The paper introduces Vision Banana, a generalist vision model created by instruction-tuning the Nano Banana Pro image generator. It reframes various vision tasks as image generation by parameterizing output spaces (like depth and segmentation) into RGB images, achieving state-of-the-art results on 2D and 3D understanding tasks.
Executive Summary
TL;DR: Researchers have long suspected that the ability to create a world implies the ability to understand it. Vision Banana proves this by instruction-tuning the Nano Banana Pro (NBP) image generator. By simply teaching the model to output perception masks and depth maps in decodable RGB formats, it surpasses domain-specific "specialists" like SAM 3 and Depth Anything 3.
Context: This work marks a potential paradigm shift. While the field has relied on specialized "discriminative" models (like DINO or CLIP) for understanding, Vision Banana suggests that generative pretraining is the true path to a foundational Vision Model, mirroring how GPT unified natural language processing.
The Core Insight: Perceptual "Formatting"
The primary bottleneck for using image generators for perception has been their "creativity." Ask a standard diffusion model for a "depth map," and it might give you something that looks right but lacks the mathematical precision for metric evaluation.
The authors solve this by treating perception as a language-to-vision formatting task.
- Lightweight Instruction-Tuning: Instead of retraining the whole model, they "align" it with a small ratio of vision data.
- Invertible RGB Mapping: For continuous values like metric depth, they use a power transform and a 3D Hilbert-curve interpolation to map [0, ∞) distances to [0, 1] RGB space. This allows the model to "paint" depth values that can be mathematically decoded back to meters.
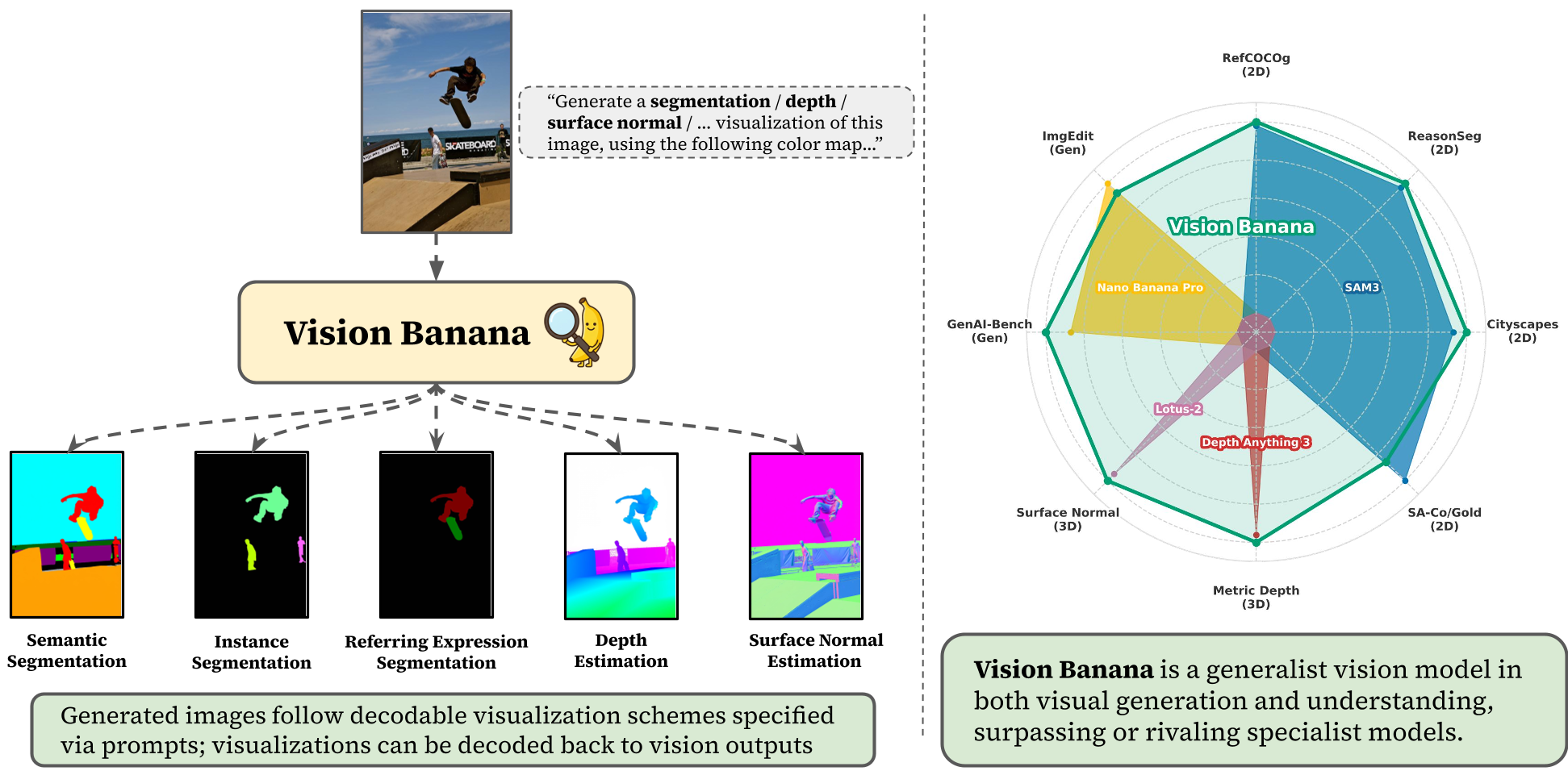 Figure 1: Reframing perception as image generation via precise instruction following.
Figure 1: Reframing perception as image generation via precise instruction following.
Methodology: Perception as a Unified RGB Interface
The genius of the approach lies in its simplicity. Whether it is segmentation or 3D geometry, the output is always an RGB image.
2D Scene Understanding
For Semantic Segmentation, the model is prompted with a JSON-like mapping (e.g., "cat": "red"). For Instance Segmentation, where the number of objects is unknown, the model is instructed to assign unique colors to each distinct instance dynamically. This leverages the model's internal understanding of object boundaries developed during its generative pretraining.
