本文提出了 HiSpatial,这是一个旨在提升视觉语言模型(VLM)3D 空间理解能力的系统性框架。通过将空间智能划分为从几何感知到抽象推理的四个分级水平,并利用自动化流水线构建了包含 500 万张图像和 20 亿 QA 对的海量数据集,HiSpatial 在多项空间推理基准测试中达到了 SOTA 水平。
TL;DR
视觉语言模型(VLM)在 2D 任务上已经登峰造极,但在面对“这个杯子离我多远?”或“如果我绕到桌子后面会看到什么?”这类 3D 空间问题时往往表现拙劣。本文介绍了 HiSpatial,一个通过四级层级任务架构和20 亿规模 3D VQA 数据集系统性提升 VLM 空间能力的框架。即使是 3B 规模的小模型,在空间推理上也击败了 GPT-5 和 Gemini-2.5-pro。
空间智能的缺失:为什么 VLM 总是“没准儿”?
现有的 VLM 主要在 2D 图像-文本对上训练。虽然它们能识别物体,但对于物体的物理属性(尺寸、绝对位置、朝向)缺乏量化的理解。主要痛点在于:
- 缺乏公制感 (Metric Blindness):模型知道物体在图片里的“左边”,但不知道它在现实空间里离相机 2.5 米还是 5 米。
- 认知断层:现有的研究往往只关注单一的空间任务,缺乏从基础几何感知到复杂逻辑推理的进化路径。
核心方法:像人类一样学习空间
