本文推出了 Gym-Anything 框架,旨在将任何软件自动转换为交互式的 AI Agent 环境。利用该框架构建了 CUA-World 数据集,包含 200 个软件应用和 10,000 多个长程任务,在多个指标上达到 SOTA 并显著提升了 2B 规模小模型的表现。
TL;DR
如果 AI 要真正替代人类完成“数字劳动”,它们必须学会使用医生、工程师和会计师手中的复杂专业软件。卡内基梅隆大学(CMU)团队提出的 Gym-Anything 实现了这一愿景:它是一个能自动将复杂软件(如 3D Slicer 医疗影像软件、Odoo ERP 系统等)转化为标准化强化学习环境的工厂。基于此构建的 CUA-World 正以前所未有的规模(200+ 软件,10K+ 任务)刷新了我们对计算机操作智能体(Computer-Use Agents, CUA)的认知。
动机:为什么现有的 AI Agent 只是“玩具”?
当前的 CUA 研究面临两个严重脱节:
- 任务短小且廉价:大多数 Benchmark 还在测试 Agent 如何修改壁纸或填写网页表单,这与真实世界中动辄数百步的专业办公流程(Long-horizon)相去甚远。
- 构建成本极高:手动配置一个包含真实数据的专业软件环境通常需要专家耗时数周。
作者给出的 Insight 是:环境构建本身就是一个编码和 CUA 任务。既然 Agent 可以操作软件,那为什么不让 Agent 来自动安装、配置软件并生成测试任务呢?
核心方法:多智能体协作的环境工厂
1. 软件选择:跟着 GDP 走
作者拒绝拍脑袋决定支持哪些软件。他们建立了一个公式,根据美国劳工统计局(BLS)的数据,将 GDP 归属到特定职业,再关联到该职业使用的软件类别。最终筛选出 200 个经济影响力最大的软件,涵盖医疗、教育、金融、工程等 22 个主要行业。
2. 创建-审计闭环 (Creation-Audit Loop)
这是本文最精妙的设计。为了应对环境配置中的不可靠性,系统雇佣了“两个智能体”:
- Creation Agent:负责写脚本(Docker/Bash)、找真实数据、安装软件。
- Audit Agent:扮演“杠精”角色。它不看代码注释,只看 Creation Agent 提供的截图和日志证据,检查软件是否卡在启动界面、数据是否是空填充。
- Shared Memory:所有的失败经验(如某种特定的网络配置)都会存入共享内存,使后续环境创建呈现 sublinear(亚线性)的时间增长。
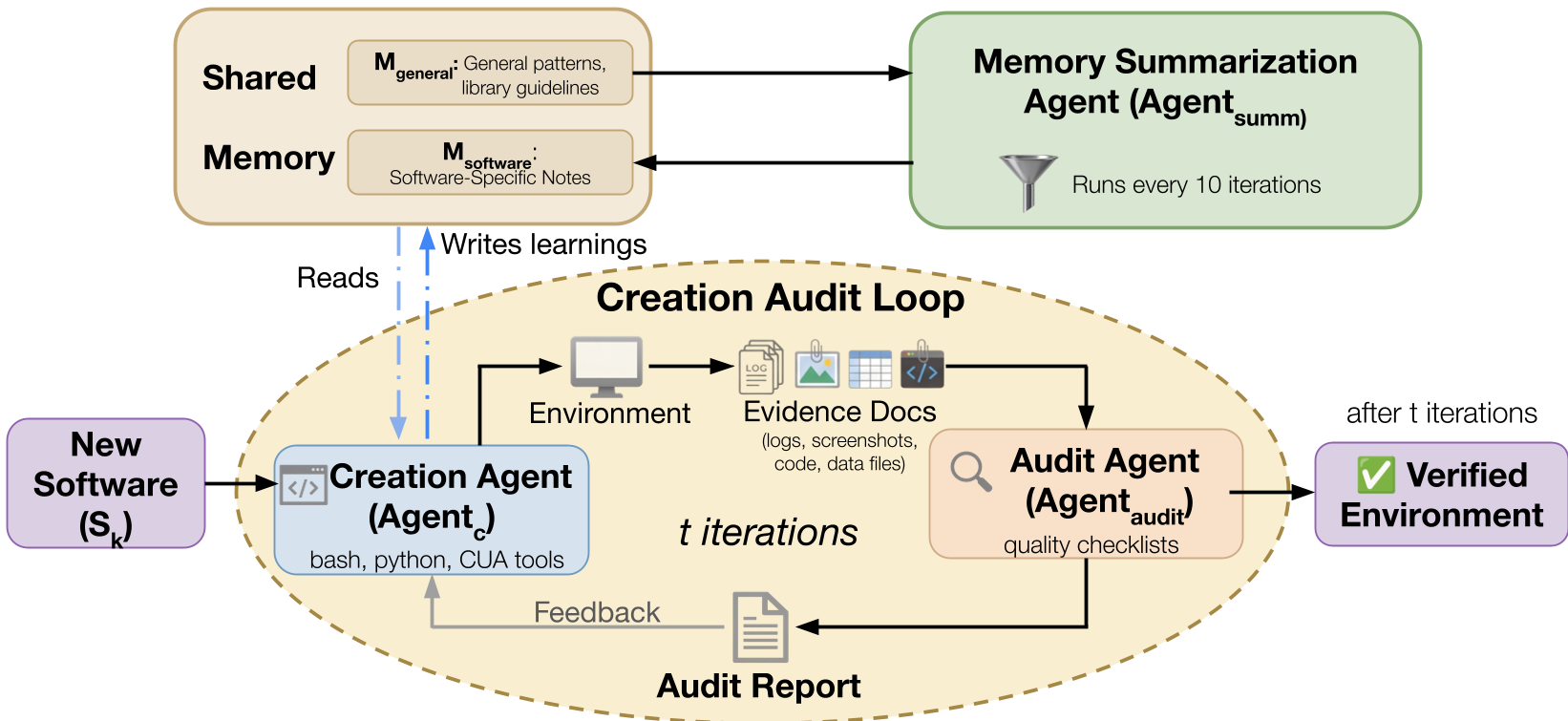 图 1:Gym-Anything 的创建-审计循环流,展示了 Agent 如何通过不断修正来构建稳定的环境。
图 1:Gym-Anything 的创建-审计循环流,展示了 Agent 如何通过不断修正来构建稳定的环境。
3. 特权信息驱动的自动评分
