This paper investigates the brittleness of LLM-based generative optimization in iterative learning loops across diverse tasks like ML pipelines, Atari games, and prompt engineering. The authors identify three "hidden" design choices—starting artifacts, credit horizon, and experience batching—that fundamentally determine optimization success, ultimately providing a systematic framework for building more robust self-improving agents.
TL;DR
Building an agent that "learns from its mistakes" sounds simple, yet only 9% of agentic systems actually use automated optimization. This paper reveals that the failure isn't due to bad models, but poor Learning Loop design. By analyzing Starting Artifacts, Credit Horizons, and Experience Batching, the authors demonstrate that how you frame the problem to the LLM-optimizer is more important than the optimizer itself.
Background: The Gap Between Research and Production
We are entering an era of "Self-Improving Software." Whether it's DSPy for prompts or TextGrad for code, the goal is to let an LLM look at a failure, reflect, and fix the system. However, in production, these loops often break. The authors argue that engineers are making "hidden" choices—like how much code to let the LLM see or how many errors to batch together—without realizing these choices are the "hyperparameters" of generative optimization.
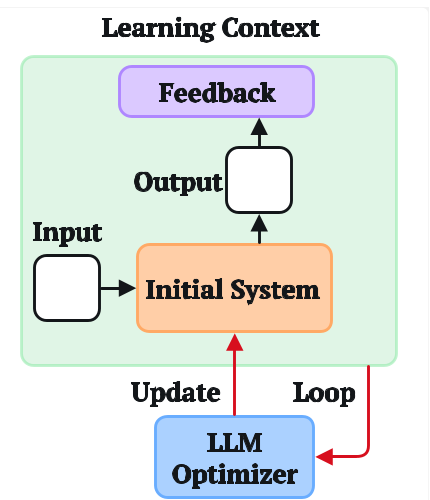
The Anatomy of a Learning Loop
The paper formalizes the optimization process into three critical dimensions:
- Starting Artifacts (Initialization): Is it better to give the LLM a single monolithic function to edit, or a modular pipeline?
- Credit Horizon (Temporal Credit Assignment): In multi-step tasks (like games), should the LLM optimize based on every single action (short horizon) or the final score (long horizon)?
- Experience Batching (Generalization): How many "trial and error" examples should be crammed into a single prompt for the optimizer?
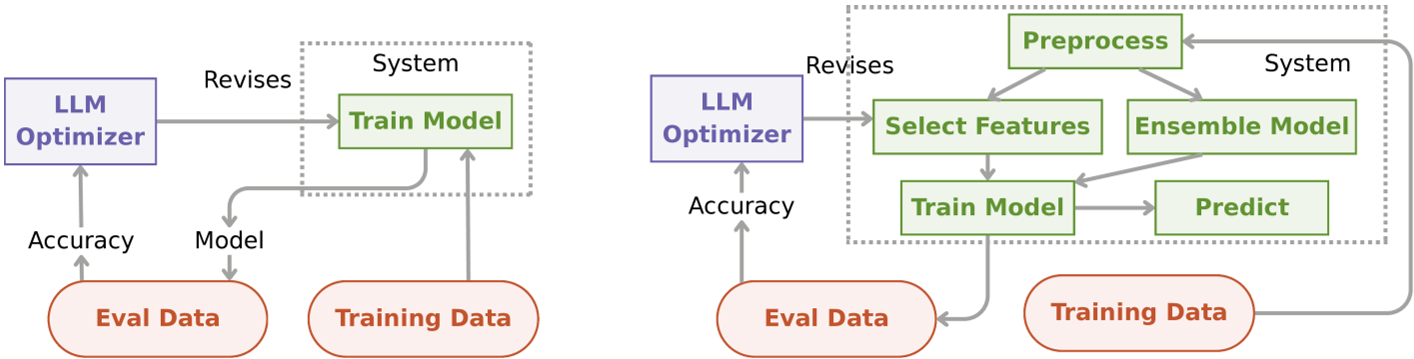
Case Study 1: The Initialization Trap (MLAgentBench)
In a task to build a machine learning pipeline, the authors compared a One-Function approach vs. a Modular Many-Function approach.
