[CVPR 2026] Know3D: Turning Stochastic 3D Hallucination into Controllable Knowledge Reasoning
Know3D is a novel framework for single-view 3D generation that integrates Multimodal Large Language Models (MLLMs) to achieve language-controllable synthesis of unseen regions. By using a VLM-diffusion model as an intermediate "semantic brain," it ensures that the traditionally stochastic back-view hallucination is both semantically consistent and geometrically plausible, achieving SOTA performance on HY3D-Bench.
TL;DR
Know3D addresses the "black box" of back-view 3D generation. By leveraging Vision-Language Models (VLMs) as a semantic bridge, it allows users to control what the invisible side of a 3D object looks like using natural language. It moves beyond simple visual priors by injecting high-level "knowledge" into the 3D synthesis process.
Problem: The "Stochastic" Back-View
Generating a 3D model from a single photo is like guessing the ending of a book from the first chapter. While current models like TRELLIS and Hunyuan3D are good at guessing, their hallucinations are uncontrollable. If you have a photo of a chair, the model might give it four legs, a pedestal, or weird artifacts on the back—and you have no way to tell it otherwise. This happens because 3D datasets are tiny compared to the internet-scale 2D data that VLMs are trained on.
Methodology: The VLM-Diffusion Bridge
The central insight of Know3D is that we don't need more 3D data; we need to "borrow" the world knowledge lived inside VLMs.
1. Semantic-Aware Front-Back Generation
The authors fine-tuned Qwen-Image-Edit to understand "back-view" logic. Given a front image and a prompt (e.g., "a hollow backrest"), the VLM-diffusion model generates the conceptual back view.
2. Knowledge Injection via MMDiT Hidden States
Instead of just feeding the generated image into a 3D model, Know3D does something smarter. It extracts hidden states (HDiT) from the intermediate layers of the Diffusion Transformer. The authors found that these hidden states contain a perfect mix of spatial structure and semantic meaning, far superior to raw VAE latents or DINO features.
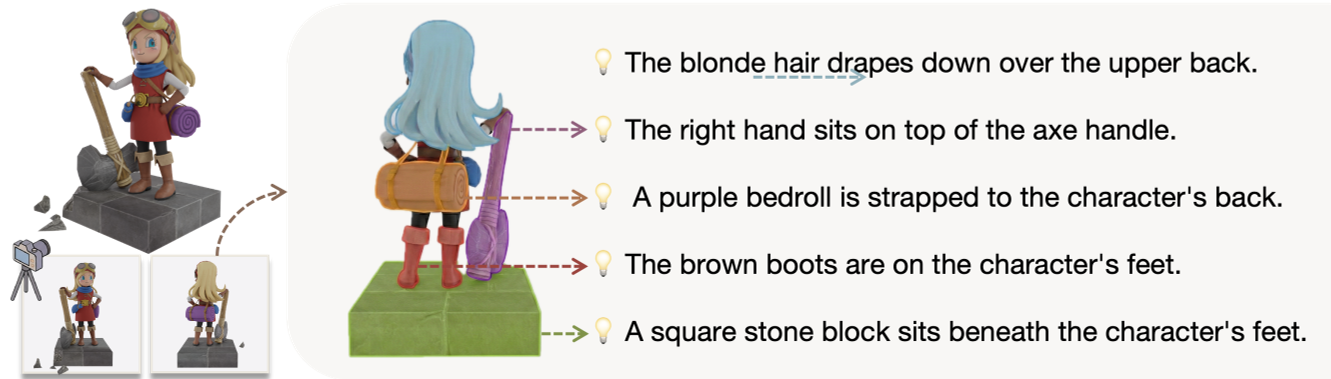
3. Dual Conditioning
The 3D generation backbone (based on TRELLIS.2) receives two signals:
- Visual signal: From the original front-view image.
- Knowledge signal: The HDiT hidden states representing the back-view logic.
Experiments & Results
Know3D was tested against top-tier models on HY3D-Bench. It didn't just match them; it set new benchmarks for semantic consistency.
- Controllability: Unlike previous "black box" models, Know3D can change the geometry of the back view based on text prompts (e.g., changing a single-strap bag to a double-strap bag).
- Plausibility: It avoids the "melted" or "warped" look common in other single-view generators by using the VLM's understanding of how objects usually look.

Key Ablation: Why Timestep 0.25?
An interesting finding in the paper (Table 2) shows that extracting features at t=0.25 in the denoising process works best. At this stage, the diffusion model has figured out the global layout but hasn't yet gotten bogged down in low-level pixel noise.
Critical Insight & Future Outlook
The performance gain of Know3D isn't just a "numbers game." It represents a shift in how we think about 3D generation. We are moving away from geometry reconstruction (copying points) toward semantic reconstruction (understanding what an object should be).
Limitations: The model is still beholden to its "brain." If the underlying MLLM (Qwen) fails to understand a complex prompt, the 3D model will still hallucinate incorrectly. However, as VLMs get stronger, Know3D will naturally improve without needing a single additional 3D mesh for training.
Takeaway: For the 3D industry, this means we are closer to professional creator tools where "fill in the blanks" isn't a random process, but a directed, creative one.