本文系统评估了前沿大语言模型(LLMs)作为智能体(Agents)时的随机采样能力。通过对 Gemini, Qwen3 和 OLMO-3 等模型在离散/连续均匀分布及高斯分布下的测试,揭示了 LLMs 在独立采样时普遍存在的分布偏见和位置偏见。
TL;DR
在评估 LLM 作为 Agent 的决策能力时,我们通常关注其逻辑推理,却忽略了一个更基础的能力:随机采样 (Stochastic Sampling)。Google DeepMind 的最新论文《The Illusion of Stochasticity in LLMs》指出,即使是最强大的模型(如 Gemini 3.0 Pro 或 Qwen3),在被要求“随机选一个数”时,表现得更像是被偏见支配的复读机,而非真正的随机发生器。
背景定位:Agent 决策中被遗忘的角落
当 LLM 被部署为智能体时,它不仅要能推理,还要能执行随机化策略。例如:
- 在多选题中提取答案位置以防作弊。
- 在强化学习任务中进行探索空间 (Exploration)。
- 在博弈论任务(如石头剪刀布)中保持策略不可预测。
然而,作者发现 LLM 存在严重的知行差距:它们能准确描述什么是“均匀分布”,但在执行时却会由于训练数据的频率偏见,疯狂输出数字“7”或“42”。
核心痛点:为什么 LLM 不会扔硬币?
目前的 LLM 采样是通过对词表(Vocabulary)的 Logits 进行多项分布采样。这种机制与我们期望的“动作采样”之间缺乏一一映射。
- 分布偏见 (Distributional Bias):模型偏爱 7, 42 等“流行”数字。
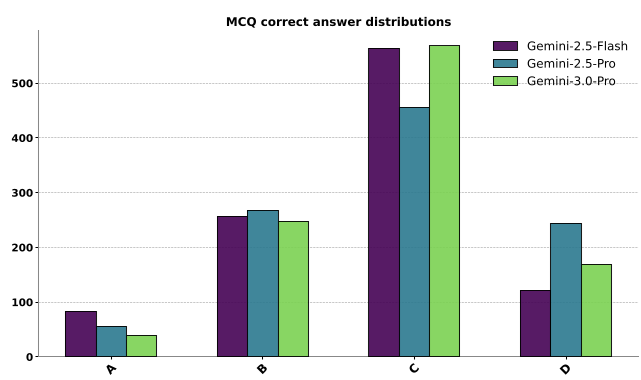
- 位置偏见 (Positional Bias):如果让模型从 {A, B, C, D} 中选,它会由于 Prompt 中的顺序而产生显著偏移(如下图所示,模型严重倾向选择位置 C)。
实验解析:采样能力的全面崩塌
1. 独立采样的失败
作者对不同规模的模型进行了 Kolmogorov-Smirnov 和 Chi-Square 检验。结果令人沮丧:无论模型多大,甚至通过思维链 (CoT) 进行铺垫,其输出的经验分布与目标分布的 p-value 几乎全部为 0。