如何在没有人类标注的情况下给长程任务打分?作者利用了环境配置时的“上帝视角”。例如,在配置医疗影像任务时,脚本已经知道肿瘤的精确坐标。
- 系统提取这些特权信息(Privileged Information)。
- 生成一份包含 5-8 个关键步骤的 VLM Checklist。
- 评分时,VLM 参照 Checklist 检查 Agent 的操作轨迹,判定其是否真实完成了任务,还是在“作弊”(例如直接改写结果文件)。
实验战绩:让小模型也能处理复杂任务
CUA-World 的出现直接改变了训练范式。通过从强模型(如 Kimi-K 2.5)中蒸馏执行轨迹:
- 性能暴涨:一个仅有 2B 参数的 Qwen3-VL 模型,在 CUA-World-Test 上的成功率从 1.6% 提升到 4.4%,击败了规模大两倍的 4B 模型。
- 规模效应:实验证明性能随着支持软件数量的增加呈对数线性增长。这意味着只要持续增加环境,Agent 的上限就会不断抬高。
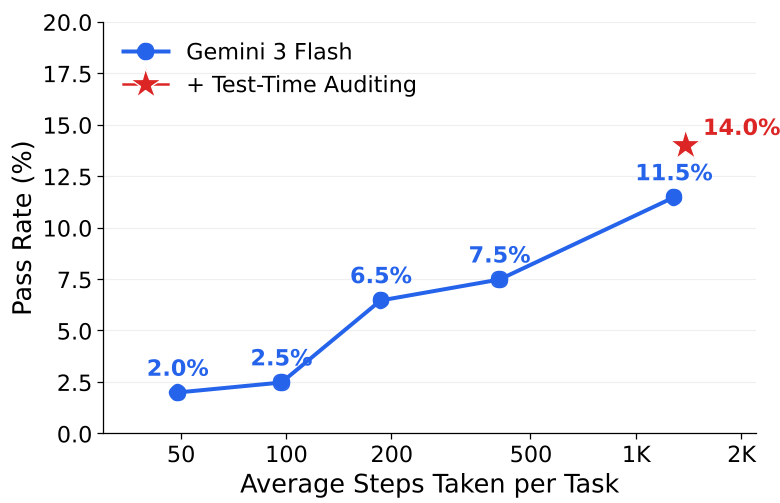 图 2:训练数据量对性能的影响。左图展示了随着软件应用(Software)和任务(Task)数量增加,模型分数稳步提升。
图 2:训练数据量对性能的影响。左图展示了随着软件应用(Software)和任务(Task)数量增加,模型分数稳步提升。
真实的挑战:CUA-World-Long
论文中最具杀伤力的是 CUA-World-Long。目前的顶尖模型(如 GPT-5.4、Gemini 3 Flash)在这些平均需要 400+ 步的任务中也显得捉襟见肘。
- 痛点暴露:Agent 经常在关键步骤陷入死循环(如不断滚动页面寻找不存在的按钮),或者过早地宣称任务已完成。
- 未来方向:作者通过“测试时审计”证明了,如果引入一个专门盯着 Agent 做没做完的“监工”,性能可以进一步压榨,但这暗示了我们需要更强的长程规划能力。
深度洞察
- Inductive Bias 的转移:Gym-Anything 实际上是将人类对专业知识的理解,转化为对环境自动构建规则的定义。这是一种极高的工程杠杆。
- 视觉复杂度是瓶颈:实验显示,小模型在面对 Blender 或 QGIS 等高视觉复杂度软件时几乎全军覆没,即使蒸馏也难以弥补感知缺陷。
- 经济价值闭环:这篇论文不再讨论“AI 能不能聊天”,而是讨论“AI 能不能产生 GDP”。这种研究导向值得学术界和工业界深思。
总结
Gym-Anything 不仅仅是一个数据集,它是一套生产 Agent 训练数据的工业流水线。它告诉我们,通往通用型计算机 Agent 的道路不是靠寻找更精妙的算法,而是靠构建更广阔、更真实、更具挑战性的数字世界。
局限性:虽然自动化程度很高,但目前仍排除了需要付费许可或特殊硬件驱动的软件。这也是未来“全面自动化”面临的最后壁垒。