本文提出了 HGGT (Hand Geometry Grounding Transformer),这是首个用于从未校准多视图图像中恢复 3D 手部网格的端到端前馈框架。该方法基于 VGGT 骨干网络,通过统一的 Transformer 架构同时估计相机位姿和 MANO 手部参数,实现了在野外(in-the-wild)环境下的高精度重建。
TL;DR
在 3D 手部重建领域,研究者通常面临一个权衡:是要单视图的灵活性,还是多视图的高精度(但伴随着严苛的相机校准要求)?来自 USTC、德州 A&M 等机构的研究团队提出了 HGGT (Hand Geometry Grounding Transformer)。这是业界首个能够直接从未校准、视角随机的多张照片中,一次性前馈(Feed-forward)推导出高精度 3D 手部模型和相机位姿的框架。
1. 痛点:为什么“直接用”现成的 3D 基础模型不行?
随着 DUSt3R 和 VGGT 等 3D 视觉基础模型的出现,端到端的几何推理变得可行。然而,团队发现直接将这类模型应用在手部重建上效果极差(见下图)。
- 视觉重叠极小:手部图像通常是局部裁剪图,不同视角间的背景极少,通用模型难以找到匹配点。
- 弱纹理干扰:手部皮肤纹理相对单一,传统的位姿估计算法容易被高纹理的静态背景带偏,导致手部点云扭曲。
 图注:原生 VGGT 在手部图像上的失败表现。左侧显示虽然背景对齐了,但手部点云完全错误;右侧显示裁剪图下几何推理彻底崩溃。
图注:原生 VGGT 在手部图像上的失败表现。左侧显示虽然背景对齐了,但手部点云完全错误;右侧显示裁剪图下几何推理彻底崩溃。
2. 核心贡献:HGGT 的架构设计
HGGT 的核心思想是将手部重建重构为一个**视觉几何接地(Visual-geometry Grounded)**任务。
2.1 统一交叉注意力细化 (Unified Cross-attention Refinement)
HGGT 不再仅仅依赖图像 patch,而是引入了一组可学习的 Hand Tokens。
- 机制:这些 Hand Tokens 与从 VGGT 初始化来的 Camera Tokens 一起,通过 4 层交叉注意力块。
- 直觉:Hand Tokens 像是一个“查询器”,主动在多张图像特征中搜索属于手部的几何线索(Pose, Shape),并与相机参数同步优化,实现了几何与位姿的解耦表达。
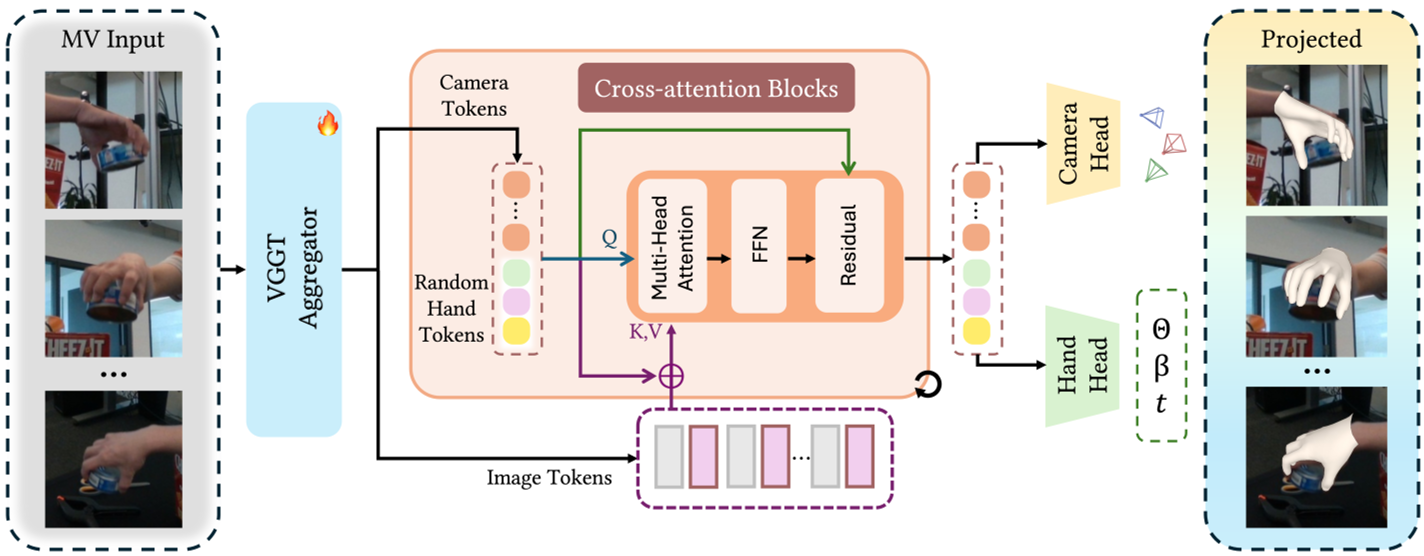 图 2:HGGT 总体流程。输入多视图图像,通过 VGGT 提取特征,再由 Refinement Module 迭代更新 Hand/Camera Tokens,最后输出 MANO 参数和外参。
图 2:HGGT 总体流程。输入多视图图像,通过 VGGT 提取特征,再由 Refinement Module 迭代更新 Hand/Camera Tokens,最后输出 MANO 参数和外参。
2.2 混合数据训练策略
为了训练这个拥有 14 亿参数的庞然大物,作者混合了三种数据来源:
- 大规模野外单视图数据:提升环境和光照的泛化性能。
- 真实多视图数据:提供高精度的三维基准。
- 合成多视图数据 (GraspXL + DART):针对“随机视角”进行特化训练,弥补了实验室采集设备视角固定的缺陷。
3. 实验结果:无校准胜过有校准?
