本文提出了 HTNav,这是一个专为城市复杂环境设计的无人机空中视觉语言导航(Aerial VLN)框架。该框架核心结合了仿效学习(IL)与强化学习(RL)的混合训练机制,并在 CityNav 基准测试上实现了 SOTA 性能,成功率(SR)相比基线模型提升了一倍以上。
TL;DR
空中视觉语言导航(Aerial VLN)因其在物流配送和城市巡检中的巨大潜力而备受关注。然而,面对复杂的城市拓扑,无人机往往会“迷路”。本文提出的 HTNav 通过分层决策机制和 IL-RL 混合训练策略,在 CityNav 挑战赛中大放异彩,成功率相比主流 MGP 提升了 163%,有效解决了长距离导航中的“认知断层”问题。
背景:为什么空中导航比室内导航难得多?
相比于 R2R 等室内导航任务,城市空中导航面临三个地狱级难度:
- 视野开阔但特征稀疏:在高空俯视时,虽然全局感强,但目标物(如“图书馆前的红车”)可能极其微小。
- 长距离下的累积误差:路径越长,动作序列的微小偏移会导致最终偏离目标数百米。
- 泛化困境:换一个城市,模型往往就无法理解全新的建筑布局。
核心方法论:HTNav 的“大脑”是如何工作的?
1. 分层决策 (Tiered Decision Mechanism)
HTNav 不再试图用一个端到端的网络完成所有事情,而是将其拆解为:
- MacroPlanner (宏观规划者):基于语义地图和指令,生成一系列中间“航点”(Waypoints)。这保证了无人机始终在正确的全局路径上。
