本文推出了 EgoPoint-Ground,这是首个专注于第一视角(Egocentric)手势指向视觉定位的大型多模态数据集。该研究同步提出了 SV-CoT 基线框架,通过视觉思维链(Visual Chain-of-Thought)将手势指向与语言指令结合,实现了在复杂第一视角场景下对指代对象的精准定位与问答。
TL;DR
视觉定位(Visual Grounding)正从“纸上谈兵”走向“具身交互”。清华大学等机构的研究团队发布了 EgoPoint-Ground,这是首个第一视角下手势指向(Hand Pointing)的大规模多模态数据集。同时提出的 SV-CoT 框架通过视觉思维链,使得 AI 在处理“这个东西是什么?”等模糊指令时的定位精度提升了 11.7%。
1. 痛点:被忽视的非语言线索
在早期的 Visual Grounding 研究中,我们习惯于让模型处理诸如“左边红色的苹果”这样详细的文本。但在穿戴着 AR 眼镜或操作机器人的具身场景中,人类更自然的表达是:随手一指,然后说“那个是什么?”
现有方法的局限性:
- 视角缺失:传统数据集(如 RefCOCO)多为旁观者视角,缺乏第一人称的交互感。
- 语言歧义:当场景中有多个相似物体时,单纯的文本解析无法消除歧义。
- 几何盲区:主流 MLLM(多模态大模型)擅长识别物体,却不擅长理解从“指尖”到“目标”的几何投影关系。

2. EgoPoint-Ground:连接物理与语义
为了解决上述问题,作者构建了一个包含 15,338 张图像的数据集,涵盖 140 个类别和 20 多个日常场景。
数据集的三个核心特征:
- 混合生成范式:结合了真实世界采集(RayNeo 智能眼镜)、LMM 辅助合成以及图像编辑技术,确保了场景的覆盖深度。
- 多粒度标注:不仅有目标框(Bounding Box),还包含了精准的手势姿态(Hand Pose)标注和 VQA 对。
- 高难度挑战:63.7% 的样本包含同类干扰项,42.5% 的目标存在遮挡,这极大地考验了模型的 disambiguation(消除歧义)能力。
3. 核心算法:SV-CoT (Spatial-Reasoning Visual CoT)
