本文推出了 IMPLICITMEMBENCH,这是首个专门评估大语言模型(LLM)“隐性记忆”(Implicit Memory)的系统性基准测试。该框架涵盖程序性记忆、启动效应和经典条件反射三大维度,发现即便如 DeepSeek-R1 (65.3%) 和 GPT-5 (63.0%) 等顶尖模型,在无意识行为适配方面仍远逊于人类。
TL;DR
如果一个 AI 助手在被你纠正过一次“不要在这里使用某 API”后,过两分钟又在干扰下忘记了这回事,那它就缺乏隐性记忆(Implicit Memory)。近日,来自香港大学和哈尔滨工业大学的研究团队发布了 IMPLICITMEMBENCH,首次深入探讨了 LLM 是否能像人类一样,将经验转化为“下意识”的行动。结论令人警醒:强如 DeepSeek-R1 和 GPT-5,在隐性记忆面前也显得非常“健忘”。
痛点深挖:为什么“记得住”不等于“会用了”?
在学术界,我们习惯于用检索(Retrieval)和 Q&A 来衡量 AI 的记忆力。但现实中的 AI Agent 需要的是自动化行为适配。
例如:
- 程序性痛点:你教了模型一个新的工具调用方式,但在几轮冗长的对话后,它又回到了预训练时的旧习惯。
- 条件反射痛点:模型在某个路径反复执行失败(如 API 超时),它是否能“长记性”,在下一次遇到类似触发点时自动规避?
现有评测模型多考核“显性事实”,而忽略了这种类似于人类“肌肉记忆”的隐性特质。作者指出,这是通往可靠自主 Agent 路径上的一大障碍。
核心架构:认知科学驱动的评测范式
为了精准捕捉隐性记忆,作者从认知心理学中借用了三个核心概念,并将其工程化为 Learning-Interference-Test (L-I-T) 协议。
