This paper introduces CaOPD (Calibration-Aware On-Policy Distillation), a framework designed to solve the systematic overconfidence in Large Language Models (LLMs) during post-training. By decoupling capability cloning from confidence supervision, the authors achieve SOTA calibration (ECE and Brier Score) while matching or exceeding the task accuracy of standard on-policy distillation (OPD) methods.
TL;DR
Standard post-training techniques (like On-Policy Distillation) make LLMs smarter but also more "arrogant"—they become extremely confident even when they are wrong. This paper introduces CaOPD, a framework that fixes this by decoupling what a model answers from how certain it is. The result? A compact 8B model can achieve the reliability of a frontier GPT-level model in a single forward pass.
The "Scaling Law of Miscalibration"
As LLMs scale from 0.6B to 32B parameters, you would expect them to become more self-aware. Paradoxically, the opposite happens. The authors identify a "Scaling Law of Miscalibration": while models get better at the task, they get worse at judging their own success. They are trapped in the "Overconfidence Zone," reporting 99% confidence for answers they fail 40% of the time.
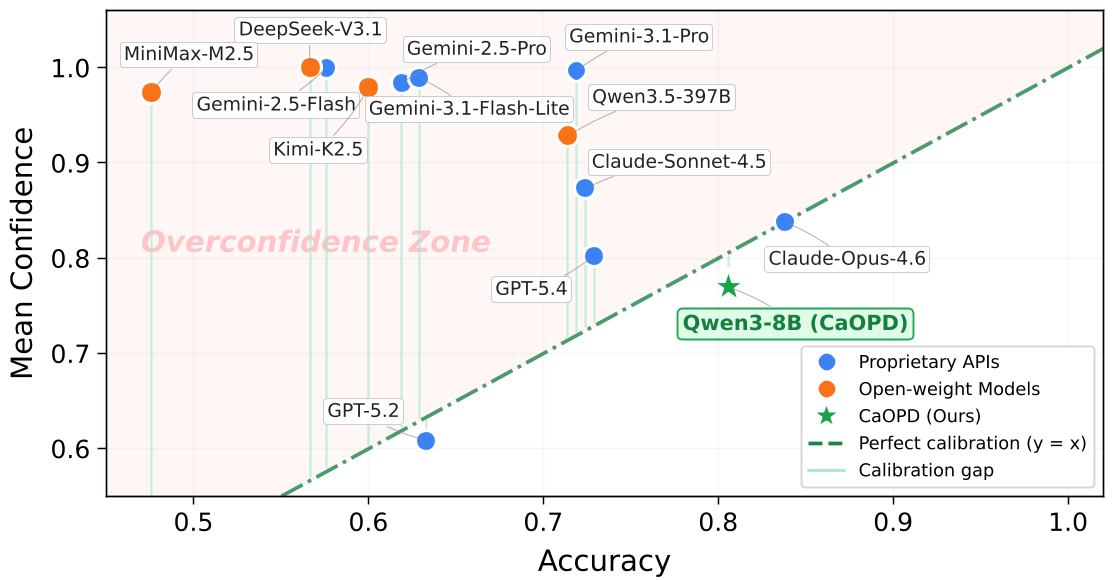
Why Does This Happen? (The Information Gap)
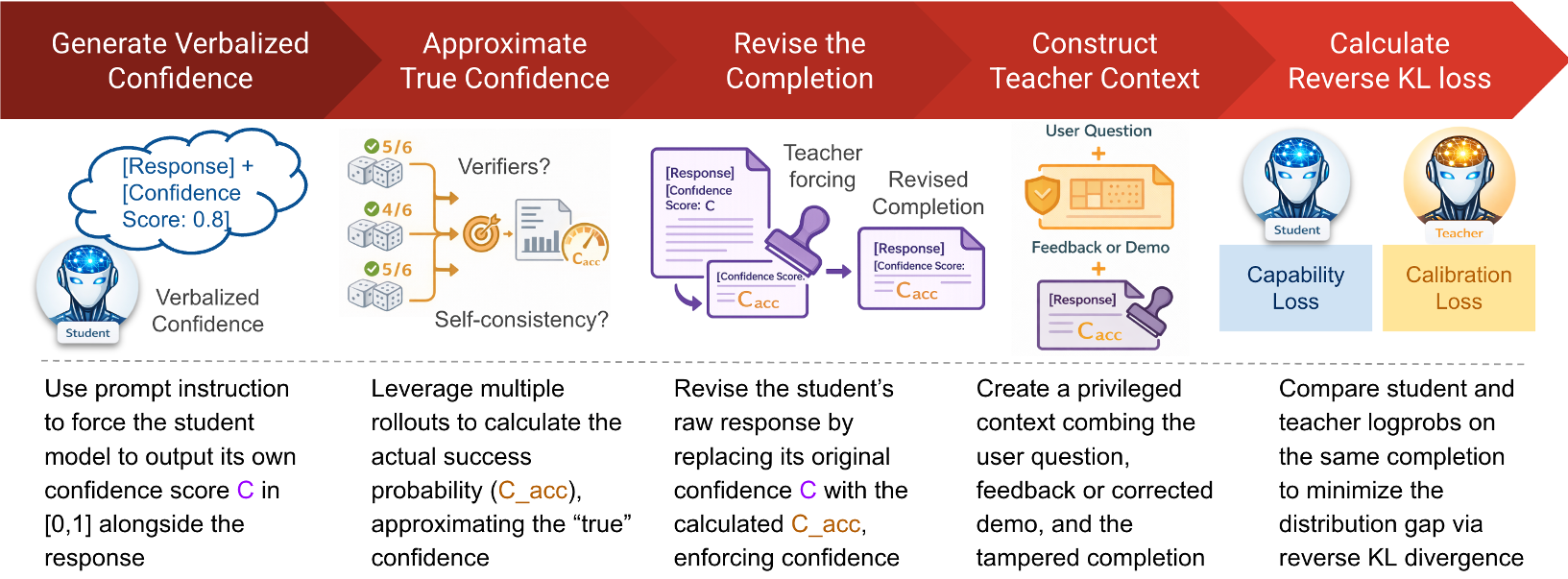
The root cause is Information Asymmetry. During training (On-Policy Distillation), the "Teacher" model has access to a "cheat sheet" (privileged context like the correct answer or environment feedback).
- The Teacher: Sees the answer $\rightarrow$ is 100% certain.
- The Student: Tries to mimic the teacher's behavior but without seeing the answer.
In trying to be like the teacher, the student learns to mimic the teacher’s tone (absolute certainty) without having the evidence. This leads to Entropy Collapse (logits becoming artificially sharp) and Optimism Bias (learning only the "voice of a winner").
Methodology: The CaOPD Solution
Instead of fighting the optimizer with complex RL rewards (which often hurts accuracy), CaOPD uses Target Replacement.
