The paper introduces HiFloat4 (HiF4), a novel 4-bit floating-point format specifically optimized for Huawei Ascend NPUs, for large-scale LLM pre-training. It achieves state-of-the-art (SOTA) efficiency by enabling roughly 90% of storage and GEMM operations in FP4, maintaining competitive accuracy on models like Llama3-8B and Qwen3-MoE-30B.
TL;DR
Huawei researchers have introduced HiFloat4 (HiF4), a specialized 4-bit floating-point format tailored for Ascend NPUs. By leveraging a hierarchical scaling mechanism, HiF4 allows ~90% of LLM pre-training (including Linear and Expert GEMMs) to occur in 4-bit precision. The result? A relative loss error within 1% of BF16 baselines for models up to 30B parameters, with significantly lower stabilization overhead compared to OCP's MXFP4.
Background: The Numerical Wall of LLM Scaling
As we push LLMs toward gazillion-parameter scales, the energy and hardware costs of BF16/FP16 training become unsustainable. While 8-bit (FP8) training is becoming standard, the industry is racing toward 4-bit (FP4). However, FP4 is notoriously unstable. Small errors in gradient quantization lead to "vanishing gradients" or "exploding loss," forcing researchers to use complex tricks like 2D weight quantization or massive high-precision fallbacks that eat away at the theoretical 4x speedup.
Why HiFloat4 is Different: Hierarchical Scaling
The core innovation is the HiF4 format. Unlike MXFP4, which uses a single level of block-wise scaling (usually 32 elements), HiF4 employs a three-level scale:
- Level 1: A global E6M2 scale for a 64-element block.
- Level 2 & 3: Fine-grained 1-bit micro-exponents that adjust smaller sub-groups (8 and 16-way partitions).
This design prevents the "outlier problem"—where one huge value in a block forces all other values to be quantized to zero—by allowing the scaling factor to adapt locally within the block.
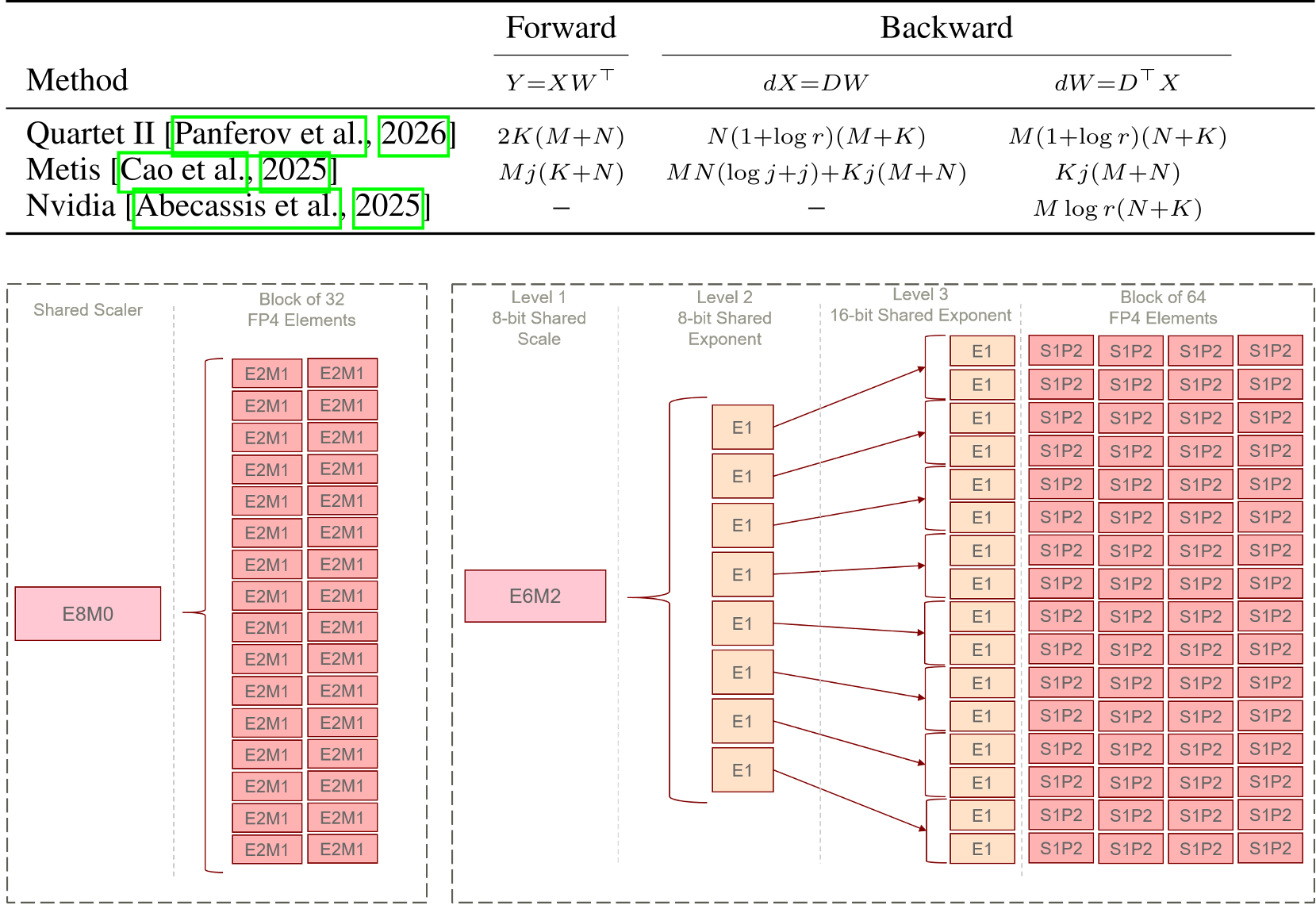 Figure 1: Comparison between (a) MXFP4 block-scaling and (b) HiF4 hierarchical scaling.
