本文提出了一个基于自回归扩散模型 (Autoregressive Diffusion) 的生成框架,用于在任意长度的视频中合成无限时界的原始人类注视轨迹 (Infinite-horizon Gaze)。该方法通过显著性感知潜空间 (Saliency-aware Latent Space) 进行调节,在长程时空准确性和轨迹真实感上达到了 SOTA 水平。
TL;DR
本文提出了一种能够为任意长度视频生成连续、真实注视轨迹(Raw Gaze Trajectories)的生成式框架。通过结合自回归(Autoregressive)机制与扩散模型(Diffusion Models),并辅以**显著性感知(Saliency-aware)**的潜空间压缩技术,该模型突破了现有方法在时间长度(仅3-5s)和动态精细度上的瓶颈。
背景定位:这是首个专注于长序列、高频视频注视数据生成的模型,属于“生成式行为建模”与“世界模型 (World Models)”的交叉前沿工作。
痛点深挖:为何长视频注视预测这么难?
- 数据抽象过度:传统 Saliency Map 只有空间分布,Scanpath 只有离散落点。它们都无法描述人类在看视频时特有的平滑追踪 (Smooth Pursuit) 和高频抖动。
- 时界受限:现有模型多为“快照”式预测。一旦视频超过几秒,由于缺乏历史状态维护,生成的轨迹会迅速发生漂移或产生不自然的跳变。
- 计算冗余:视频的 RGB 信息量巨大。直接将全量视频帧喂给扩散模型会导致推理速度极慢,且难以提取出对“注视行为”真正有用的特征。
核心方法:自回归扩散与显著性引导
作者认为,人类的目光移动不仅受当前画面的视觉冲击(底向上)驱动,也受到历史观察逻辑(顶向下)的约束。
1. 架构构建
模型采用了基于 U-Net 的 1D 卷积扩散骨架。为了处理无限长的视频,作者引入了注视缓存 (Gaze Cache) 机制:
- 训练阶段:随机选取 个真实坐标作为前缀,预测后续序列,仅对预测段计算 Loss。
- 推理阶段:采用滑动窗口,将上一步生成的 个坐标作为 Condition,循环往复实现“无限”生成。
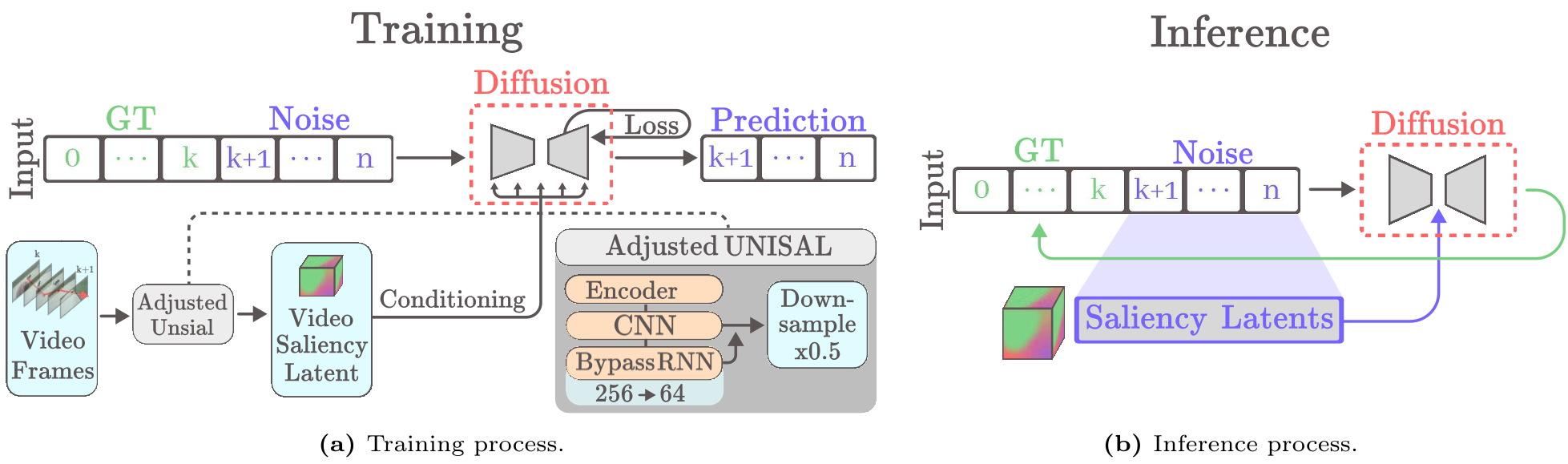 图 1:模型总体架构。注意中间的 Saliency Encoder 负责将视频压缩为高效的潜在表征。
