本文提出了 In-Place Test-Time Training (In-Place TTT) 框架,通过将 LLM 中现有的 MLP 层转化为动态更新的“快速权重”(Fast Weights),使模型在推理过程中能即时学习长文本信息。该方法在 4B 参数模型上实现了 128k 上下文的性能突破,并显著优于之前的 TTT 方法。
TL;DR
传统的 LLM 是“先训练再部署”的静态模型,而 In-Place TTT (In-Place Test-Time Training) 提出了一种新范式:将 MLP 层视为动态的“大脑”,在推理过程中根据输入流实时更新权重。该方法无需从头训练,能够作为“插件”直接增强 Qwen、Llama 等现有模型,使其在处理 128k 甚至更长的上下文时表现出更强的推理与记忆能力。
背景定位:从静态部署到动态自适应
目前的 LLM 面对超长文本主要依赖两种手段:增加 Context Window(计算开销大)或检索增强(RAG,存在检索丢失)。Test-Time Training (TTT) 提供了第三种路径:让模型在看文档的过程中,通过自监督学习把信息“写”进参数里。
然而,之前的 TTT 方法(如 TTT-Linear)需要特殊的线性层,导致无法直接用于现成的 Llama 模型。In-Place TTT 的本质提升在于:它把 TTT 从一种“新架构”变成了“新算法”,直接在现有的 MLP 上动刀。
痛点深挖:为什么之前的 TTT 走不通?
- 架构不兼容:你想用 TTT?对不起,请从零开始训练一个包含 TTT 层的模型,成本极高。
- 效率极低:逐 token 的权重更新在 GPU 上跑得比蜗牛还慢。
- 目标错位:以前的 TTT 只是在做“重构”(记住所看的内容),这和 LLM 的核心目标“预测下一个词”(NTP)是不一致的。
核心机制:In-Place 架构与 NTP 对齐目标
1. 既然有 MLP,何必造新轮子?
作者发现,Transformer 中的 MLP 分支本质上就是一个 Key-Value 存储器。In-Place TTT 选择保留 MLP 的前两层作为静态知识库,而将最后一层投影矩阵 设为快速权重(Fast Weights)。在推理时,模型会根据当前的输入块动态调整 。
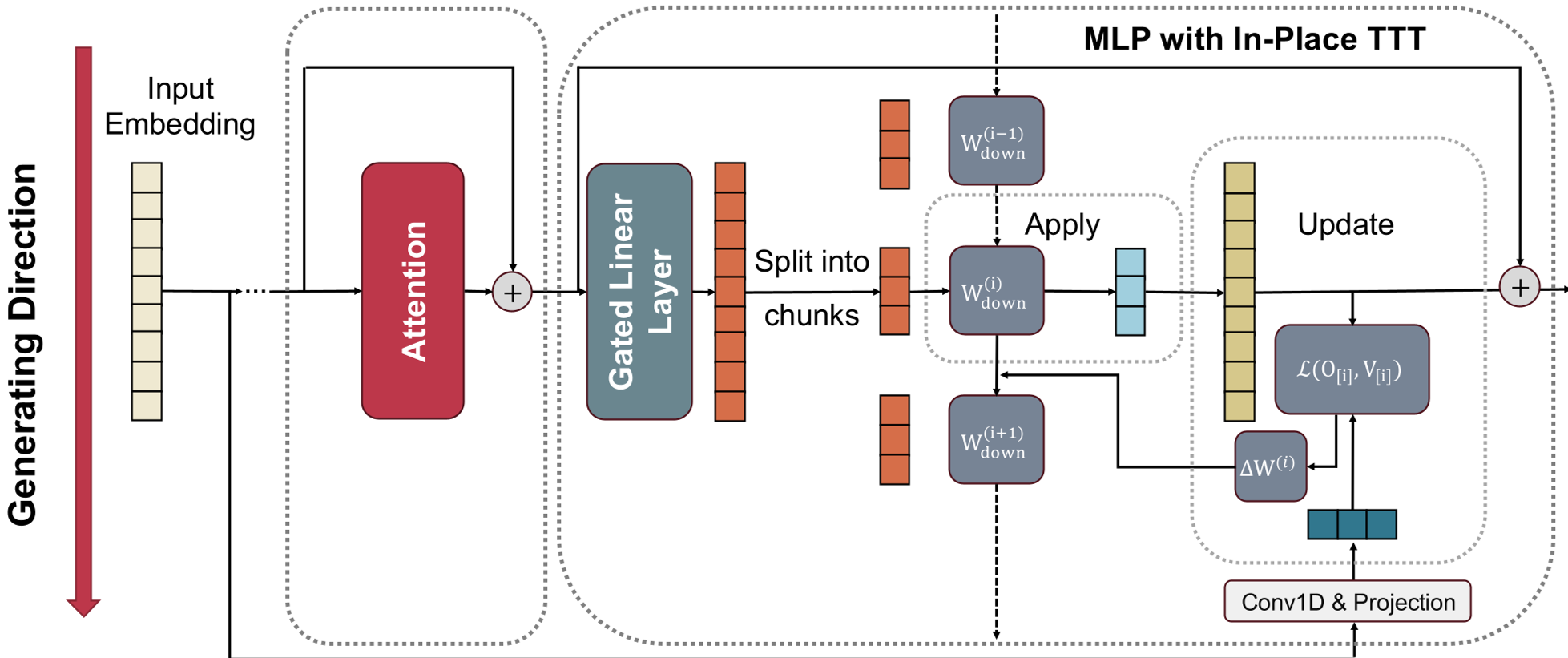 图 1:In-Place TTT 总体框架。模型在处理 input chunk 时,先应用当前权重,再利用 NTP 目标更新权重,形成闭环。
图 1:In-Place TTT 总体框架。模型在处理 input chunk 时,先应用当前权重,再利用 NTP 目标更新权重,形成闭环。