Figure 1: Comparison between (a) MXFP4 block-scaling and (b) HiF4 hierarchical scaling.
Methodology: The Minimalist Stabilization Recipe
Precision is only half the battle; the optimization pipeline matters. The authors compared HiF4 against MXFP4 and found a startling difference in "maintenance" requirements:
- MXFP4 stabilization: Requires Stochastic Rounding (SR), Random Hadamard Transform (RHT), and Truncation-Free (TF) scaling to work.
- HiF4 stabilization: Achieves superior results with only RHT applied to weight-gradient computations.
By applying the Hadamard transform, the model redistributes high-energy outliers across the tensor, making the distribution "friendlier" for 4-bit quantization without needing the compute-heavy stochastic rounding for every operation.
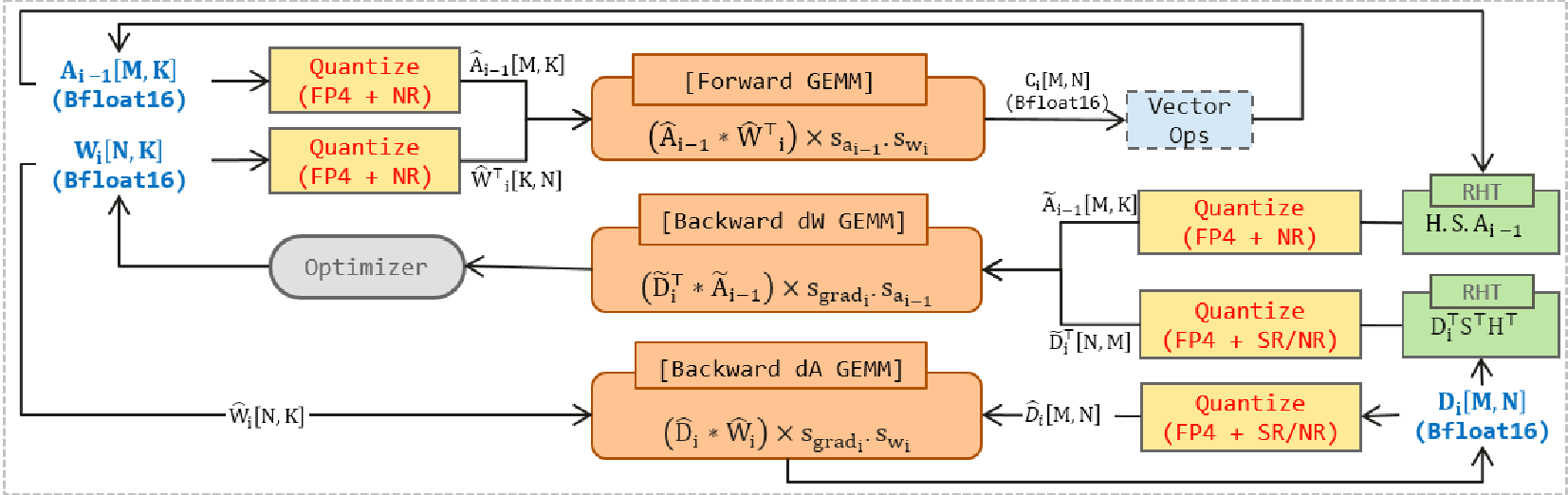 Figure 2: The linearized GEMM workflow showing where RHT and FP4 quantization are injected.
Figure 2: The linearized GEMM workflow showing where RHT and FP4 quantization are injected.
Experimental Performance: Scaling to MoE
The authors tested the format on OpenPangu-1B, Llama3-8B, and the massive Qwen3-MoE-30B. Mixture-of-Experts (MoE) models are particularly sensitive to quantization because of their routing logic.