- The Surprising Result: On the Spaceship Titanic dataset, modularity helped (ranking in the 86th percentile of human Kagglers). But on the Housing Price dataset, the order flipped—the monolithic function was superior.
- Insight: How you decompose a task provides an "Inductive Bias." Just like neural net weights, the "Starting Artifact" determines which solutions the LLM can reach or imagine.
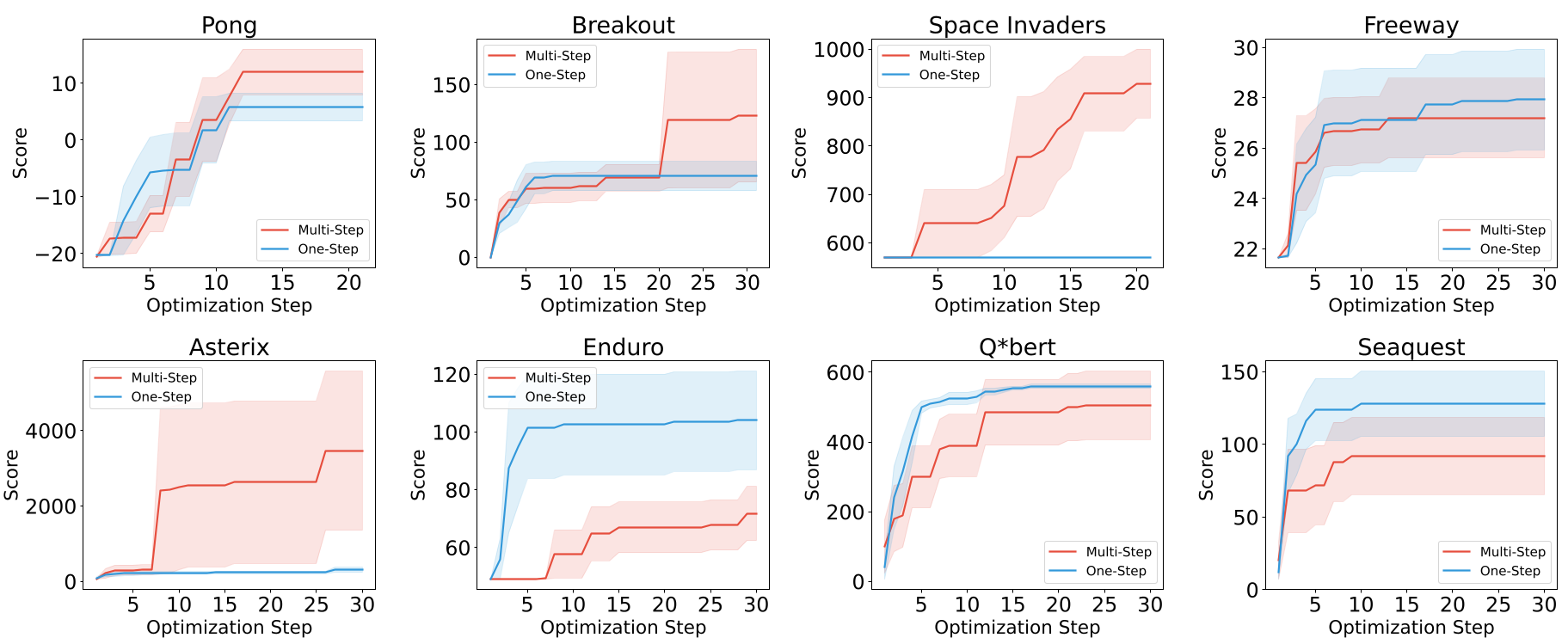
Case Study 2: Finding the Horizon (Atari Games)
In Atari, the system must write Python code to play the game based on object coordinates.
- One-Step Horizon: Update the code after every single frame.
- Multi-Step Horizon: Accumulate hundreds of frames before asking for a revision.
The results showed a 50/50 split across 8 games. For strategic games like Space Invaders, longer horizons were necessary to "see" the consequence of a move. For games like Freeway, immediate feedback was more efficient.
