InCoder-32B is a 32-billion parameter code foundation model specifically engineered for industrial scenarios, including chip design (Verilog), GPU kernel optimization (CUDA/Triton), embedded systems, and 3D modeling. It achieves state-of-the-art results on industrial benchmarks, such as ranking first among open-source models in RealBench and KernelBench, while maintaining competitive performance on general coding tasks.
TL;DR
The era of "Generalist" code models is meeting its match in the industrial sector. InCoder-32B is the first large-scale foundation model (32B parameters) purpose-built to bridge the gap between GitHub-style software engineering and hardcore industrial programming—spanning Verilog (RTL), CUDA/Triton kernels, Embedded C, and CAD modeling. By integrating real-world compilers and simulators into the training loop, it achieves performance that often surpasses proprietary models like Claude 3.5 Sonnet in specialized domains.
The "Off-the-Shelf" Failure: Why General LLMs Struggle with Industrial Code
Most LLMs are "Web-native." They understand Python web frameworks and React components because the internet is saturated with them. However, industrial tasks like chip design or GPU kernel tuning occupy a negligible fraction of open-source tokens.
The authors identify a critical "OOD" (Out-of-Distribution) problem:
- Hardware Semantics: In Verilog, code represents physical gates and wires, not sequential instructions.
- Strict Constraints: A GPU kernel that is "mostly correct" but violates a hardware memory limit is a 0% success; there is no middle ground.
- Verification Rigor: Industrial code requires simulation (e.g., Icarus Verilog, Renode) to prove correctness.
Methodology: High-Fidelity Training via "Code-Flow"
InCoder-32B doesn't just read code; it "experiences" the toolchain through a three-stage pipeline.
1. Pre-training with Industrial Recall
Instead of a simple crawl, the authors used a three-step recall strategy (Rule-based -> FastText -> Semantic Encoder) to find rare industrial code hidden in general repositories, supplemented by OCR-extracted technical manuals.
2. Mid-training: Context & Reasoning
The model's context was expanded from 8K to 128K tokens. This isn't just about "seeing more tokens"; it's about handling long-context debugging sessions where a model must look at a 50-file RTL project to find a single timing violation. They used Agent Trajectories (Thought-Action-Observation) to teach the model how to fix bugs based on simulator output.
3. Post-training: Execution-Grounded Verification
This is the "Secret Sauce." The authors reconstructed four classes of industrial environments:
- Chip Design: Icarus Verilog and Yosys.
- GPU: NVIDIA A100 nodes for real-time benchmarking.
- Embedded: Renode simulator for ARM Cortex-M4.
- 3D: OpenCascade/CadQuery kernels.
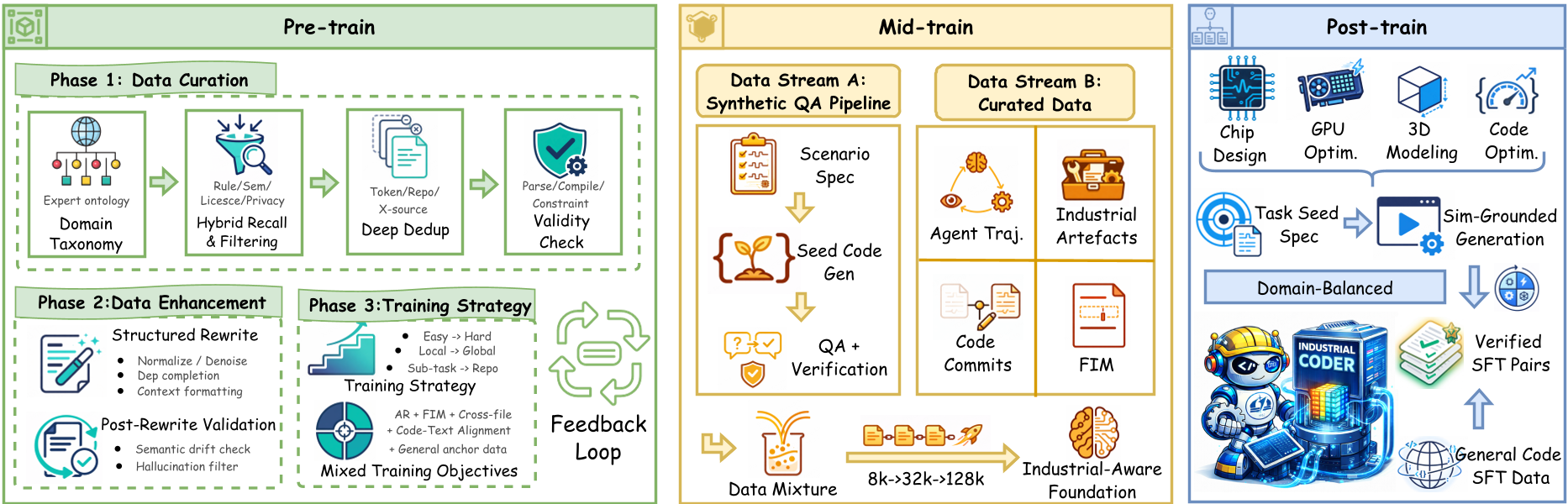 Figure: The three-stage pipeline emphasizing simulation-grounded SFT data.