作者认为 3D 空间智能不是一蹴而就的,而是由四个相互依赖的认知水平构成的:
1. 四级分级任务模型 (Hierarchical Taxonomy)
- Level 0: 几何感知。不涉及语义,纯粹是像素级的深度查询和排序。
- Level 1: 物体级理解。将语义与几何结合,估计单个物体的尺寸、3D 坐标和朝向 (Yaw)。
- Level 2: 关系理解。理解多个物体间的相对距离和方向向量,构建场景表征。
- Level 3: 抽象推理。最具挑战性的部分,包含视角转换(想像从斜对角看过去的样子)和复杂的空间问题求解。
2. RGB-D VLM 与公制点云图 (Point Map)
为了让模型拥有“标尺”感,HiSpatial 不再使用模糊的相对深度(Relative Depth),而是引入了 Metric-scale 3D Point Map。
- 模型将 RGB 图像与 XYZZ(坐标+Mask)点云特征进行融合。
- 这种设计允许模型直接接触真实的物理尺度,大幅提升了定量预测的精度。
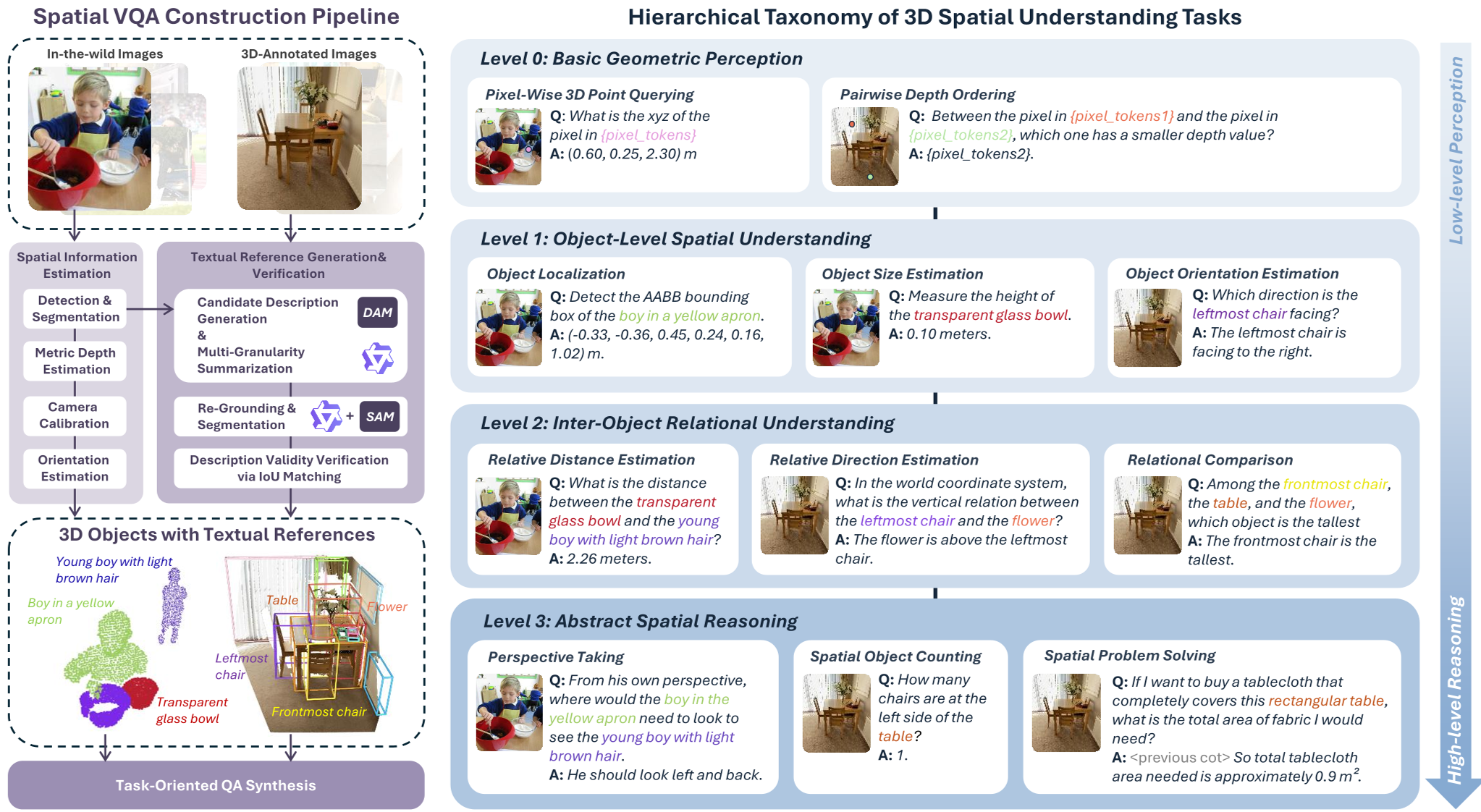 图 1:HiSpatial 数据构建流水线与四级任务分类体系
图 1:HiSpatial 数据构建流水线与四级任务分类体系
实验战绩:以小博大的胜利
HiSpatial 在多个 Benchmark 上展现了统治力:
- 定量任务:在 SpatialRGPT 准确率上,HiSpatial-3B 达到了 79.28%,远超 GPT-4o 的 41.5% 和 GPT-5 的 40.47%。
- 泛化能力:在完全未见过的真实场景测试中(RealWorldQA),HiSpatial 相比基座模型提升了 11% 以上。
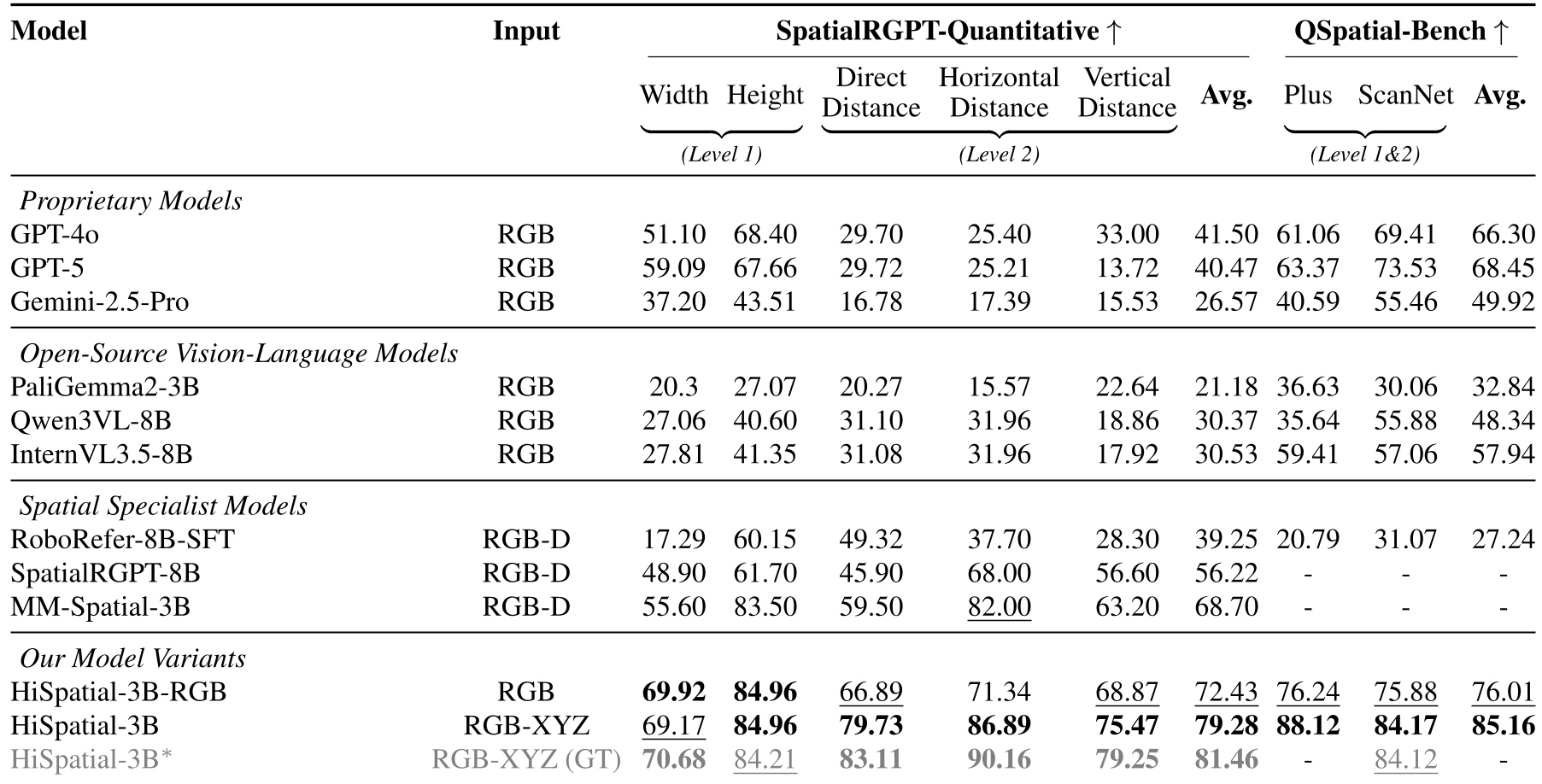 表 1:HiSpatial 与顶级大模型在定量空间任务上的表现对比
表 1:HiSpatial 与顶级大模型在定量空间任务上的表现对比
深度洞察:能力的“级联效应”
本文最有趣的发现是层级依赖性 (Inter-level Dependency): 通过消融实验,作者证明了如果剔除 Level 0 & 1 的训练数据,Level 3 的复杂推理能力会遭遇毁灭性打击。这意味着,没有扎实的底层几何感知,模型无法通过死记硬背学会高层空间逻辑。 这一发现为未来开发具身智能(Embodied AI)提供了核心的方法论指导。
总结与局限
HiSpatial 证明了通过系统性的任务分级和精确的 3D 输入,3B 规模的模型也能拥有顶级的空间智能。尽管目前主要支持单目视频/图像,且语言描述的泛化性仍有提升空间,但它为 VLM 从“平面识图”走向“三维理解”迈出了坚实的一步。
本文由资深学术技术主编重构。