- Empirical Estimation: The model generates multiple "practice" answers (rollouts). We check how many are actually correct.
- Target Decoupling: If the model only gets the answer right 50% of the time during practice, we manually change its training target. Even if the Teacher says "I'm 100% sure," we force the Student to learn "I'm 50% sure."
- Amortization: By training on these realistic scores, the model internalizes its actual competence. At test time, it doesn't need to practice anymore; it "just knows" its limits in one shot.
Experimental Results: Calibration without the "Capability Tax"
Existing methods like RLCR often make models "scared"—the model becomes so afraid of being overconfident that its actual accuracy drops. CaOPD avoids this "Capability Tax."
- Accuracy: CaOPD matches or exceeds standard distillation (SDFT/SDPO).
- Reliability: It pushes the Pareto frontier, meaning you get better calibration for the same amount of "intelligence."
- Strict Pairwise Ranking (SPR): Standard models often "tie" their confidence (everything is 1.0). CaOPD restores the model's ability to rank its own answers—correct answers finally get higher scores than wrong ones.
Deep Insight: Generalizable Meta-Skills
One of the most impressive findings is that CaOPD doesn't just memorize the "vibe" of a dataset. It learns a meta-skill. When moved to a completely new domain (Out-of-Distribution), CaOPD-trained models remain calibrated, whereas standard models immediately collapse back into blind optimism. It also prevents "calibration forgetting" during continual learning.
Conclusion & Perspective
The industry's obsession with capability (getting the right answer) has blinded us to calibration (knowing when the answer is right). CaOPD provides a mathematically sound, non-invasive way to build "Honest AI."
For developers, this means we can finally use small, calibrated models as routers. If a 7B model is 90% sure, take the answer; if it's 20% sure, escalate the query to a 400B model. This "Cascade Routing" could drastically reduce the cost of running trustworthy AI systems in production.