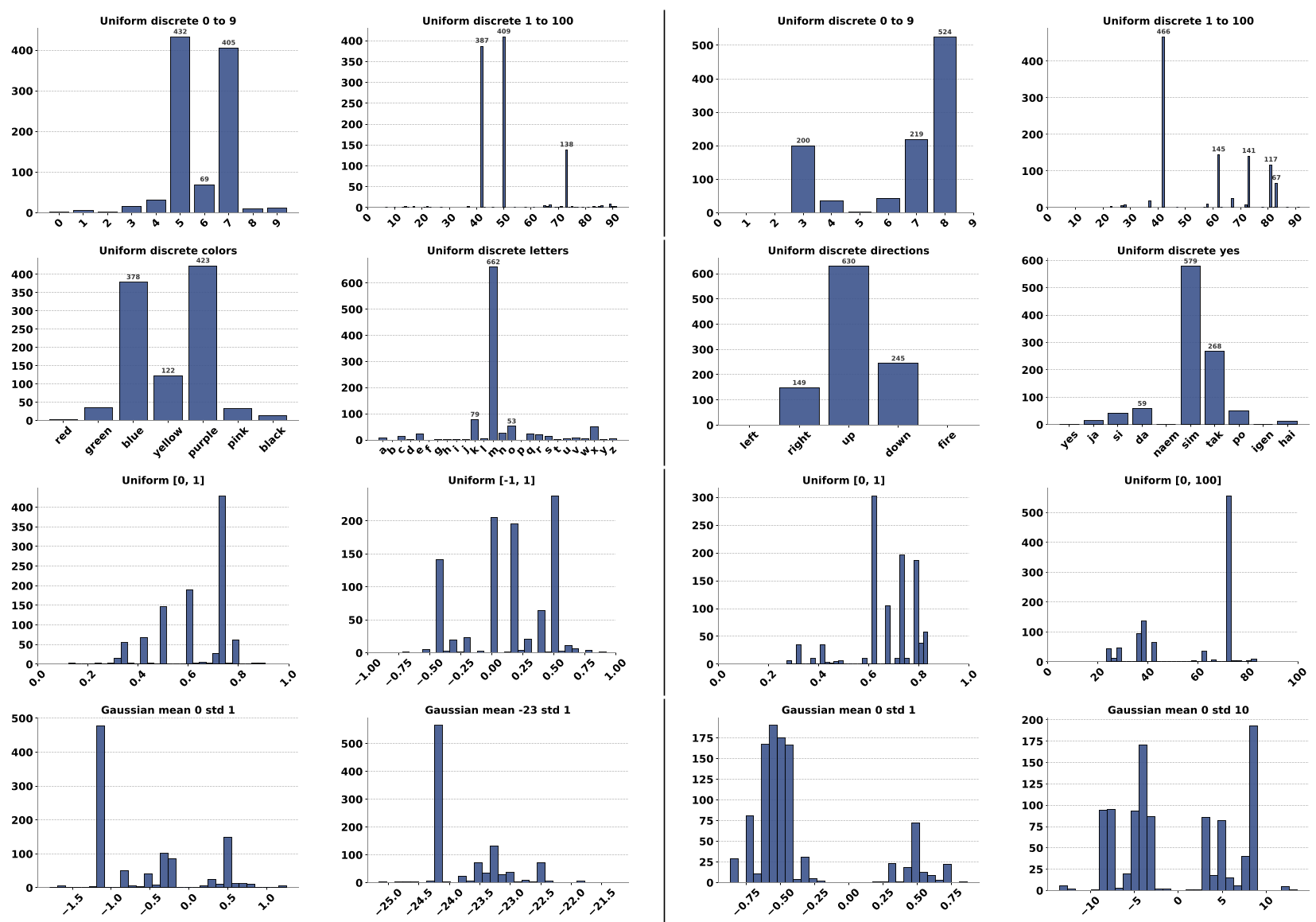
图注:上图展示了 Qwen3 和 Gemini 在试图生成均匀分布时的惨状,波峰明显偏向某些特定数值。
2. 解码参数的无力
有人可能会说:“调高 Temperature (温度系数) 不就行了?” 实验证明,增加温度确实会让分布变平坦,但在极高温度下,模型会开始产生解析错误(无法放入指定的 \boxed{} 中),且核心偏见依然存在。
破局之道:从“生成随机”到“转换随机”
论文最深刻的洞见在于:LLM 不擅长产生随机性,但极其擅长处理确定的转换逻辑。
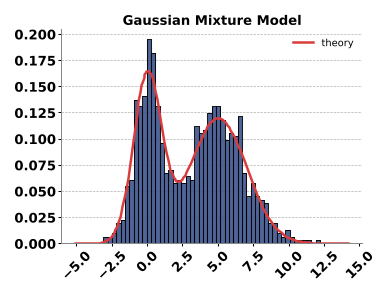
作者尝试给模型一个来自外部 Python 环境的真正随机数 ,然后要求模型将其转换为目标分布(如高斯分布)。在这种情况下,模型表现出了惊人的涌现能力 (Emergent Property):
- 只要模型规模超过 4B,它们就能利用逆变换采样 (Inverse Transform Sampling) 或桶算法 (Bucketization) 精确完成任务。
- 这种转换是一个确定性过程,避开了 LLM 内部采样的逻辑缺陷。
深度洞察与总结
结论 (Takeaway)
- 不要让模型“自己想”一个随机数:这在安全性或公平性要求高的场景(如抽奖、分配任务)中是不可接受的。
- 工具化是唯一出路:未来的 Agent 架构必须包含一个状态化的采样工具 (Stateful Sampler),由 LLM 提供转换逻辑,由外部系统提供高质量种子。
局限性与挑战
虽然 LLM 擅长转换分布,但当转换逻辑变得极其复杂(如涉及大数乘法的 PRNG 模拟)时,模型依然会因为计算精度问题而失败。
未来展望
这项工作揭示了 Transformer 架构在模拟随机系统方面的固有缺陷。未来是否可能通过专门的随机性对齐预训练(如 Fourier Head)来让模型真正“掌握”概率分布,将是一个值得研究的高价值方向。
编辑点评:这篇论文打破了我们对大模型“灵活性”的盲目崇拜。它告诉我们,在通往 AGI 的道路上,有些基础的数学特性(如纯粹的随机性)仍需依赖传统计算架构的辅助。