本文提出了 HyperEyes,一种并行多模态搜索智能体方案,通过动态融合视觉定位与搜索为原子操作,实现了“搜索更广而非更长”的并行化交互模式。该系统在保持高精度的同时,显著降低了推理成本,在 30B 规模下达到了 SOTA 水平。
TL;DR
多模态搜索智能体(Multimodal Search Agents)正面临一个尴尬的现状:面对一张包含多个物体的图片,它们往往像个新手一样,一个个“手动”抠图、搜索、返回结果,再进行下一次搜索。这种**串行处理(Sequential Processing)**不仅浪费时间,更在冗余交互中积累了大量干扰噪声。
来自小红书和剑桥大学的研究团队提出了 HyperEyes。它的逻辑很简单:Search Wider, Not Longer(搜得更广,而非更长)。通过并行化动作设计与效率感知的强化学习,HyperEyes-30B 在准确率提升的同时,搜索轮数减少了惊人的 5.3 倍,实现了效率与性能的双重 Pareto 优化。
痛点深挖:为什么搜索智能体越来越“啰嗦”?
目前的搜索智能体(如常见的 DeepEyes、VDR 等)在处理复杂视觉查询时,往往陷入两个盲区:
- 交互冗余:当用户问“图中这三个人分别是谁?”时,传统模型会进行 3 轮独立调用。每轮都要重新推理、调用工具、读取长达数千 Token 的网页结果。
- 过度搜索(Over-searching):现有的 RL 训练目标往往只有“结果准确率”。为了刷分,模型倾向于无限制地调用搜索工具,这导致 Token 消耗爆炸。
作者犀利地指出:准确率不低,但代价太大。 现有的评估体系只看分,不看耗,掩盖了推理成本这一“隐形成本”。
核心技术:UGS 动作空间与双粒度效率 RL
1. 统一接地搜索 (Unified Grounded Search, UGS)
为了打破“先截图再搜索”的死循环,HyperEyes 将视觉定位(Visual Grounding)和检索合二为一。模型可以在单次 tool_call 中同时提交多个 Bounding Boxes(检测框)和多个文本 Query。这种“地毯式”搜索在第一轮就拿回了所有必要信息,把交互深度转化为了搜索广度。
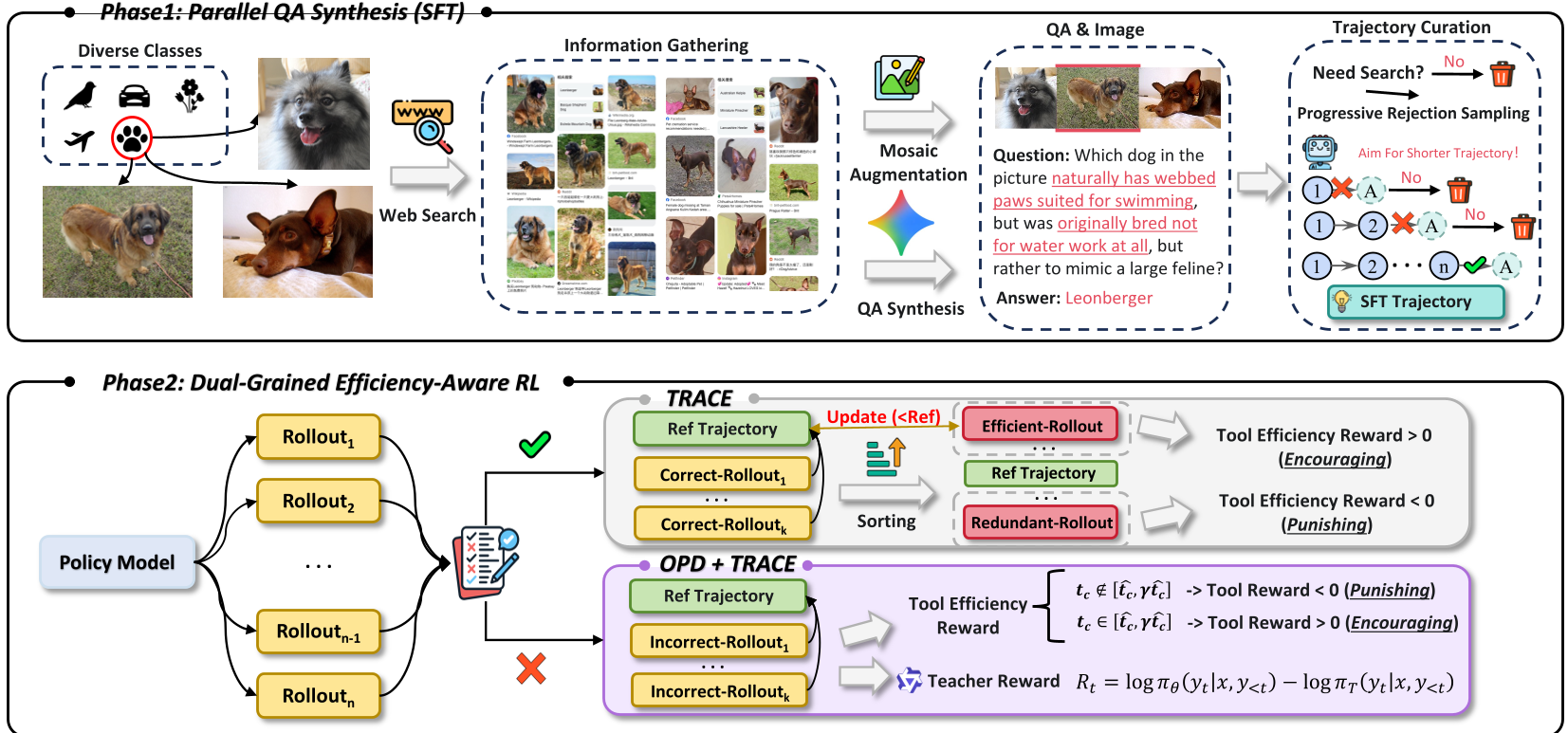 图 1:HyperEyes 训练框架概览,包含并行数据合成与双粒度强化学习
图 1:HyperEyes 训练框架概览,包含并行数据合成与双粒度强化学习
2. TRACE:会动态“进化”的奖励机制
为了限制模型的“啰嗦”,作者提出了 TRACE (Tool-use Reference-Adaptive Cost Efficiency)。