Key Takeaway: Generative optimization can achieve human-level scores with 1/30th the wall-clock time of Deep RL (PPO/DQN), but only if the engineer correctly aligns the credit horizon with the task's causal structure.
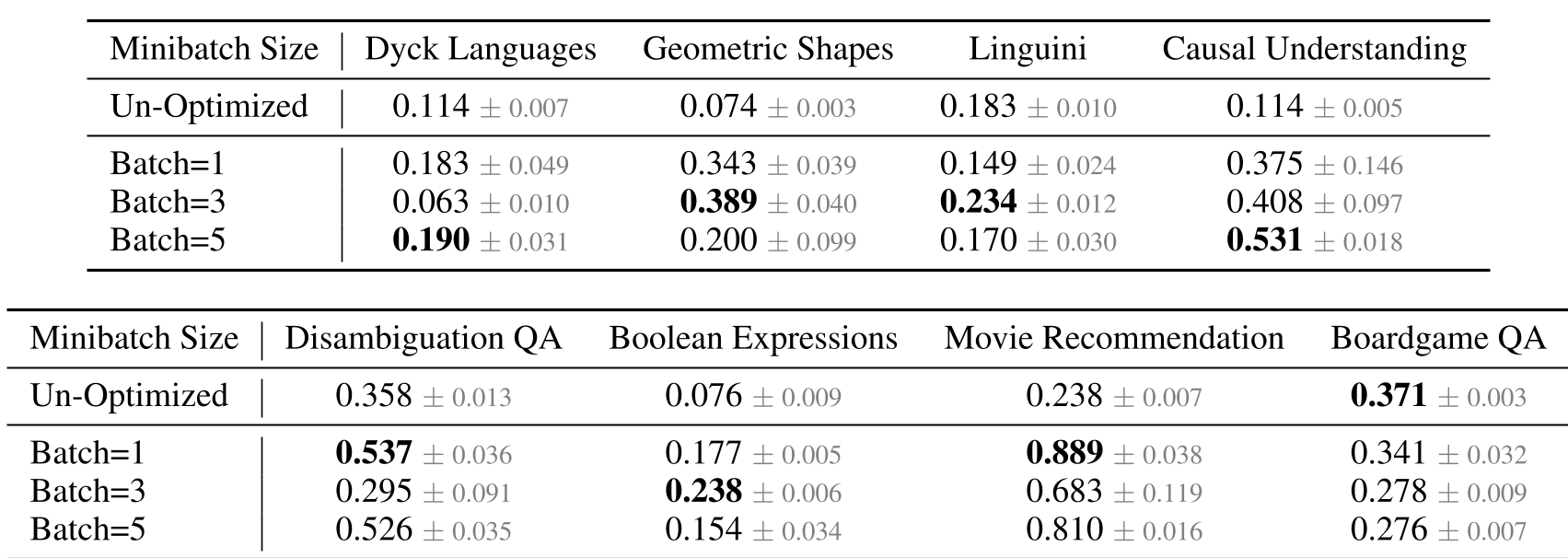
Case Study 3: The Myth of Larger Batches (BigBench Extra Hard)
In prompt optimization, we often assume more data is better. However, the authors found that Batch Size 5 was often worse than Batch Size 1.
- Meta-Overfitting: If the batch is too small, the LLM overfits to one error.
- Cognitive Overload: If the batch is too large, the LLM fails to "reason globally" over conflicting feedback from different examples.
Critical Insight: Meta-Overfitting
One of the most profound observations in the paper is Meta-Overfitting. Even without numerical gradient descent, the LLM optimizer "fits" its code revisions to the validation feedback so aggressively that performance on hidden test sets begins to drop after a few iterations. This proves that LLM-based optimization follows the same fundamental laws of learning as traditional ML.
Conclusion: Toward a "Standard Model" of Agents
The authors conclude that generative optimization currently lacks a "universal default" (like the Adam optimizer or Transformer architecture). To move from 9% to 90% adoption in production, the community must focus on:
- Robust Defaults: Finding initializations that are broadly optimizable.
- Automated Setting: Systems that can dynamically adjust their own batch size and credit horizon.
Final Takeaway: Don't just blame the LLM for failing to improve; look at the architecture of your learning loop.