Figure: The three-stage pipeline emphasizing simulation-grounded SFT data.
Experimental Showdown: Outperforming the Giants
The results prove that Domain Depth > Parameter Breadth.
| Benchmark | InCoder-32B (32B) | DeepSeek-V3.2 (671B) | Claude-Sonnet-4.6 | | :--- | :---: | :---: | :---: | | RealBench (Module Func@1) | 62.7 | 17.2 | 33.5 | | KernelBench (L1) | 22.2 | 3.0 | 11.1 | | CAD-Coder (IoU) | 53.5 | 4.6 | 32.4 |
As shown in the table above, InCoder-32B dominates in RealBench (Chip design) and KernelBench (GPU operators). In CAD-Coder, its IoU (Intersection over Union) score of 53.5 towers over DeepSeek's 4.6, highlighting back-and-forth reasoning about 3D geometry conventions that general models completely miss.
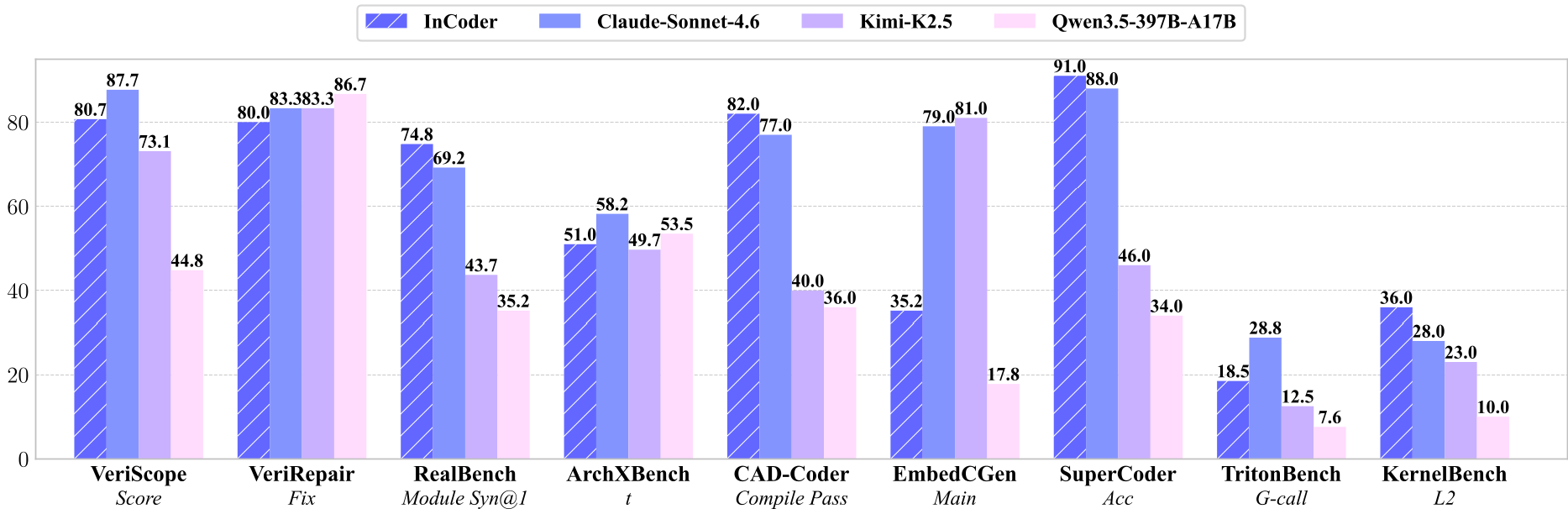 Figure: Performance of InCoder-32B showing a significant lead in domain-specific tasks.
Figure: Performance of InCoder-32B showing a significant lead in domain-specific tasks.
Error Analysis: The Long Road to "Silicon-Ready"
Even with these gains, the authors are objective about the limitations. A manual inspection of 1,882 failures revealed:
- Syntax errors (Verilog): Still account for 71% of RealBench failures (e.g., bit-width mismatches).
- Numerical interpretation: In 3D modeling (CAD-Coder), 93% of failures were "geometric glitches," often misinterpreting rotation axes.
- Optimization Gaps: In SuperCoder, many failures were "lazy," where the model simply copied the input without attempting difficult assembly-level optimizations.
Conclusion & Engineering Takeaway
InCoder-32B proves that the next frontier of AI is Verticalization. For engineers in EDA, HPC, and Embedded systems, this model provides a localized, open-source foundation that understands the "physics" of their specific domain. The shift from SFT based on "what looks right" to SFT based on "what compiles and runs" is the new gold standard for industrial AI.
局限性 (Limitations)
- API Fragility: The model still suffers from hallucinated industrial APIs (HAL/CMSIS) in about 47% of embedded failures.
- Complex Logic: In VeriRepair, nearly 80% of failures were due to code that compiled but failed logical test cases, showing that deep semantic reasoning in state machines remains a challenge.
未来展望 (Future Work)
We expect future iterations to integrate Reinforcement Learning with Verifiable Rewards (similar to the DeepSeek-R1 approach) specifically for timing closure and power optimization in chip design.