作者发现,直接让模型回归坐标(Regression)容易导致空间幻觉。于是,他们借鉴了人类的推理直觉,提出了 SV-CoT。
推理的三部曲:
- 意图解析 (Deictic Intent Parsing):通过手势在 Spatial Anchors 中的位置,确定一个全局指向矢量 。
- 轨迹模拟 (Geometric Trajectory Simulation):在空间中投射一条虚拟射线 ,将搜索范围从全图剪枝为射线穿过的候选区域。
- 时空验证 (Spatio-semantic Verification):最后结合模糊的文本描述(如“that boy”),在剪枝后的候选集中进行语义对齐,选出最优解。

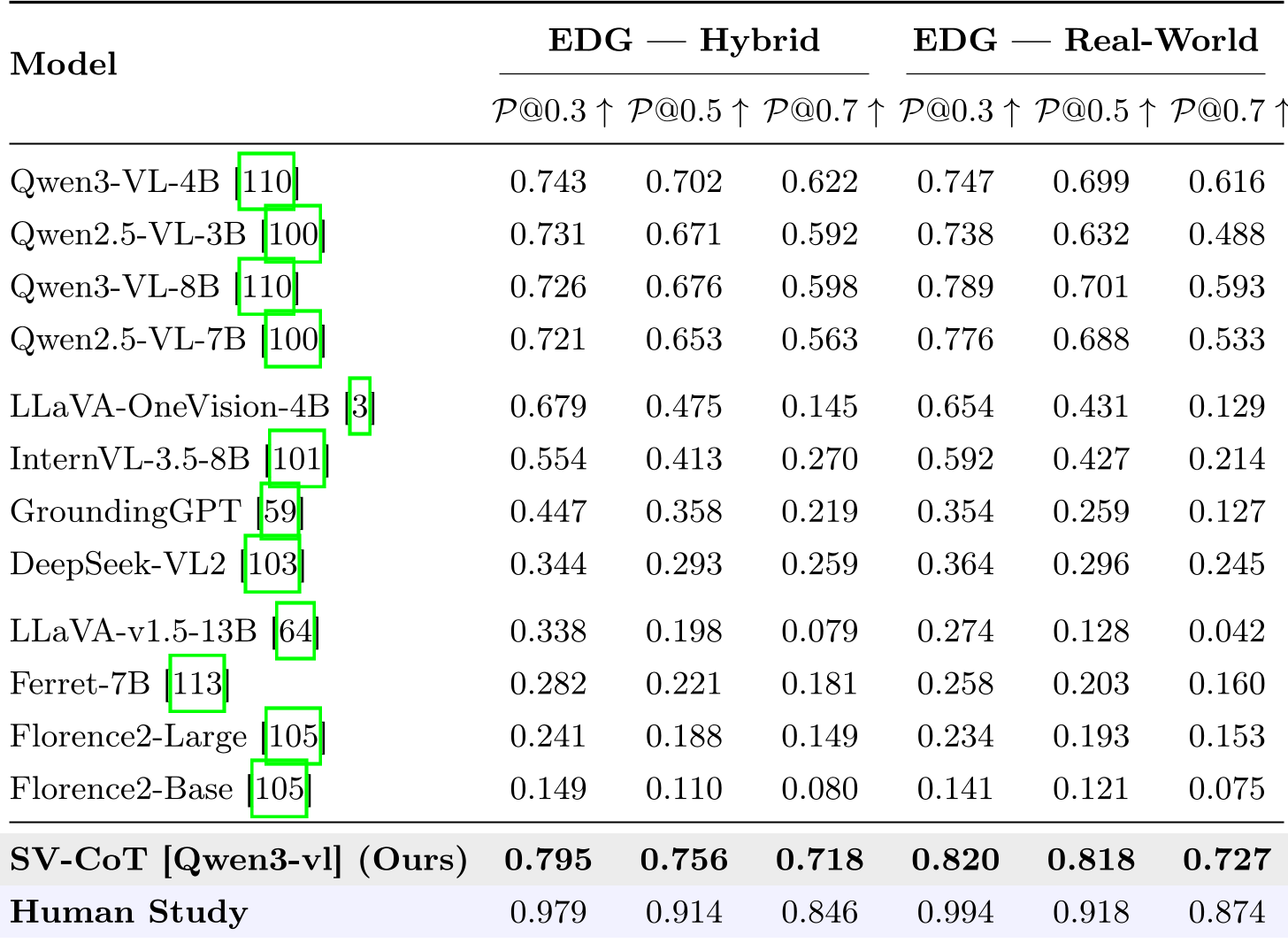
4. 实验战绩:MLLM 在几何推理上的“滑铁卢”
实验结果非常令人深思。在 EDG(第一视角指代定位)任务中:
- Qwen3-VL 为代表的模型虽然领先,但仍存在明显的“几何盲区”。
- SV-CoT 的介入,使得 Qwen3 在实时场景下的 P@0.5 达到了 81.8%,比直接输出坐标的方法高出 11.7%。
关键发现(Ablation Study): 作者设置了 POG (Physical Pointing-Only Grounding) 任务,即屏蔽文本,只给手势图。结果发现,绝大多数模型(如 LLaVA-OneVision)在 P@0.7 严苛指标下的得分几乎归零。这证明了:目前的 AI 并不理解“指向”这一物理动作背后的几何逻辑,它们更多是在靠文本关键词“猜”位置。
5. 总结与洞察
《Beyond Language》这篇论文标志着视觉定位任务从“语义对齐”向“物理感知”的进化。
- 学术价值:填补了第一视角手势指代数据集的空白。
- 行业启示:未来的智能眼镜和助老机器人,不应只卷参数量,更应强化对物理空间关系的隐式建模。
局限性:目前数据集主要集中在静态的食指指向,未来需要扩展到更复杂的动态手势及视频流序列。
编者按:本文基于 arXiv 论文重构。该研究为具备交互能力的具身智能体提供了重要的基础设施。