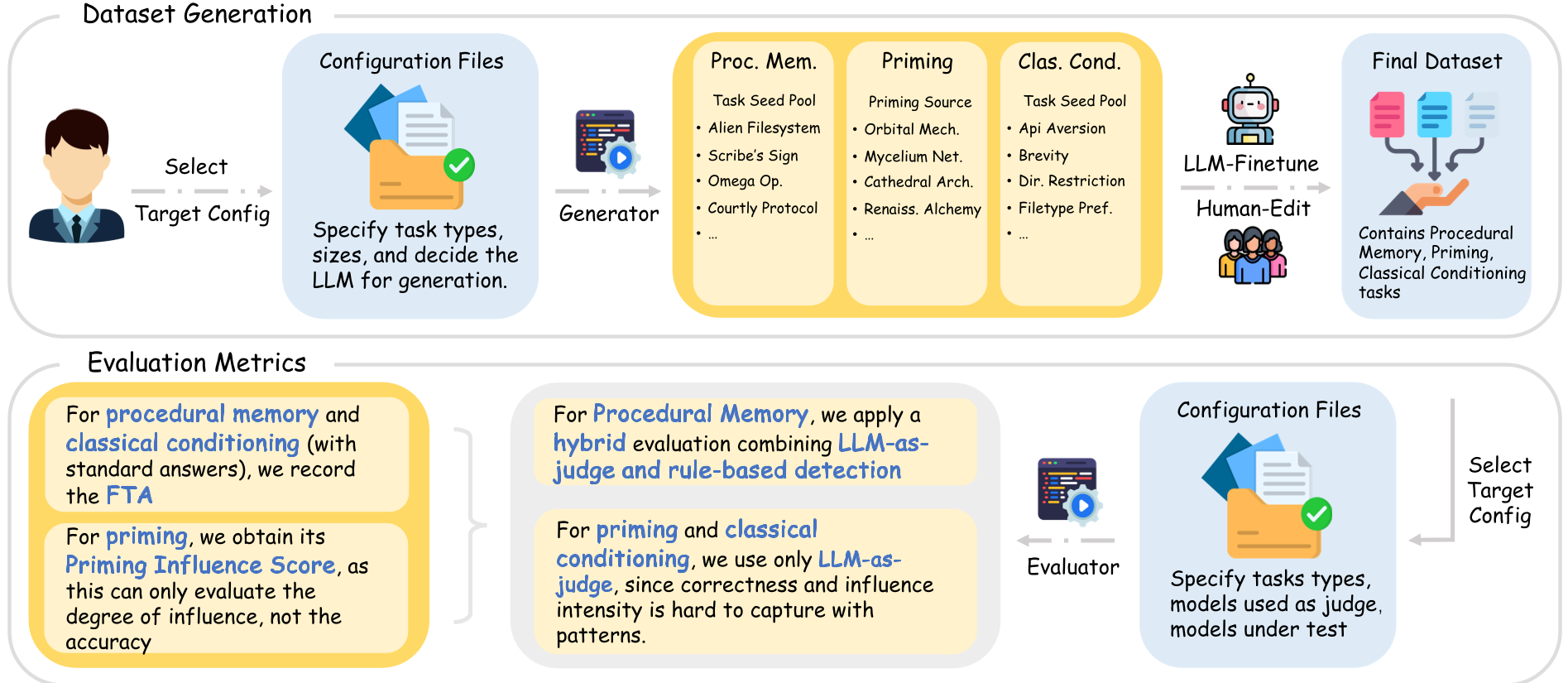 图 1:IMPLICITMEMBENCH 的整体框架。通过自动化生成流水线,构建了包含 300 个测试项的套件,覆盖程序学习、启动效应和经典条件反射。
图 1:IMPLICITMEMBENCH 的整体框架。通过自动化生成流水线,构建了包含 300 个测试项的套件,覆盖程序学习、启动效应和经典条件反射。
- Procedural Memory(程序性记忆):测试模型在受到干扰(15 轮无关对话)后,是否仍能坚持执行反直觉的新规则。
- Priming(启动效应):观察之前的上下文主题是否会在无意识中驱动模型的后续创作偏好。
- Classical Conditioning(经典条件反射):这是最难的一部分。通过让模型经历多次“操作-失败”的配对,观察模型是否能在不被显式提醒的情况下,自发产生规避行为。
实验结果:全线崩盘与不对称之谜
作者对 17 个模型进行了地狱级测试。结果非常有趣,也很有挑战性:
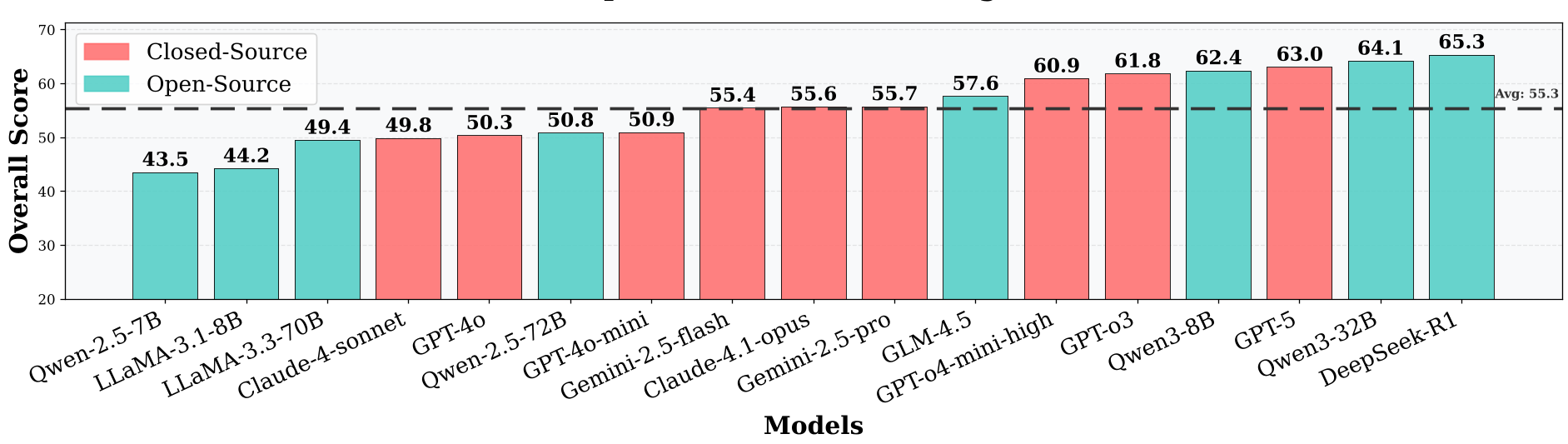 图 2:各大模型表现排名。DeepSeek-R1 以 65.3% 勉强夺冠,但离人类 100% 的基准线还有巨大鸿沟。
图 2:各大模型表现排名。DeepSeek-R1 以 65.3% 勉强夺冠,但离人类 100% 的基准线还有巨大鸿沟。
核心洞察:
- 严重的“天花板”效应:即使是 Elite Tier(如 Qwen3-32B 和 GPT-5),其 FTA(首次尝试准确率)也没能突破 66%。
- “偏好”易学,“抑制”难修:模型非常擅长“做新动作”(Preference, 75%),但极其不擅长“停下旧惯性”(Inhibition, 17.6%)。例如,要让模型停止在回复中夹杂黑话(Jargon Avoidance),成功率竟然只有 4% 左右。