- MicroActor (微观执行者):专注于当前的 RGB 观测,执行具体的动作(如:前进、左转、悬停),实现灵活的避障和精准进场。
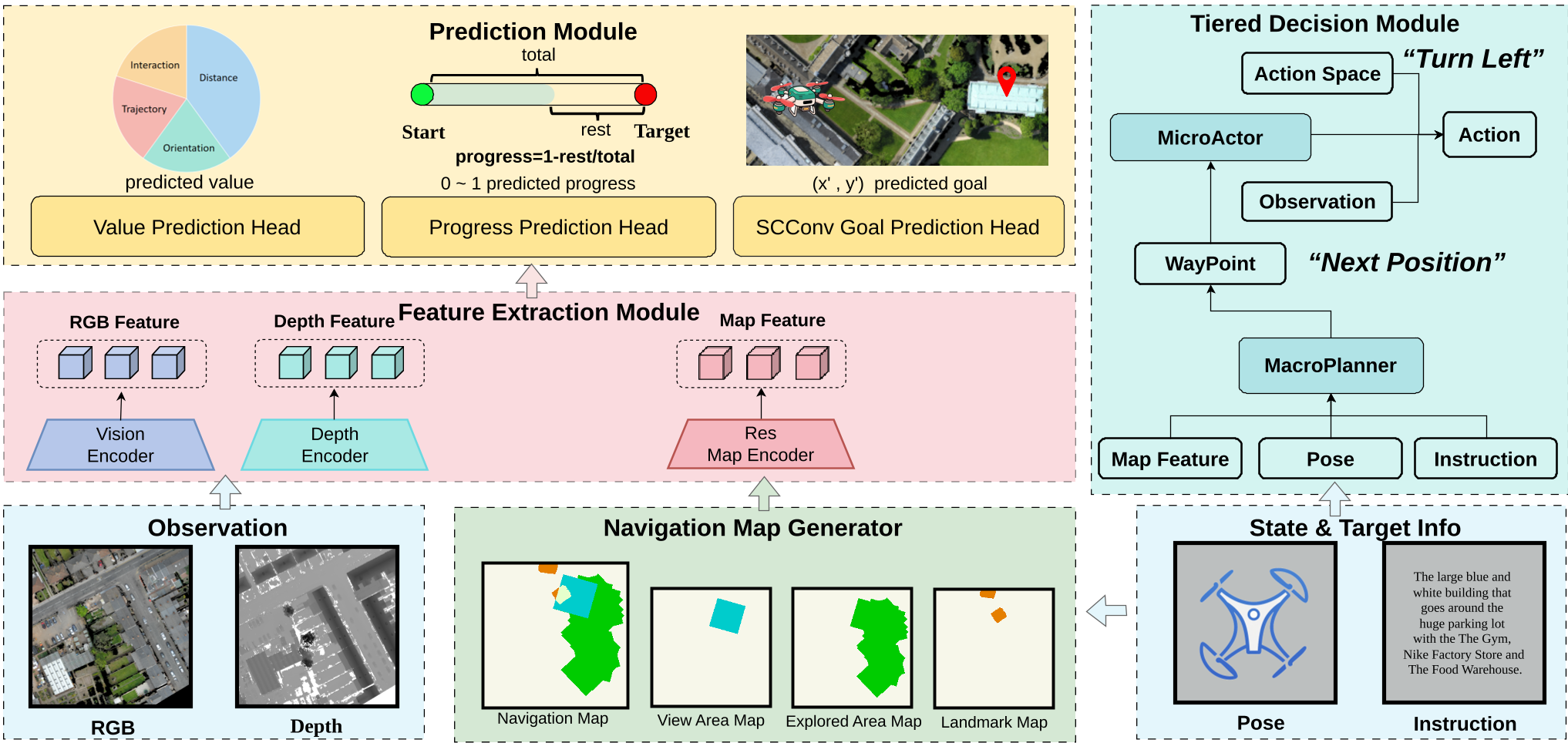 图 1:HTNav 的整体架构,展示了从多模态输入到分层预测的流动过程。
图 1:HTNav 的整体架构,展示了从多模态输入到分层预测的流动过程。
2. 混合训练策略:先模仿,再进化
传统的强化学习(RL)在巨大的城市空间中探索效率极低。HTNav 采用了两步走战略:
- 阶段1 (IL):利用专家轨迹进行仿效学习,预训练出一个具备基本导航能力的 Baseline。
- 阶段2 (RL):引入 PPO 算法,利用 IL 阶段学到的 Value Function 权重初始化 Critic 网络,使无人机在环境中自主探索,通过奖励函数(距离奖励、朝向奖励等)微调策略,从而突破专家数据的分布限制。
3. 强化的地图表征学习
为了更精准地理解空间连续性,作者设计了一个基于 SCConv (Spatial and Channel Reconstruction Convolution) 的地图模块。它能自动识别并抑制地图特征空间和通道维度的冗余信息,让模型更关注关键地标(Landmarks)。
实验战绩:全线 SOTA
在 CityNav 数据集上的对比实验显示,HTNav 在所有难度等级下均表现优异:
