HGGT (Hand Geometry Grounding Transformer) is a novel feed-forward framework for 3D hand mesh reconstruction from uncalibrated multi-view images. It achieves state-of-the-art performance across multiple benchmarks (e.g., HO3D, DexYCB) by jointly estimating camera poses and hand geometry without requiring prior calibration.
TL;DR
Hand Geometry Grounding Transformer (HGGT) is the first feed-forward framework that tackles 3D hand mesh reconstruction from uncalibrated multi-view images. By reformulating the problem as a visual-geometry grounding task, it eliminates the need for fixed camera rigs. It achieves SOTA results, often outperforming methods that rely on ground-truth camera parameters, while maintaining robustness against motion blur and occlusion.
Background Positioning: This work sits at the intersection of 3D Foundation Models (like DUSt3R/VGGT) and Articulated Mesh Recovery. It transitions hand reconstruction from a "constrained laboratory task" to a "flexible, in-the-wild utility."
The "Calibration Dilemma" in Hand Reconstruction
Why is 3D hand reconstruction so hard?
- Single-View (Standard): Easy to deploy but biologically limited. One camera cannot "see" through the palm or resolve the absolute depth of the wrist.
- Multi-View (Classical): Resolves ambiguity but requires Camera Calibration. You need to know exactly where every camera is in 3D space. This makes it impossible to just use two random smartphones to capture a gesture.
- Foundation Models (Scene-level): Models like VGGT look at the entire scene. Because hands are small and often move differently than the background, these models tend to ignore the hand's fine geometry in favor of the static room environment.
Methodology: The Unified Grounding Architecture
The core innovation of HGGT is its Unified Cross-Attention Refinement Module. Instead of treating camera estimation and hand reconstruction as separate sequential steps, HGGT solves them jointly.
1. Unified Tokens
The model uses two sets of tokens:
- Camera Tokens: To learn the relative extrinsics and intrinsics.
- Hand Tokens: To represent the global 3D geometry of the MANO hand model.
2. Multi-View Feature Aggregation
Based on a VGGT backbone, the model uses "Alternating Attention" to extract features across patches and frames. The refined tokens then query these features via cross-attention to "ground" the geometry in actual pixel data.
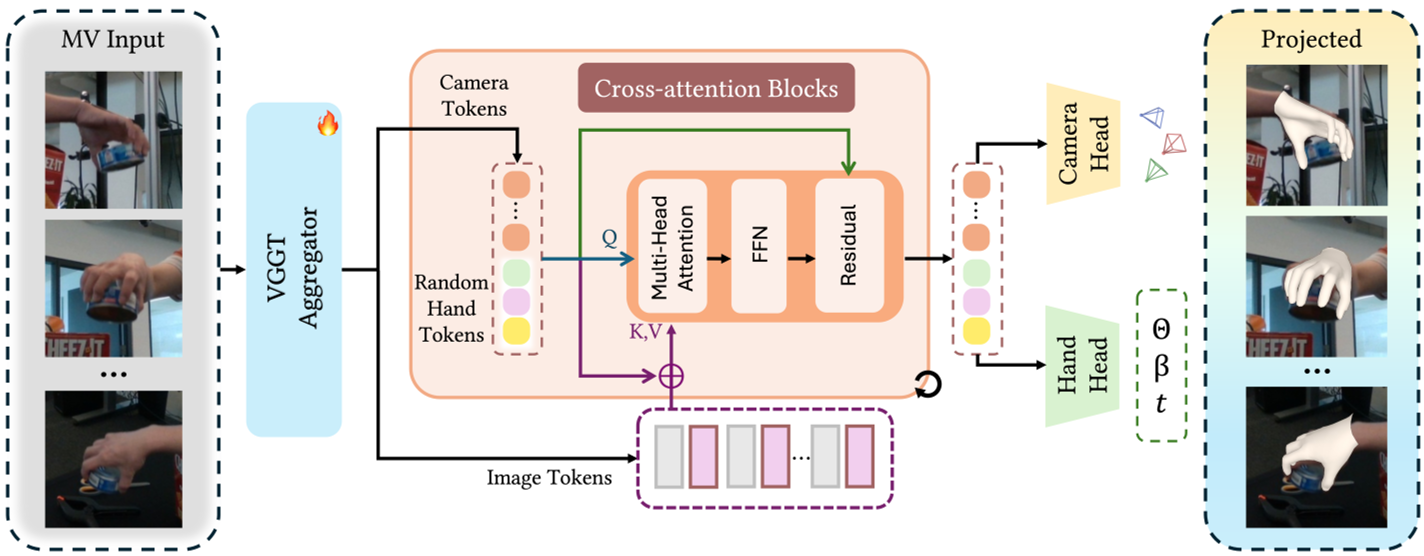 Fig. 2: The HGGT Pipeline. Note how hand and camera tokens are refined iteratively through multi-view context.
Fig. 2: The HGGT Pipeline. Note how hand and camera tokens are refined iteratively through multi-view context.
The Power of Mixed Data
To train a model this flexible, the authors created a massive hybrid dataset:
- In-the-wild Monocular: For lighting and background variety.
- Real Multi-view: For high-quality 3D hand annotations.
- Synthetic Multi-view (New!): By using GraspXL and Objaverse, they rendered 85k sequences with randomized camera views. This teaches the model geometric invariance—the hand is the same hand regardless of where the camera sits.