HGGT 在多个标准数据集(HO3D, DexYCB, InterHand)上表现惊人。
- 意外的发现:在 HO3D 数据集上,HGGT 在完全不知道相机参数的情况下,精度(MPVPE 9.98mm)竟然优于那些输入了真值相机参数的 SOTA 方法(如 POEM)。这证明了端到端学到的几何一致性有时比人为校准更加稳健。
- 消融实验验证:作者证明了“全量微调”骨干网络至关重要。DINOv2 的预训练特征虽然强大,但必须通过针对手部几何的微调才能捕捉到指尖级别的精细位姿。
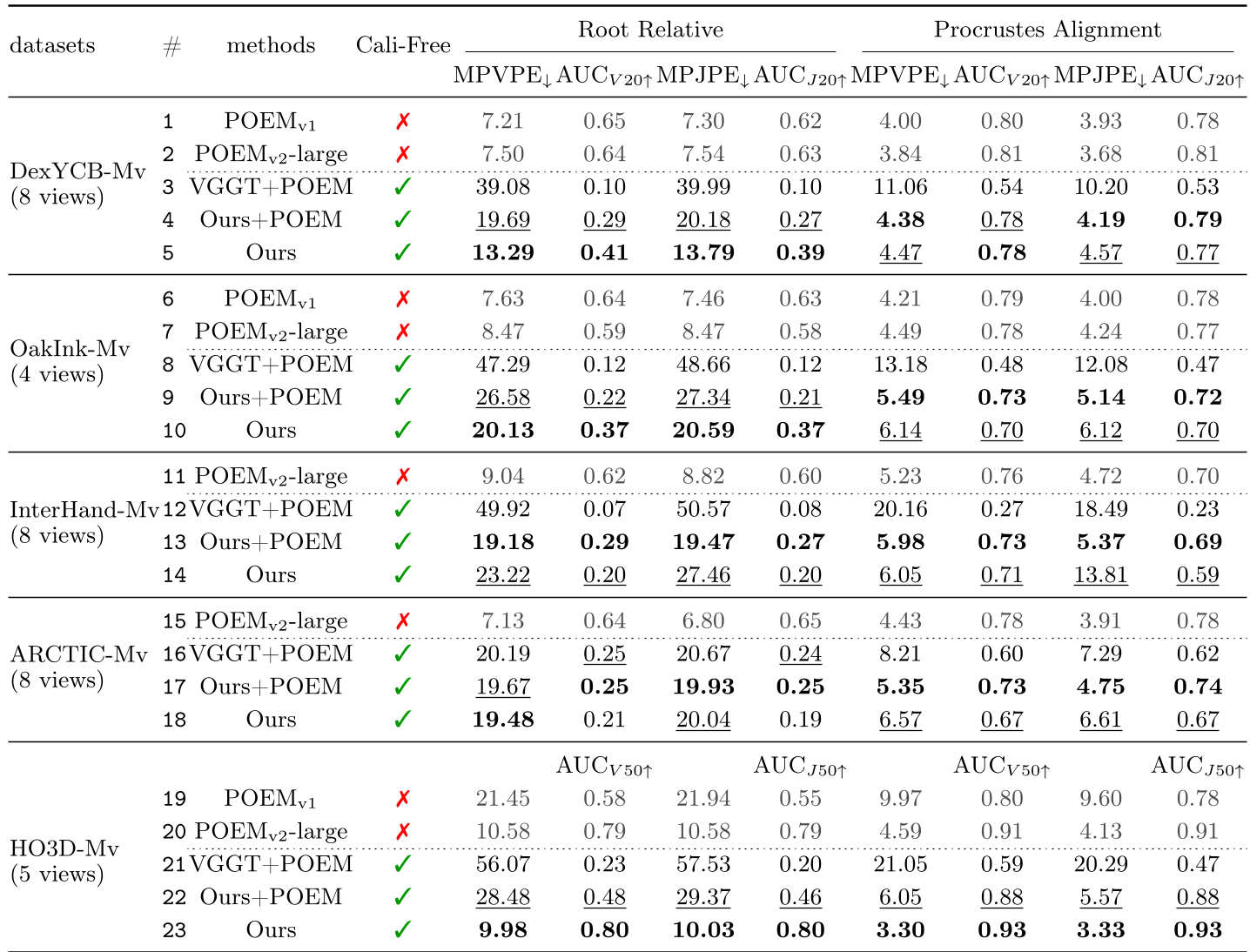 注:即便在未校准设置下(Cali-Free),HGGT 的 MPVPE 指标依然领先。
注:即便在未校准设置下(Cali-Free),HGGT 的 MPVPE 指标依然领先。
4. 极致的鲁棒性
HGGT 表现出了卓越的生存能力。在涉及严重运动模糊(手指快速移动)或严重遮挡(手部被大物体遮住,8 个视角中只有 2 个可见)的极端环境下,模型依然能给出合理的推断。
 图注:上图展示了在运动模糊和极端遮挡下的重建稳定性。
图注:上图展示了在运动模糊和极端遮挡下的重建稳定性。
5. 总结与反思
HGGT 为 3D 手部重建指明了新方向:不再依赖脆弱的硬件校准,而是通过大规模数据和生成式几何先验来补齐不确定性。
局限性:该方法目前仍需依赖外部 2D 检测器进行 Crop 操作,且由于“尺度歧义”,模型暂时无法输出绝对长度(物理单位)的深度,只能在归一化空间内工作。但这已经为未来的全场景、无约束人机交互迈出了一大步。