本文提出了 Hybrid Memory(混合记忆)范式及 HyDRA 架构,旨在解决视频世界模型在处理动态主体离开并重新进入视野时的连贯性问题。通过在自研的大规模数据集 HM-World 上训练,该方法在保持背景静态一致性的同时,实现了运动主体的 appearance 和 motion 高度统一,达到了新的 SOTA 水平。
TL;DR
在视频生成领域,当一个物体跑出镜头再回来时,现有的 SOTA 模型(如 Llama-Gen, WorldPlay)经常会“断片儿”——回来的物体可能变了样,甚至直接消失。华为华中科大与快手 Kling 团队联合提出的 HyDRA 框架,通过引入 Hybrid Memory(混合记忆) 范式,让模型不仅能记住死背景,还能像追踪器一样预判动态主体的轨迹,实现了极其强悍的运动连贯性。
1. 痛点:被当做“静态画布”的物理世界
目前的视频世界模型研究存在一个明显的“盲点”:它们假设环境是静止的。对于背景(如建筑、道路),通过简单的相机位姿对齐就能维持一致性。但真实世界是动态的。
核心矛盾在于:
- 时空耦合难:扩散模型的 Latent 空间中,背景特征和主体特征是紧紧缠绕的。
- 视野外外推(Out-of-view Extrapolation):当猫咪跑出镜头,模型在后续帧中失去了它的视觉证据。如果此时摄像头转回,模型往往无法“脑补”出猫咪在镜头外的位移,导致猫咪回场时位置突变或动作僵硬。
2. HM-World:首个专注“进出场一致性”的大规模数据集
为了解决数据稀缺问题,作者在 Unreal Engine 5 中构建了 HM-World。
- 规模:59K 高清片段。
- 设计:通过解耦摄像头轨迹(28种)和主体轨迹(10种),人为制造了大量“主体离开-重新进入”的事件。
- 多样性:涵盖 17 种场景和 49 种各异的主体(人、动物等)。
 图 1:数据集生成管线,通过复杂的相机往复运动测试模型的混合记忆能力。
图 1:数据集生成管线,通过复杂的相机往复运动测试模型的混合记忆能力。
3. HyDRA 架构:更聪明的时空检索
HyDRA (Hybrid Dynamic Retrieval Attention) 的核心在于不盲目堆砌历史帧,而是按需检索。
3.1 Memory Tokenizer
模型首先使用 3D 卷积将历史 Latents 压缩成 Memory Tokens。与直接取整帧不同,3D 卷积能在 Token 中编码主体的运动趋势(Velocity/Motion Cues),为后续“脑补”轨迹提供依据。
3.2 动态检索注意力
不同于传统的基于视野重叠(FOV Overlap)的硬检索,HyDRA 采用了一种**动态亲和度(Dynamic Affinity)**机制:
- 对齐:将当前生成的 Query 与 Memory Token 在空间分辨率上对齐。
- 计算:通过元素级乘积和通道缩放,寻找与当前生成内容语义最相关的历史 Token。
- 融合:选取 Top-K 个最相关的 Token 加入 Self-Attention 计算。
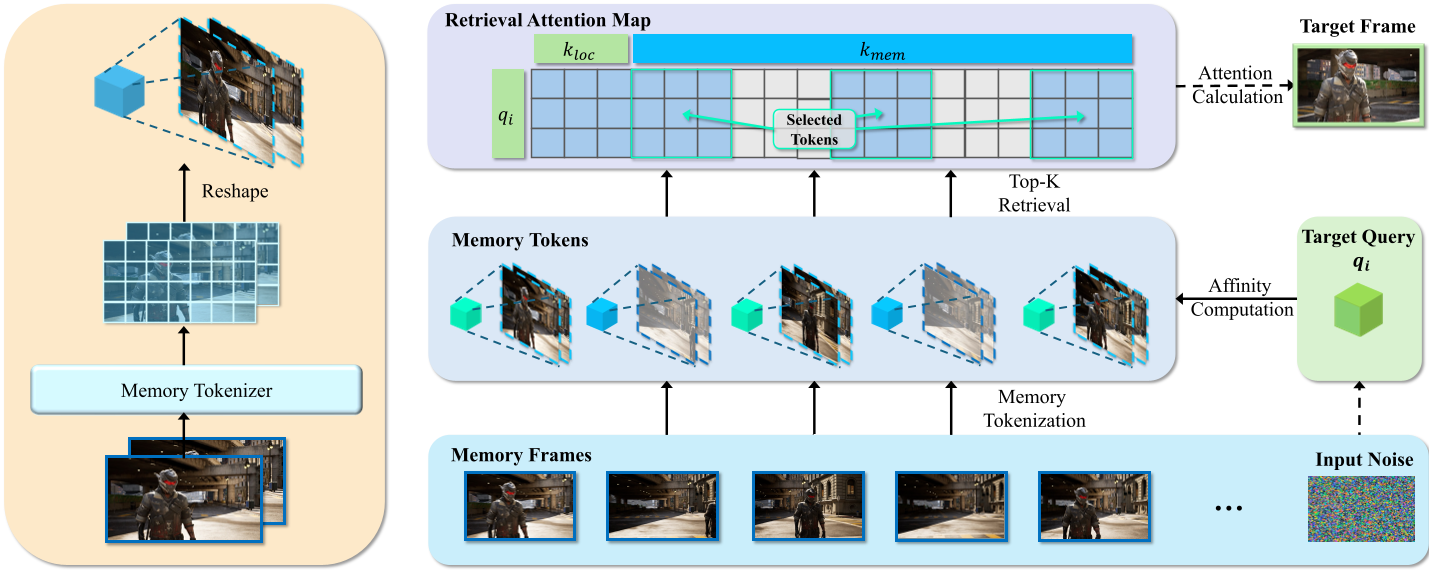 图 2:HyDRA 整体架构,重点展示了 Memory Tokenizer 和检索模块。
图 2:HyDRA 整体架构,重点展示了 Memory Tokenizer 和检索模块。
4. 实验:碾压级的一致性表现
在与主流模型(如 DFoT, Context-as-Memory)的对比中,HyDRA 在所有指标上均实现了霸榜。
- 量化指标:PSNR 相比 Baseline 提升了 1.6+ 分,反映出极高的重建精度。
- DSC(Dynamic Subject Consistency):这是作者提出的新指标,专门利用 YOLO 切割主体并计算 CLIP 特征相似度。结果显示,HyDRA 在主体重新入场后的身份保持能力极强。
 图 3:消融实验对比,可以看到 HyDRA 能够完美复原回场主体的形态,而其他方法出现了消失或形变。
图 3:消融实验对比,可以看到 HyDRA 能够完美复原回场主体的形态,而其他方法出现了消失或形变。
5. 深度洞察
HyDRA 的成功证明了:视频生成不仅是像素的生成,更是物理逻辑的模拟。 传统的 FOV 检索在处理动态物体时效果不佳,是因为它假设物体在 3D 空间中是静止的。而 HyDRA 的动态亲和度检索本质上是在特征层面寻找“因果链”,即便物体在镜头外发生了位移,特征间的关联性依然能引导模型在正确的位置恢复其形态。
局限性:当场景中存在 3 个以上主体或发生严重遮挡时,检索精度仍有下降。未来的方向可能是引入更显式的轨迹预测模块(如结合 Kalman Filter 思想的隐式引导)。
总结:HyDRA 为视频世界模型补齐了“动态记忆”这块拼图。它不仅是一个生成工具,更是向着真正理解物理规律的 AI 迈出的一大步。