Experimental Excellence
HGGT significantly outperforms existing baselines when the cameras are not pre-calibrated.
SOTA Comparison
As shown in the table below, when POEM (the previous SOTA) is forced to use predicted cameras, its performance drops significantly. HGGT (Ours), however, maintains high precision.
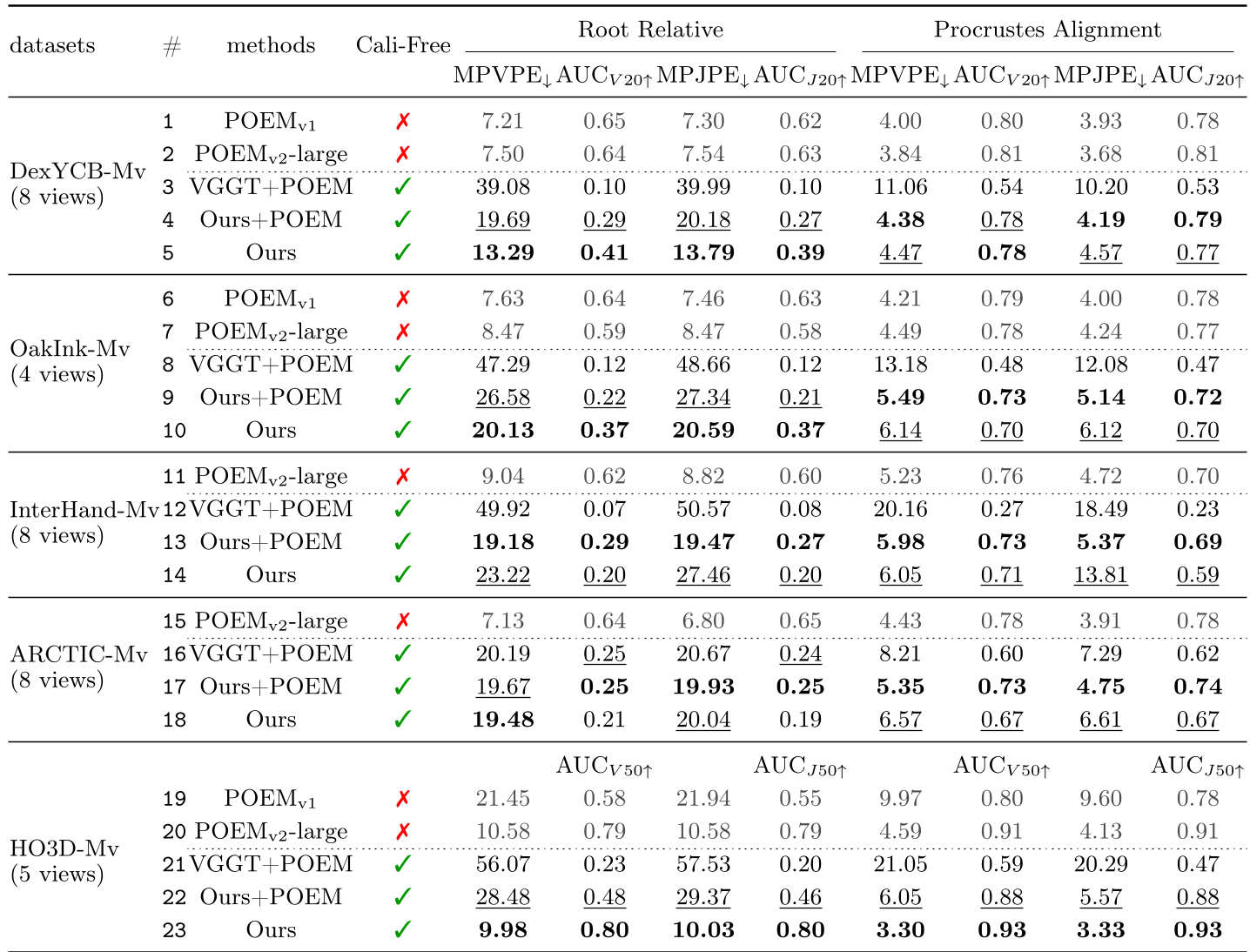 Table 1: Quantitative results across DexYCB, OakInk, and HO3D datasets.
Table 1: Quantitative results across DexYCB, OakInk, and HO3D datasets.
Robustness under Pressure
One of the most impressive feats of HGGT is its stability. Even when 6 out of 8 views are occluded by an object, or when the hand is a "blur" due to fast motion, the learned priors allow the model to hallucinate a plausible 3D mesh.
 Fig. 7: Performance under motion blur and heavy occlusion.
Fig. 7: Performance under motion blur and heavy occlusion.
Critical Insight & Future Work
Takeaway: The shift toward "Uncalibrated Multi-view" is the next frontier for AR/VR. HGGT proves that with enough synthetic data and a "grounded" transformer architecture, we no longer need the "calibration checkerboard."
Limitations:
- Detection Dependency: It still needs an external 2D detector (like ViTPose) to crop the hand first.
- Metric Scale: While the 3D structure is perfect, the "absolute" size/distance (metric depth) remains a challenge without at least one reference measurement.
Future Outlook: Integrating the hand reconstruction with object reconstruction in a single feed-forward pass will be the logical next step for autonomous robotic grasping.
Note: For more details, code, and the synthetic dataset, visit the Project Page.