2. 只有“预测未来”才能学得更好
这是本文最具学术深度的地方。作者通过数学证明(Theorem 1)指出:如果 TTT 的目标只是重构当前词(Reconstruction),它对预测下文几乎没有 logit 增益。 相反,In-Place TTT 引入了 LM-Aligned Objective:
- 使用 1D 卷积提取未来 token 的信息作为学习目标。
- 理论证明这种目标能显着提升正确 token 的 logit,并在推理时实现类人的“联想记忆”。
3. Chunk-wise 更新:速度不妥协
为了适配现代 GPU,作者抛弃了逐词更新,改用 Chunk-wise(块状更新)。通过关联律(Associative Property),这一过程可以用 平行扫描(Parallel Scan) 算法加速,支持 Context Parallelism (CP),在大规模集群上也能飞速运行。
实验战绩:老模型焕发第二春
实验在 Qwen3 和 Llama 3.1 上展开。通过极小代价的“持续训练”(Continual Training),4B 模型的长文本处理能力甚至超过了一些 14B 的基线。
- 长文本极限测试 (RULER):在 128k 长度下,In-Place TTT 让模型性能从原有的崩溃边缘拉回到了 77.0 分的高位。
- 外推能力:虽然只在 128k 上训练,但在 256k 的超长测试中,性能依然稳健,证明了 Fast Weights 确实起到了动态缓存的作用。
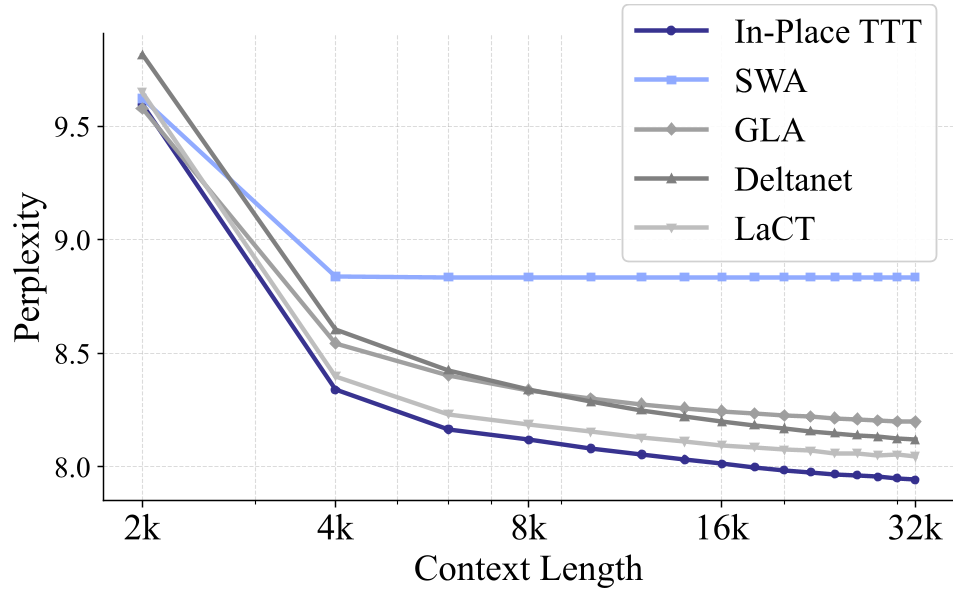 图 2:在 500M 和 1.5B 尺度下,In-Place TTT 的困惑度(PPL)随长度增加持续下降,显著优于 SWA 和 LaCT。
图 2:在 500M 和 1.5B 尺度下,In-Place TTT 的困惑度(PPL)随长度增加持续下降,显著优于 SWA 和 LaCT。
深度洞察:消融实验揭秘
作者通过消融实验展示了两个核心发现:
- 状态空间(State Size)很重要:启用的 TTT 层数越多(即动态参数越多),性能越强。
- 卷积与投影缺一不可:公式中的 Conv1D 负责捕捉长程信息,而 Projection 矩阵负责短程对齐。
局限性与展望
尽管表现强劲,但 In-Place TTT 目前仍存在一定的计算开销(尽管被并行化摊薄)。未来,如何让这种“边读边学”的过程更加稀疏化(Sparse),或者将其与状态空间模型(SSM)深度结合,将是一个非常有趣的课题。
总结:In-Place TTT 证明了 LLM 不需要死记硬背长文本,通过动态调整其 MLP 的“突触强度”,模型完全可以具备人类般的瞬时记忆。