interactive objects.
Figure: Distribution of categories in EgoPoint-Ground, showing a focus on interactive objects.
Experiments & Breakthroughs
The results confirm a massive "deictic alignment failure" in current models. Foundational models like LLaVA struggle to reach 30% accuracy when purely geometric cues are provided.
- SOTA Performance: Built on Qwen3-VL, the SV-CoT framework reached 82.0% Precision@0.3 in real-world tests.
- Resilience: Even at a strict IoU of 0.7, SV-CoT maintained high precision, while other models' performance collapsed (some dropping to near 0%).
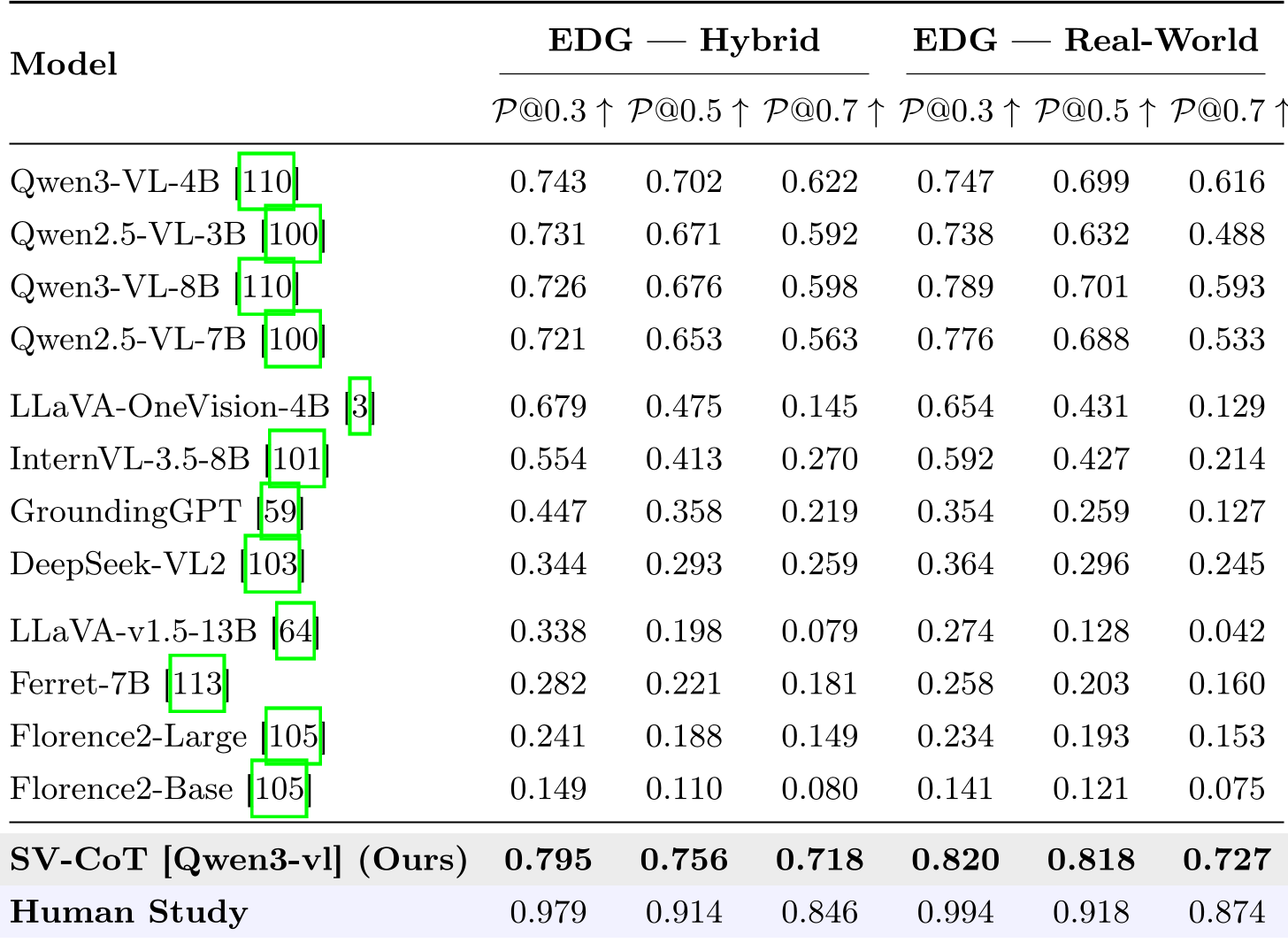 Table: Comparison across various MLLMs shows SV-CoT consistently outperforming the baseline.
Table: Comparison across various MLLMs shows SV-CoT consistently outperforming the baseline.
Critical Insight: The "Geometric Gap"
The most telling finding is the POG (Physical Pointing-Only Grounding) task. Without words, most AI models are essentially "blind" to the direction of a finger. They have learned to align "words to pixels" but haven't learned the "physics of pointing." SV-CoT’s success proves that specifically modeling the spatial trajectory is the key to closing the 30% performance gap between AI and human-level intuition.
Conclusion & Future
EgoPoint-Ground and SV-CoT represent a major step toward Embodied AI. By treating the human hand as a primary communication signal, we move closer to agents that can actually understand our physical intent in real-time. The next frontier? Expanding this from static images to video streams, capturing the dynamic motion of a hand as it sweeps across a room.
Paper: Beyond Language: Grounding Referring Expressions with Hand Pointing in Egocentric Vision Dataset & Code: To be made publicly available.