本文提出了 Image-to-Image Rectified Flow Reformulation (I2I-RFR),一种将标准图像到图像 (I2I) 回归网络重新表述为连续时间传输模型的插拔式方法。通过将噪声退化的目标图像与输入连接,该方法使传统回归架构能以极少的步数(如 3 步 ODE 求解)实现渐进精细化生成。
TL;DR
在 Image-to-Image (I2I) 领域,长期存在着“回归模型稳健但模糊”与“生成模型细节多但太重”的权衡。来自筑波大学的研究者提出了 I2I-RFR,通过将 Rectified Flow 理论引入传统回归网络,只需简单的通道扩写和 $t$ 加权损失,就能让原有的回归模型(如 U-Net, SwinIR)无缝升级为具备“精细化能力”的生成模型。核心优势在于:推理极快(默认仅需 3 步),不改变核心架构,感知画质大幅提升。
痛点深挖:为什么你的模型输出总是“糊”的?
大多数 I2I 任务(如超分、去模糊)在数学上都是病态问题(Ill-posed)。一个低分辨率或模糊的输入,在理论上可能对应无数个清晰的高分辨率图像。
- 回归陷阱:使用 $\ell_1$ 或 MSE 损失训练的模型为了减小平均误差,通常会预测所有可能解的均值。在数学上,这就是导致图像变“糊”、纹理缺失的根源。
- 生成式负担:GAN 不稳定且难以训练;Diffusion 虽强,但百步以上的推理深度在实时视频或交互式场景中几乎不可用。
核心机制:当回归遇上 Rectified Flow
作者提出了一种巧妙的重构策略,将 I2I 回归视为寻找一个速度场(Velocity Field),将随机噪声变幻为目标图像。
1. 简单的插拔式架构
你不需要改变 SwinIR 或 Restormer 的内部逻辑,只需要将其输入层从 3 通道扩展为 6 通道。输入的不仅是降质图 $x$,还有混合了高斯噪声的目标图 $y_t = (1-t)y + t\epsilon$。
 左侧为常规 $\ell_1$ 回归,右侧为 I2I-RFR 增强后的结果,细节丰富度差异巨大。
左侧为常规 $\ell_1$ 回归,右侧为 I2I-RFR 增强后的结果,细节丰富度差异巨大。
2. 物理直觉:$y$ 预测 vs 速度预测
不同于通用的文本转图像模型(通常预测速度 $v$ 或噪声 $\epsilon$),I2I-RFR 选择直接预测目标图 $y$。
- 直觉解释:在有图像条件(Conditioning x)的情况下,输入本身提供了极强的空间先验。直接预测清晰图像比预测抽象的速度场更符合视觉网络的归纳偏数(Inductive Bias)。
3. Beta 采样策略
为了稳定训练,作者使用了 $t \sim ext{Beta}(2, 1)$ 的采样策略。这比均匀采样更能覆盖高噪声区间,确保模型在推理初期($t \approx 1$)就能精准切入轨迹。
实验战绩:全线任务的感知跃迁
研究人员在超分、去模糊、暗光增强、水下图像处理及视频恢复等 5 大任务上验证了 I2I-RFR 的普适性。
- 超分 (SR):SwinIR 结合 I2I-RFR 后,在四个标准测例上 LPIPS 指标(感知损失)均大幅下降,画质更接近真值(Ground Truth)。
- 去模糊:在 RealBlur-J 数据集上,Restormer 结合该方法后感知质量显著优于原始基线。
- 暗光去模糊:对于极具挑战的暗光+模糊场景,LEDNet 通过 I2I-RFR 获得了 1.38dB 的 PSNR 增益,且 LPIPS 降低了约 13%。
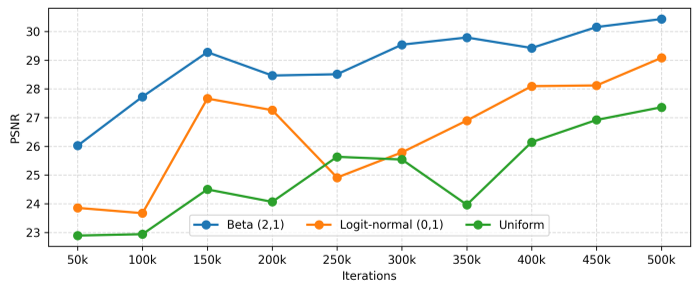 Beta 采样(橙线)在训练稳定性和 PSNR 表现上明显优于 Logit-normal 和均匀采样。
Beta 采样(橙线)在训练稳定性和 PSNR 表现上明显优于 Logit-normal 和均匀采样。
深度洞察:为什么 3 步就够了?
这是 I2I-RFR 最具吸引力的一点。在生成模型动辄几十步推理时,该方法在 $N=3$ 时就达到了性能饱和。
- 核心原因:输入图像 $x$ 提供了强大的“锚点”。噪声状态 $y_t$ 在这里更像是一个精细化变量(Refinement variable),而非纯粹的生成起点。前几次迭代已经完成了主要的图像重建,后续步骤仅用于微调纹理细节。
深度分析与结论
I2I-RFR 的真正价值在于:它为存量的、已经经过大量工程优化的任务专用模型(Backbones)提供了一条通往生成式效果的“近路”。
局限性 (Limitations)
- PSNR-Perception 权衡:在某些模型中,感知质量的提升伴随着 PSNR 的微降(这是生成式模型的共性)。
- 输入依赖:对于完全没有空间对应关系的跨域任务,其有效性可能打折扣。
总结 (Takeaway)
如果你正在优化一个图像恢复流水线,并苦恼于模糊的细节,I2I-RFR 提供了一个低成本、高收益的方案:改个通道,换个 Loss,加两步循环,就能让模型从稳健回归跨入高感知生成的门槛。