Key Results:
- Accuracy: HiF4 reduced the relative loss gap to 0.85%-0.88% for 8B and 30B models.
- Efficiency: Over 95% of expert parameters in the MoE model were stored and computed in FP4.
- Convergence: The loss curves for HiF4 (in green below) track the BF16 baseline (in red) much more tightly than MXFP4.
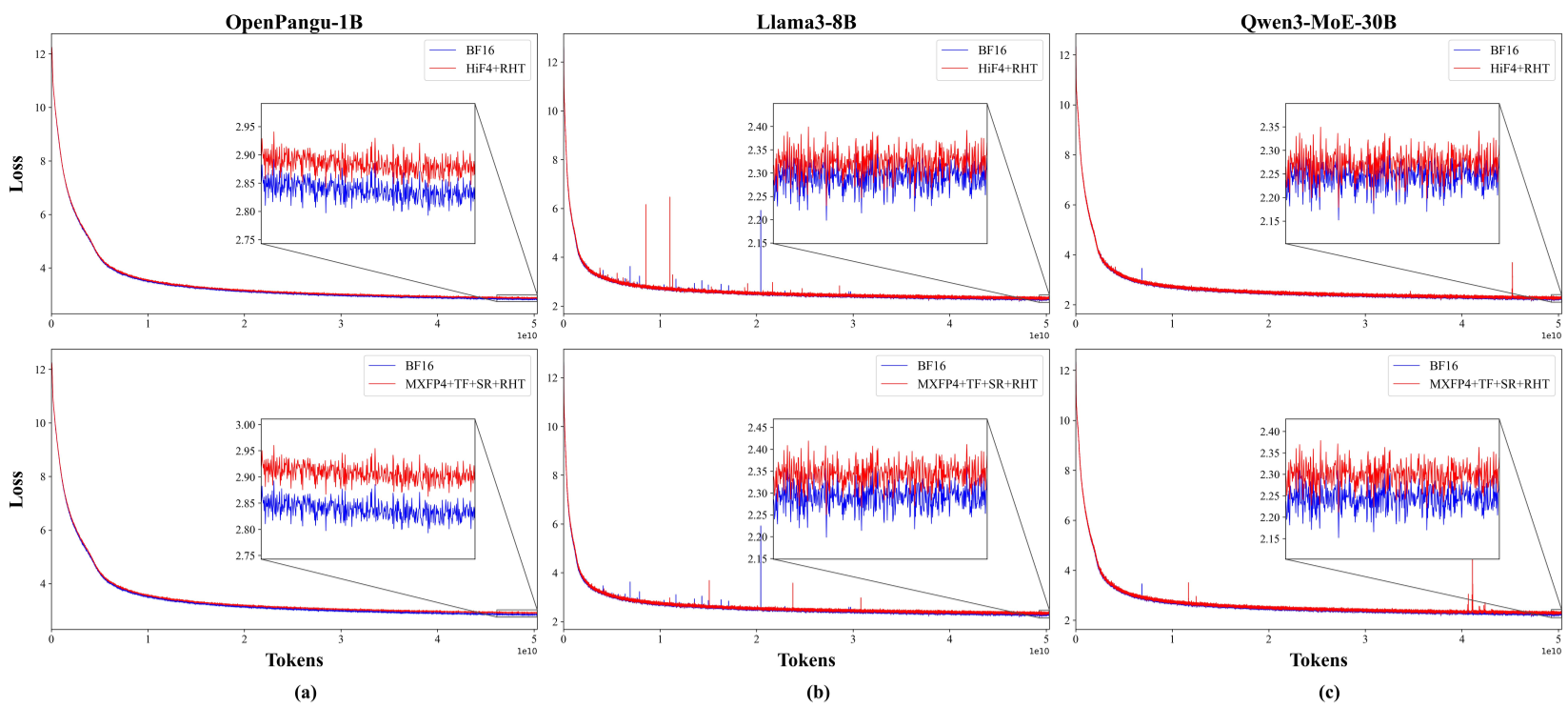 Figure 3: Training dynamics showing HiF4 consistently outperforming MXFP4 in matching the BF16 baseline.
Figure 3: Training dynamics showing HiF4 consistently outperforming MXFP4 in matching the BF16 baseline.
Critical Insight & Conclusion
The significance of this work lies in simplicity. Many recent FP4 papers recommend complex 2D-weight rearrangements or specific "late-stage" precision switching. HiFloat4 proves that if the underlying numerical format is designed with "hierarchical awareness," most of that complexity can be stripped away.
Limitations: The paper focuses on pre-training. How HiF4 handles the high-variance environments of Reinforcement Learning (RLHF) or long-context window extensions remains an open question for future researchers.
Final Takeaway: For those building on the Ascend NPU ecosystem, HiF4 represents a significant step toward making 4-bit training the "default" rather than a research experimental feature.