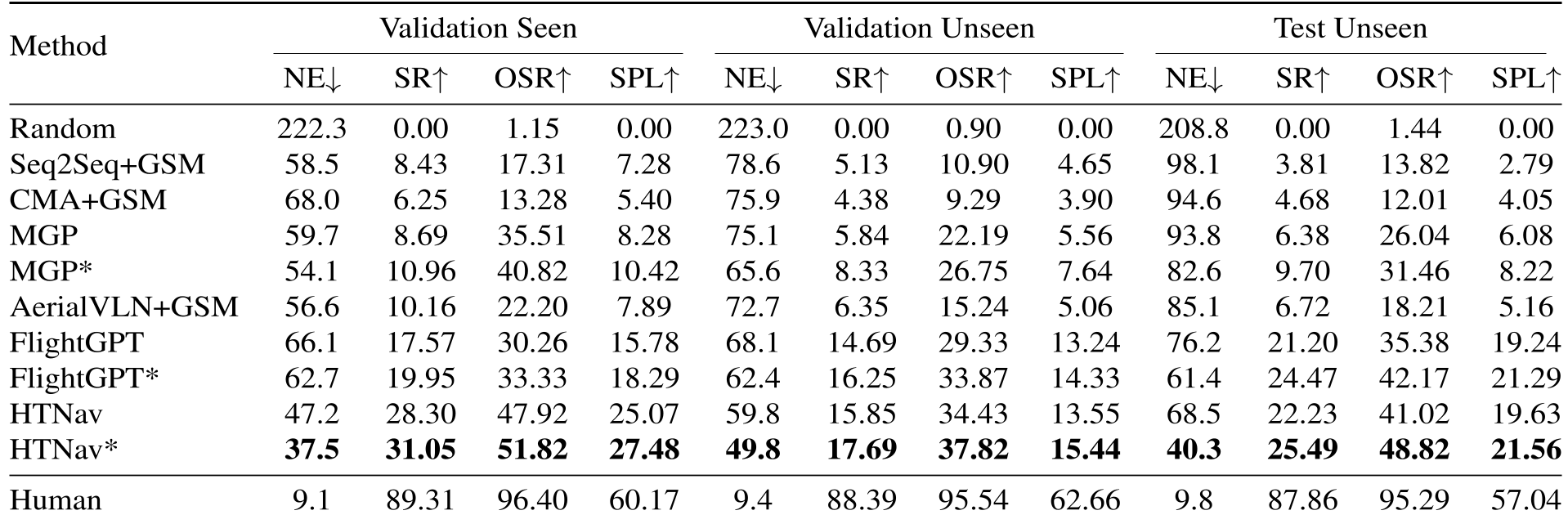 表 1:在 Validation 和 Test 集合上的性能对比,HTNav 在 NE 和 SR 等核心指标上遥遥领先。
表 1:在 Validation 和 Test 集合上的性能对比,HTNav 在 NE 和 SR 等核心指标上遥遥领先。
- 泛化能力:在从未见过的城市场景(Unseen)中,HTNav 的成功率相比 MGP 提升了近 3 倍。
- 路径效率:SPL 指标的显著提升意味着 HTNav 规划出的路径更接近最短路径,减少了无谓的盘旋。
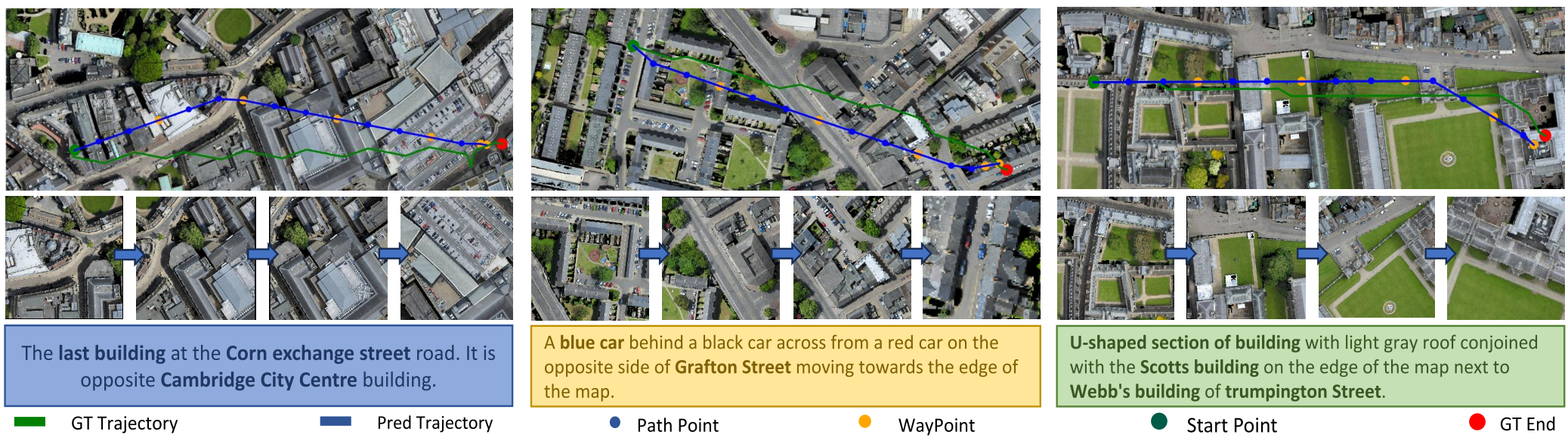 图 2:实际导航轨迹可视化。可以看到 HTNav(深蓝线)能够精准贴合真实路径(红虚线),并成功定位到微小目标。
图 2:实际导航轨迹可视化。可以看到 HTNav(深蓝线)能够精准贴合真实路径(红虚线),并成功定位到微小目标。
深度洞察与总结
HTNav 的成功印证了一个直觉:复杂的具身任务不能仅靠堆算力,更需要合理的任务解耦。
- 分层设计赋予了模型“先看地图再走路”的常识性逻辑。
- 混合训练解决了强化学习从零开始探索的“冷启动”痛点。
局限性:尽管 HTNav 已经大幅超越对比模型,但距离人类 85%+ 的成功率仍有巨大差距。特别是在处理模糊指令(如“往前走一点”)时,模型对自然语言的微小语义波动依然敏感,这可能是未来引入更大规模多模态大模型(VLM)进行决策增强的方向。