- 不仅仅是惩罚:单纯惩罚调用次数会损害模型处理复杂问题的能力。
- 动态收紧:TRACE 会在训练过程中,根据当前模型已经达到的最佳效率表现,不断收紧“满分指标”。如果你上一轮用 4 次搜索答对了,这一轮用 5 次就只能拿低分。这种机制逼迫模型向“极简主义”进化。
3. OPD:让大模型教小模型如何“快准狠”
由于搜索反馈是稀疏的(只有最后对不对),模型很难知道是哪一步搜错了。On-Policy Distillation (OPD) 将 235B 规模的强力教师模型的 Token 级信号注入到 30B 学生模型中。这种微观层面的纠偏,让学生模型学会了更精准的推理路径。
实验战绩:开源界的效率天花板
为了证明这一套方法真的实用,研究者推出了 IMEB (Image Multi-Entity Benchmark) 榜单。这是首个将“推理成本”列为一级指标的基准。
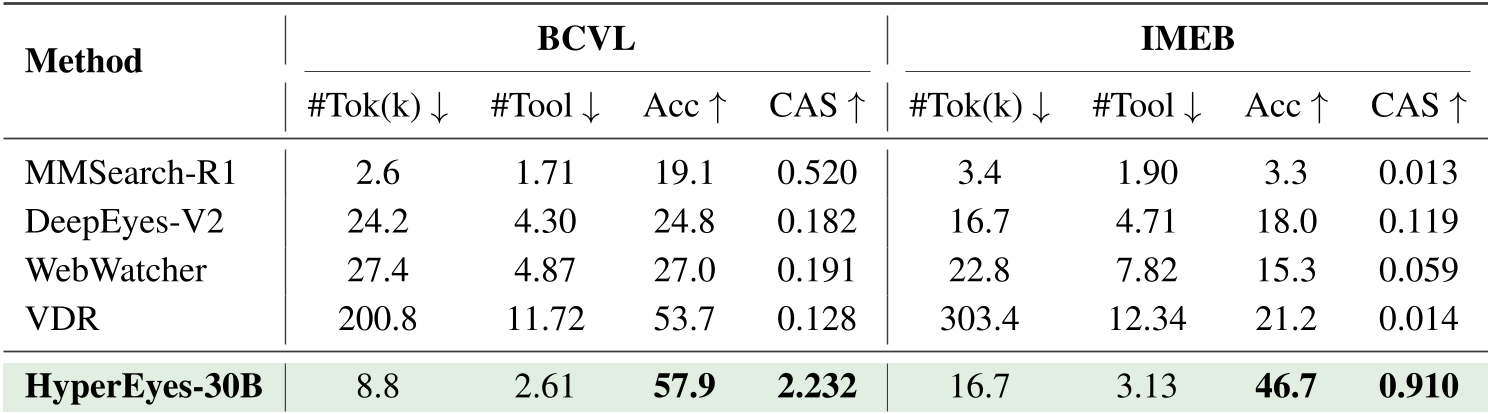 表 3:在成本感知分数 (CAS) 衡量下,HyperEyes 展现出压倒性优势
表 3:在成本感知分数 (CAS) 衡量下,HyperEyes 展现出压倒性优势
- 全方位碾压:HyperEyes-30B 在 MMSearch、LiveVQA 等六个基准上平均表现优异。在多实体复杂任务中,搜索轮数从 VDR 的 11.6 轮骤降至 2.2 轮。
- CAS 指标优势:引入考虑 Token 消耗和调用轮次的 CAS 分数后,HyperEyes 比同规模模型领先数倍。这说明它不是靠“堆算力”赢的,而是靠“高智商”赢的。
深度洞察:并行化是 Agent 的未来吗?
HyperEyes 的成功给行业留下了几个深思点:
- 信噪比的悖论:实验证明,搜索次数越多,准确率反而可能下降(见原文 4.2 节分析)。这是因为冗余信息带来了更多干扰项。HyperEyes 通过“一次性拿对证据”,反而提高了决策稳定性。
- 小模型的逆袭:通过 OPD 蒸馏,30B 级别的模型在搜索任务上能爆发出接近 235B 甚至闭源模型(如 Claude-4.6, Kimi-K2.5)的战斗力。
局限性
尽管 HyperEyes 在静态多模态搜索上表现强悍,但对于动态视频流或有时序要求的任务,并行的 UGS 机制可能需要更复杂的逻辑来处理实体间的因果关系。
总结
HyperEyes 标志着多模态智能体从“能跑通”向“能商用”迈出的一大步。它告诉我们,真正的智能不应该是在复杂的搜索工具中迷失方向,而是在一眼洞穿需求后,以最高效的动作直达终点。
致读者:如果你正在开发 RAG 或搜索类 Agent,HyperEyes 提出的“效率感知 RL”和“并行动作空间”非常值得在生产环境中借鉴。