本文推出了 HorizonMath,一个包含 101 个应用数学和计算数学前沿难题的基准测试集。该基准借鉴“生成-验证间隙(Generator-Verifier Gap)”原理,通过 Python 脚本实现自动化验证,旨在评估 AI 在真实数学发现(而非仅是解题)中的潜力。
TL;DR
传统数学 AI 基准已死,HorizonMath 开启了“自动验证数学发现”的新纪元。该 Benchmark 包含了逾百个尚未解决的数学难题,模型不再是复述已知答案,而是被要求直接挑战学术前沿。令人震惊的是,GPT 5.4 Pro 已经在两个经典优化难题中给出了优于人类发表文献(State-of-the-art)的最佳结果,这标志着 AI 正在实现从“解题”到“发现”的跨越。
背景:为什么我们需要 HorizonMath?
在 AI 迈向 AGI 的路径中,数学推理被视为“北极星”。然而,行业面临两大尴尬:
- 数据污染:MATH 和 GSM8K 的题目早已存在于训练语料中,高分往往源于记忆而非推理。
- 评估黑洞:要把 AI 提升到研究生甚至教授水平,必须让它处理 Open Problems。但验证“新发现”通常需要数学家查阅几周,或者写成极难掌握的 Formal Proof(如 Lean 语言)。
HorizonMath 利用了 Generator-Verifier Gap:产生一个复杂的数学构造(如一个满足要求的特殊矩阵)极难,但写个程序检查它是否满足要求却极快。
核心机制:三类“可计算”的未解之谜
HorizonMath 并非直接处理玄奥的逻辑证明,而是将数学研究抽象为三种可工程化评估的形式:
- 闭式解发现 (Closed-form Discovery):给定一个只有数值近似值的数学常数(如 Airy 函数的五阶矩),让 AI 找出一个由 等组成的简洁解析式。
- 基准优化 (A-better-than-B):提供当前学术界最好的边界(Bound),让 AI 构造一个新的数学对象去打破这个记录。
- 存在性构造 (Structural Existence):寻找满足特定对称性或性质的对象(如特定阶数的 Hadamard 矩阵)。
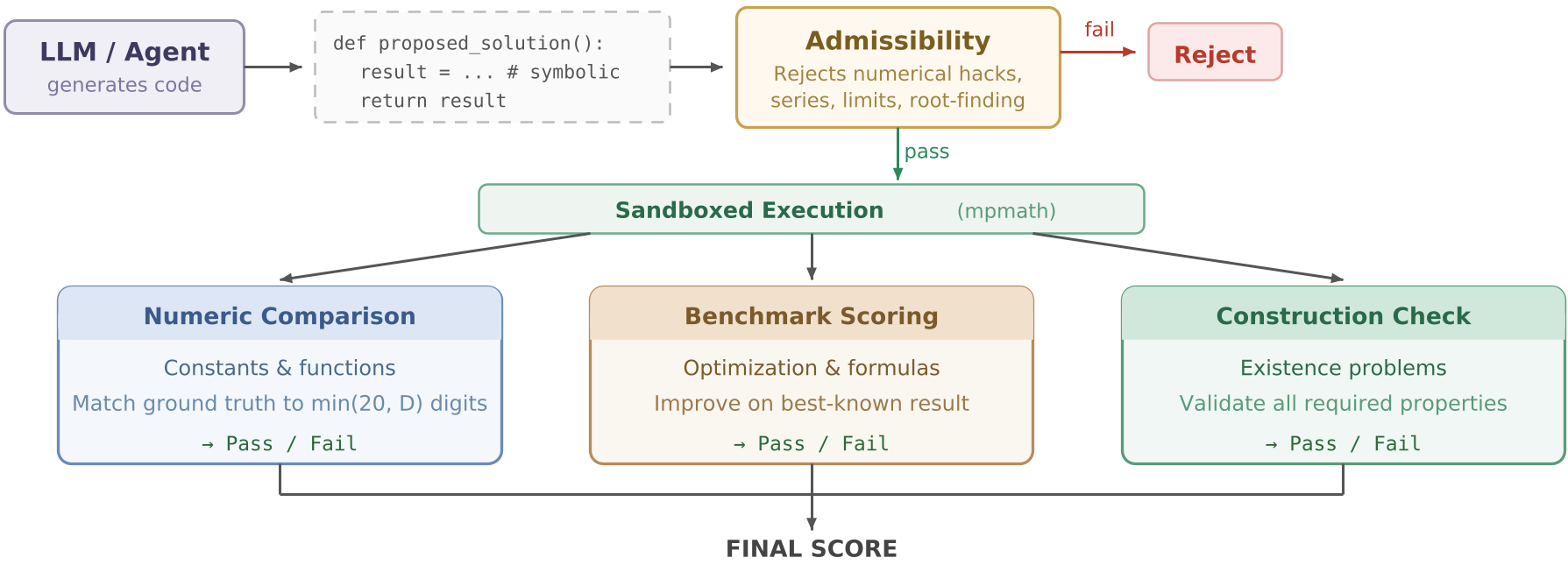 图 1:HorizonMath 自动化评估流水线,包含合规性检查(严禁模型调用数值积分等“作弊”手段)与三大评估模式。
图 1:HorizonMath 自动化评估流水线,包含合规性检查(严禁模型调用数值积分等“作弊”手段)与三大评估模式。
战报分析:GPT 5.4 Pro 的突破性表现
在针对 GPT 5.4 Pro, Gemini 3.1 Pro 和 Claude Opus 4.6 的同台竞技中,结果呈现出显著的层级化:
1. 瘦三角形 Kakeya 问题 (Thin-Triangle Kakeya)
这是一个关于如何以最小面积覆盖所有方向直线的经典几何问题。
- 人类/此前 AI 记录:0.11481 (DeepMind AlphaEvolve, 2025)
- GPT 5.4 Pro 表现:通过一种层级局部搜索算法,构造了 128 个新的截距,将面积降至 0.10915(提升约 4.9%)。
- 意义:这一结果已通过 Mathematica 的精确有理算术验证,属于真正的数学改进。
2. 对角 Ramsey 数 (Ramsey Numbers)
组合数学中的皇冠。GPT 5.4 Pro 挑战了 2024 年由 Gupta 等人提出的渐近上界常数优化。
- SOTA 记录:c ≈ 3.7992
- GPT 5.4 Pro 表现:通过引入五次校正多项式并微调参数,给出了一个 c ≈ 3.6961 的新构造。
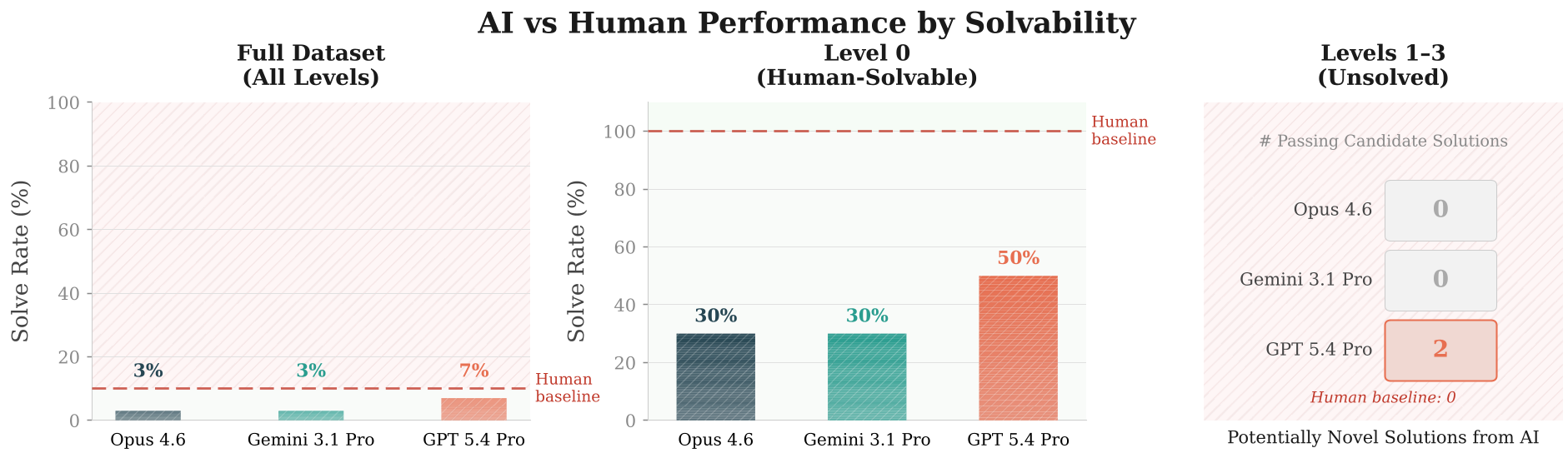 图 2:主流模型在 HorizonMath 上的表现。可以看到,在真正的未解问题(Level 1-3)面前,老一代 SOTA 模型几乎全军覆没。
图 2:主流模型在 HorizonMath 上的表现。可以看到,在真正的未解问题(Level 1-3)面前,老一代 SOTA 模型几乎全军覆没。
深度洞察:为什么这次不一样?
- 零污染保证:由于题目本身在论文发布前没有已知答案,模型不可能通过“背题”获得高分。
- 强制 Python 输出:HorizonMath 不接受自然语言胡诌,必须输出严谨的 Python 函数。这要求模型具备极强的代码实现+数学建模的双重能力。
- 合规性过滤:为了防止模型直接调用
mpmath.findroot等数值工具暴力破解,系统内置了 LLM 审计器,确保结果必须通过数学直觉和公式推导获得。
局限与未来
作者坦言,数值匹配(即使精确到小数点后 20 位)在数学上并不等同于严密的逻辑证明。这些发现目前应被视为**“强有力的猜想(Conjectures)”**。
未来的方向在于将这种“快速发现能力”与 Lean 等形式化验证系统结合——由 AI 提出能跑通数值实验的“正确答案”,再由 AI 尝试自动化证明其正确性。
总结
HorizonMath 是一把尺子,它测量的不再是 AI 有多博学,而是 AI 有多聪明。当 GPT 5.4 Pro 开始在 Ramsey 数这种顶级数学难题上刷榜时,我们必须意识到:AI 已经从实验室的玩具,变成了真正能推动人类认知的生产力。
本博客由资深学术编辑重构。更多论文详情见 arXiv 原文。