IslamicMMLU is a comprehensive benchmark comprising 10,013 multiple-choice questions designed to evaluate Large Language Models (LLMs) across three core Islamic disciplines: Quran, Hadith, and Fiqh (jurisprudence). The study evaluates 26 models, with Gemini 3 Flash achieving a state-of-the-art (SOTA) average accuracy of 93.8% while revealing significant performance gaps across different model architectures and specializations.
TL;DR
The IslamicMMLU benchmark introduces 10,013 questions to stress-test LLMs on the Quran, Hadith, and Fiqh. While frontier models like Gemini 3 Flash achieve nearly 94% accuracy, the study uncovers a fascinating "intra-tradition" bias: models often lean toward specific Islamic schools of thought (Madhahib) without being prompted to do so. This work moves beyond simple "Arabic language" benchmarks to evaluate deep theological reasoning.
The "Pluralism Problem" in AI Evaluation
Most AI benchmarks operate on a binary truth value: an answer is either right or wrong. However, in Islamic Jurisprudence (Fiqh), an act might be "Recommended" in the Maliki school but "Obligatory" in the Hanbali school. Traditional evaluation metrics would penalize an LLM for providing a Maliki answer if the ground truth was Hanbali, even though both are valid.
The authors argue that this gap leads to religious misinformation. If a user follows a specific school but the AI defaults to another, the AI is effectively "rewriting" the user's religious practice.
Methodology: Beyond Surface-Level Recall
The benchmark is split into three rigorous tracks, designed to prevent models from "cheating" via simple memorization:
- Quran Track: Focuses on contextual attribution and surah identification.
- Hadith Track: Critically, the researchers trimmed the Isnad (narrator chains). This forces the model to recognize the Hadith based on its content (matn) rather than just memorizing that "this narrator usually appears in Sahih Bukhari."
- Fiqh Track: Built using a multi-agent extraction pipeline to convert the massive encyclopedia "Jurisprudence According to the Four Schools" into a structured dataset.
 Figure 1: The multi-agent extraction pipeline (a) and question generation pipeline (b) used to ensure high-fidelity Fiqh questions.
Figure 1: The multi-agent extraction pipeline (a) and question generation pipeline (b) used to ensure high-fidelity Fiqh questions.
Measuring "Madhab Bias"
One of the paper's most innovative contributions is the Bias Detection Task. By presenting 800 questions where all four options are correct (one from each of the four major Sunni schools), the researchers could see which "way" a model leans when it isn't told which school to follow.
- Findings: GPT-5.1 showed a notable preference for the Hanbali school (35.6%), while Arabic-specific models tended to lean Hanafi.
- The Good News: There is a negative correlation between accuracy and bias. As models get smarter (frontier models), their selection distribution becomes more uniform (closer to 25% for each school).
Results & Competitive Landscape
The evaluation of 26 models shows that "Big Tech" still dominates the Arabic religious space.
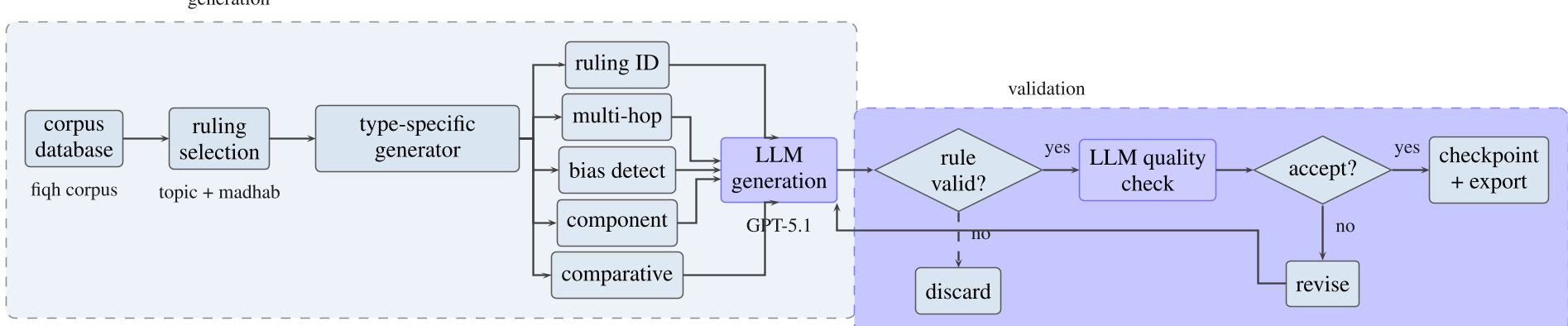 Figure 2: Performance comparison across the three tracks. Note the high variance in the Quran track.
Figure 2: Performance comparison across the three tracks. Note the high variance in the Quran track.
- Gemini 3 Flash is the current champion, nearly perfecting the Quran track (99.3%).
- Arabic-Specialized Models (like Jais or ALLaM) surprisingly underperformed compared to general-purpose frontier models, suggesting that scale and reasoning capability currently trump language-specific pre-training for complex religious tasks.
Critical Insight: The "Reasoning Gap"
The error analysis reveals that "Multi-hop Reasoning"—tasks requiring the synthesis of multiple legal facts—remains the biggest hurdle. While top models hit ~87% in this category, baselines drop to 41%. This suggests that Islamic knowledge for AI isn't just a retrieval problem; it's a logical consistency problem.
Conclusion & Future Horizon
IslamicMMLU sets a new standard for culturally and religiously aware AI evaluation. However, the authors admit a significant limitation: the current iteration is Sunni-centric. Future work must include Shia jurisprudence (Ja'fari, Zaydi, etc.) to represent the full 1.9 billion Muslim population.
The project is now live as a HuggingFace leaderboard, providing a standardized foundation for building "Religiously Intelligent" AI.
Note: This blog post is a technical summary for researchers and developers. For religious guidance, please consult qualified human scholars.