3D Metric Depth
Traditional models often fail to capture absolute scale without camera intrinsics. Vision Banana uses its vast "world knowledge" to infer that a person at a certain pixel height is likely a specific distance away.
- The Transform:
- The Result: High-fidelity surfaces that can be unprojected into consistent 3D point clouds.
 Figure 2: Vision Banana vs. Lotus-2. Note the significantly higher granular detail in the surface normal maps.
Figure 2: Vision Banana vs. Lotus-2. Note the significantly higher granular detail in the surface normal maps.
Experiments: Beating the Specialists
The results in the table below show a clear trend: Vision Banana often rivals or beats models that were built exclusively for a single task.
| Task | Benchmark | Vision Banana | Previous SOTA (Specialist) | | :--- | :--- | :--- | :--- | | Semantic Seg. | Cityscapes (mIoU) | 0.699 | 0.652 (SAM 3) | | Metric Depth | Avg 4 Datasets (δ1) | 0.929 | 0.918 (Depth Any. 3) | | Ref. Seg. | ReasonSeg (gIoU) | 0.793 | 0.770 (SAM 3 Agent) |
Retention of Generative Power
A critical risk in instruction tuning is "catastrophic forgetting." The authors tested Vision Banana on GenAI-Bench, and it achieved a 53.5% win rate against its base model, Nano Banana Pro. This confirms that perception capabilities can be unlocked without degrading the artistry of the generator.
Critical Analysis & Future Outlook
Why does it work?
- The Mode-Seeking Advantage: Generative models learn the full distribution of data. While discriminative models might collapse into a "blurry mean" when faced with ambiguous inputs, Vision Banana naturally handles multiple potential interpretations of a scene.
- World Priors: Because the model was trained to generate realistic shadows, textures, and occlusion, it already "knows" 3D geometry. The instruction-tuning merely provides the "alphabet" to communicate that knowledge.
Limitations
- Inference Speed: Running a full-scale image generator for a single segmentation mask is computationally more expensive than traditional lightweight ConvNets.
- Ambiguity in Instance Colors: Occasionally, the model might choose colors too similar to distinguish between adjacent instances without post-processing.
Conclusion
Vision Banana suggests we are entering an era of "Omni-Vision" models. Much like how we no longer train separate language models for translation, summarization, and coding, we may soon stop training separate models for depth, segmentation, and generation. Image generation has become the universal language of computer vision.