图 1:模型总体架构。注意中间的 Saliency Encoder 负责将视频压缩为高效的潜在表征。
2. 显著性感知潜空间 (Saliency-aware Latent)
这是本文的 Insight 所在:与其让模型从原始像素中学习“哪里吸引人”,不如直接利用成熟的显著性模型(如 UNISAL)作为先验。作者设计了一个带有瓶颈层(Bottleneck)的编码器,将 RNN 通道从 256 压缩至 64,并进行空间池化。实验证明,这种显著性特征比通用的视觉特征(如 MAGVIT2 token)更易于模型收敛。
实验与结果:全方位的领先
研究团队在 DIEM 和 DHF1K 两个大型视频数据集上进行了验证。
- 定量分析:在反映时空对齐准确性的 DTW (Dynamic Time Warping) 指标上,本方法大幅领先于 DiffEye 和 GazeFormer(如表 1 所示)。
- 定性可视化:从生成的轨迹图可以看出,本方法的路径(彩色线)与人类真实路径(黑线)高度重合,且轨迹平滑,没有基线方法中常见的“瞬移”现象。
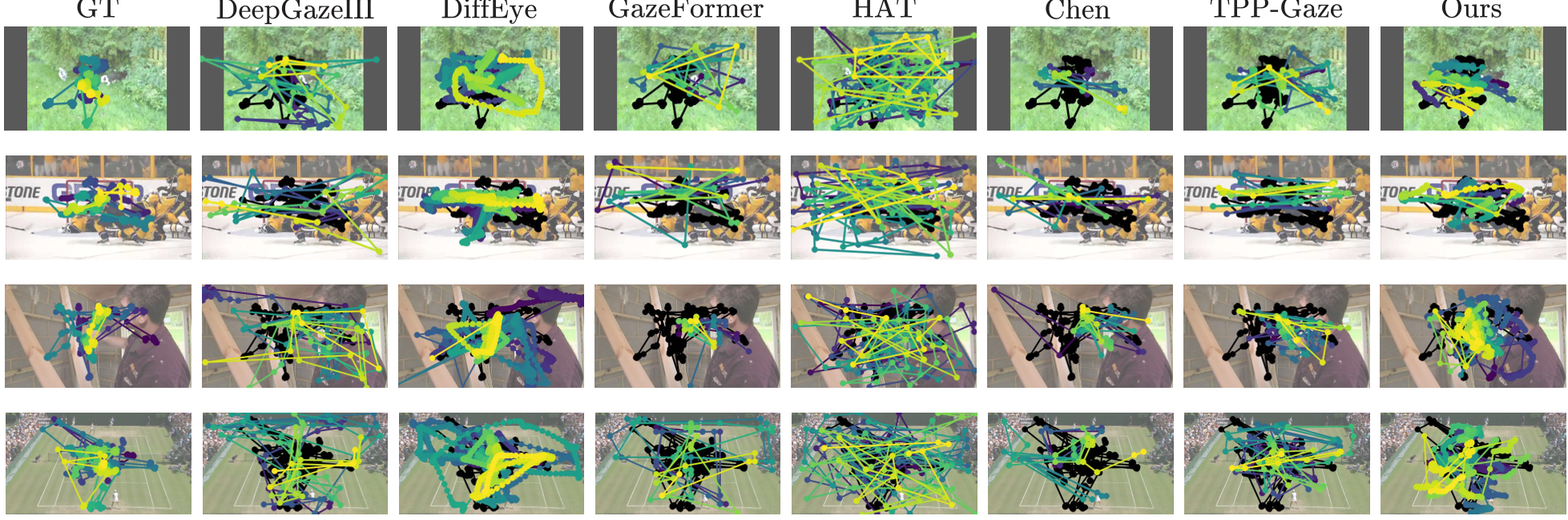 图 2:轨迹可视化对比。可以看出本方法生成的路径在时空分布上与 Ground Truth 极度接近。
图 2:轨迹可视化对比。可以看出本方法生成的路径在时空分布上与 Ground Truth 极度接近。
深度洞察:迈向行为辅助的世界模型
本项研究最令人兴奋的启示在于:注视数据是人类与物理世界交互的最直接“信号”。
以往的世界模型(如 Sora)侧重于像素生成的物理真实性,但缺乏对“人类如何观察这个世界”的理解。本文的工作填补了这一空白。通过模拟人类的注意分配,未来的 AI 智能体可以更好地预测人类的意图,或在 VR/AR 领域实现更自然的注视点渲染(Foveated Rendering)。
局限性与挑战
- 长程语义依赖:目前的自回归仍基于固定窗口,对于跨越数十秒的复杂语义记忆(例如:寻找视频开头出现过的一个特定角色)仍有提升空间。
- 头部运动耦合:目前的实验主要针对桌面观看场景。在真实的 3D 环境中,眼球运动与头部转动是耦合的,这将是未来的重要研究方向。
总结
Infinite Gaze Generation 成功证明了自回归扩散模型是处理复杂、长程人类行为序列的有力工具。它不仅在技术指标上刷新了 SOTA,更在方法论上为“行为感知型 AI”提供了新的思路。