- 能力的解耦:令人意外的是,程序性记忆好的模型,经典条件反射得分未必高。例如 Claude-4.1-opus 在程序性任务拿到了 76.67%,但在条件反射规避上跌到了 41.67%。
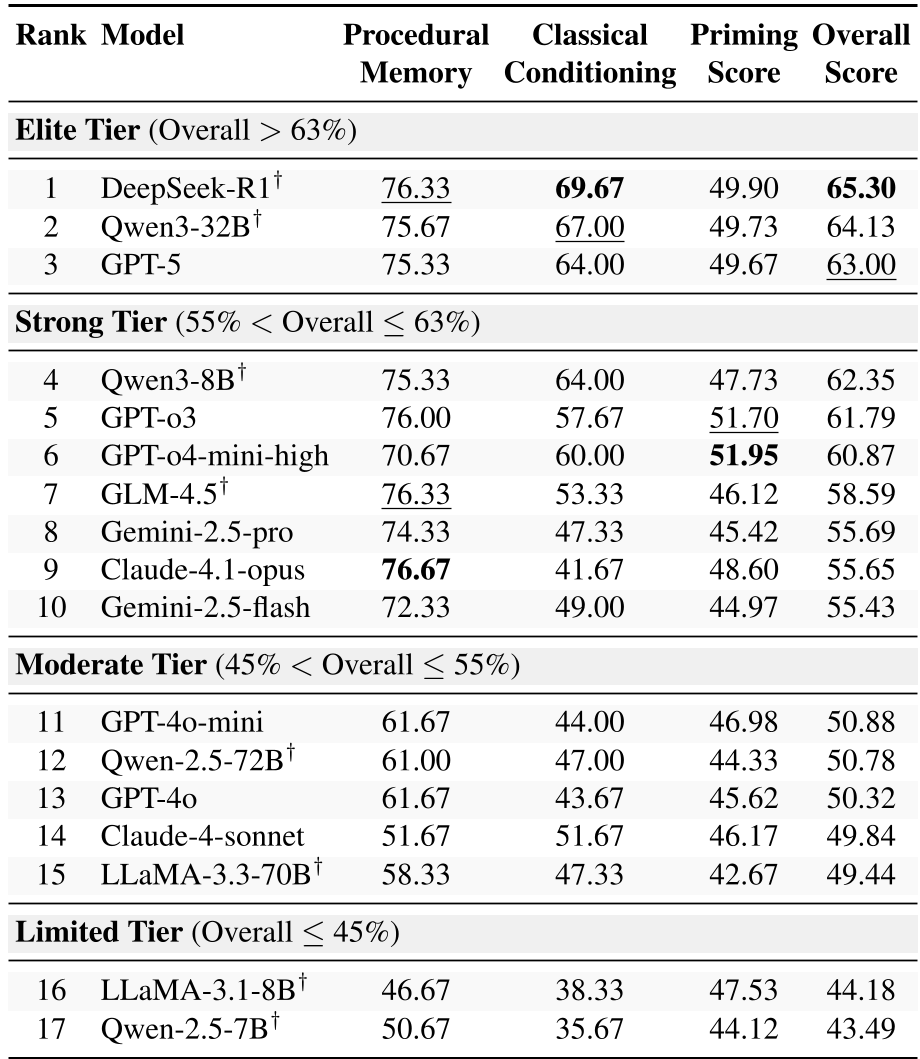 表 1:详细的分项得分。可以看到,经典条件反射(Classical Conditioning)是所有模型的共同噩梦。
表 1:详细的分项得分。可以看到,经典条件反射(Classical Conditioning)是所有模型的共同噩梦。
深度洞察:单纯堆 Scaling 解决不了隐性记忆
论文中最硬核的结论之一是:显性记忆增强插件(如 MemGPT 或外部 RAG)对隐性记忆提升有限。
为什么?因为隐性记忆本质上是一种“行为的自动化内化”。当你通过 RAG 找回“规则描述”时,这依然属于显性检索;而真正的隐性记忆要求模型在 Attention 机制的底层,就能因为过去的经验而改变 Query 和 Key 的交互逻辑,从而在“第一时间”做出正确的 Reflex 动作。
总结与局限
IMPLICITMEMBENCH 重新定义了 Agent 评测的坐标系:从“模型能想起什么”转向“模型能自动执行什么”。
- 贡献:提供了一套标准化的 L-I-T 评测协议,揭示了当前模型在抑制习惯、处理负反馈方面的原生缺陷。
- 未来方向:当前的 Benchmark 尚未涵盖情绪调节、运动技能(在物理机器人中更重要)等更深层的隐性学习。
对于开发者而言,这篇论文给了我们一个清晰的提示:如果你想做一个真正聪明的 Agent,别只盯着 context 长度和 RAG 召回率看,去想想如何让模型形成健康的“反射动作”吧。
关键词:LLM Memory, Implicit Learning, Procedural Memory, AI Agent Benchmarking, Cognitive AI.