The paper introduces KaCGM (Kolmogorov-Arnold Causal Generative Model), a framework that parameterizes Structural Causal Models (SCMs) using Kolmogorov-Arnold Networks (KANs). It achieves SOTA performance in tabular causal inference, enabling joint observational, interventional, and counterfactual queries while providing transparent, symbolic structural equations.
TL;DR
KaCGM is a new class of causal generative models that replaces "black-box" neural structural equations with Kolmogorov-Arnold Networks (KANs). Unlike previous deep causal models that only offer structural interpretability (the graph), KaCGM provides functional interpretability, allowing users to extract closed-form symbolic equations (e.g., ) for every causal mechanism while remaining competitive with SOTA models in counterfactual accuracy.
Problem & Motivation: The "Black Box" of Causal Logic
In high-stakes domains like personalized medicine or public policy, knowing that an intervention works is insufficient; one must know why and how. While Structural Causal Models (SCMs) provide the mathematical framework for this, deep learning implementations of SCMs (like Causal Flows or Diffusion-based CGMs) essentially hide the "physics" of the system inside thousands of non-linear weights.
The authors identify a critical gap: Modern CGMs are Query-Agnostic (good) but Functionally Opaque (bad). Regulatory frameworks like the GDPR "Right to Explanation" demand a level of transparency that standard MLPs simply cannot provide.
Methodology: KANs as Structural Causal Mechanisms
The core innovation is the KaCGM architecture. Each endogenous variable in the causal graph is modeled as: where is the exogenous noise.
Why KANs?
Unlike standard MLPs that have fixed activation functions on neurons, KANs have learnable univariate functions on edges. This allows the model to:
- Prune: Automatically silence irrelevant parent-child influences.
- Symbolic Regression: Substitute a learned spline with a human-readable atom (like , , or polynomials).
- Handle Mixed Data: Through "KaCGM-mix," using Logistic-KANs to model categorical probability mass functions.
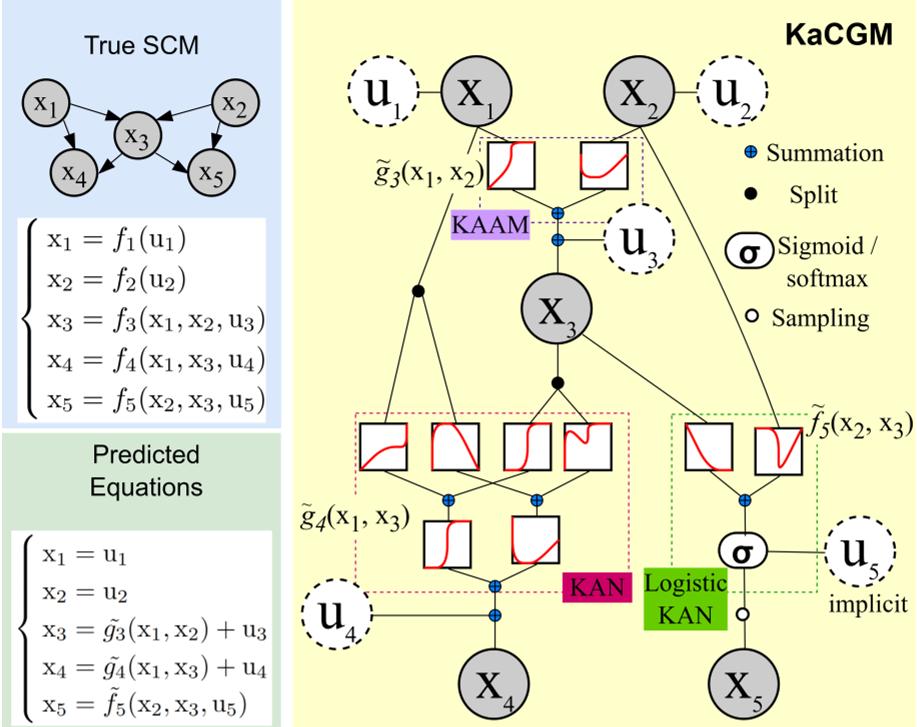 Fig 1: The KaCGM pipeline, from the causal graph to the symbolic structural equations.
Fig 1: The KaCGM pipeline, from the causal graph to the symbolic structural equations.
Experiments & Results
The authors tested KaCGM against heavyweights like DBCM (Diffusion-based) and Causal Flows.
1. The Additivity Trade-off
KaCGM excels when the underlying data-generating process (DGP) is additive. In synthetic tests on 11 different graph structures (Chains, Colliders, Forks), KaCGM reached near-perfect counterfactual MAE, outperforming universal density approximators (CausalFlows) when sample sizes were small (N=100 - 1000).
2. Sensitivity Analysis
A standout contribution is the "Validation Pipeline." Since we don't have ground truth in real-world data, the authors use HSIC (Hilbert-Schmidt Independence Criterion) to test if the inferred noise is truly independent of the parents. This acts as a "falsification" test—if the noise isn't independent, the model (and its explanations) shouldn't be trusted.
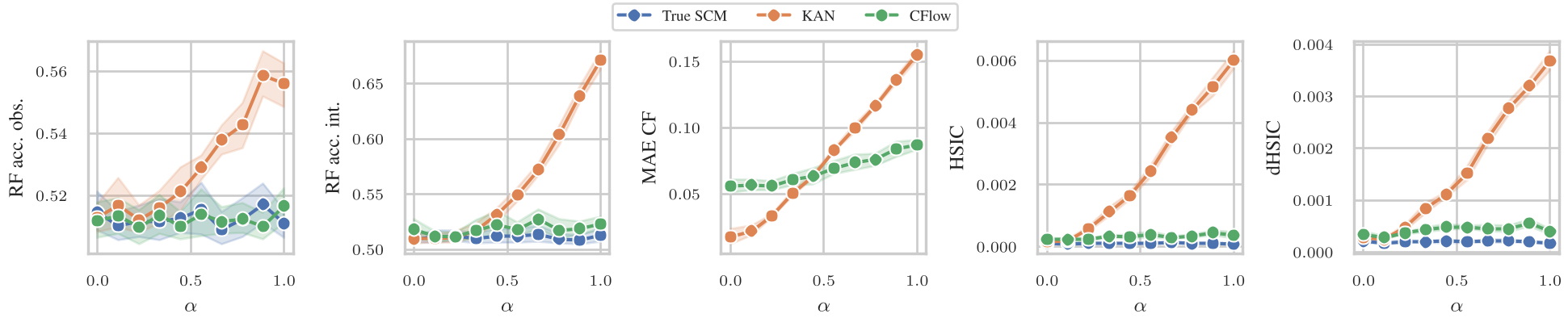 Fig 2: Sensitivity analysis showing how HSIC and MMD metrics can detect when the additive noise assumption is violated.
Fig 2: Sensitivity analysis showing how HSIC and MMD metrics can detect when the additive noise assumption is violated.
Real-World Case Study: Cardiovascular Risk
Applying KaCGM to a real cardiovascular dataset, the model didn't just predict the risk of Ischemia; it extracted the "Law of Ischemia": This quadratic relationship matches clinical intuition perfectly—cardiovascular risk accelerates non-linearly with age.
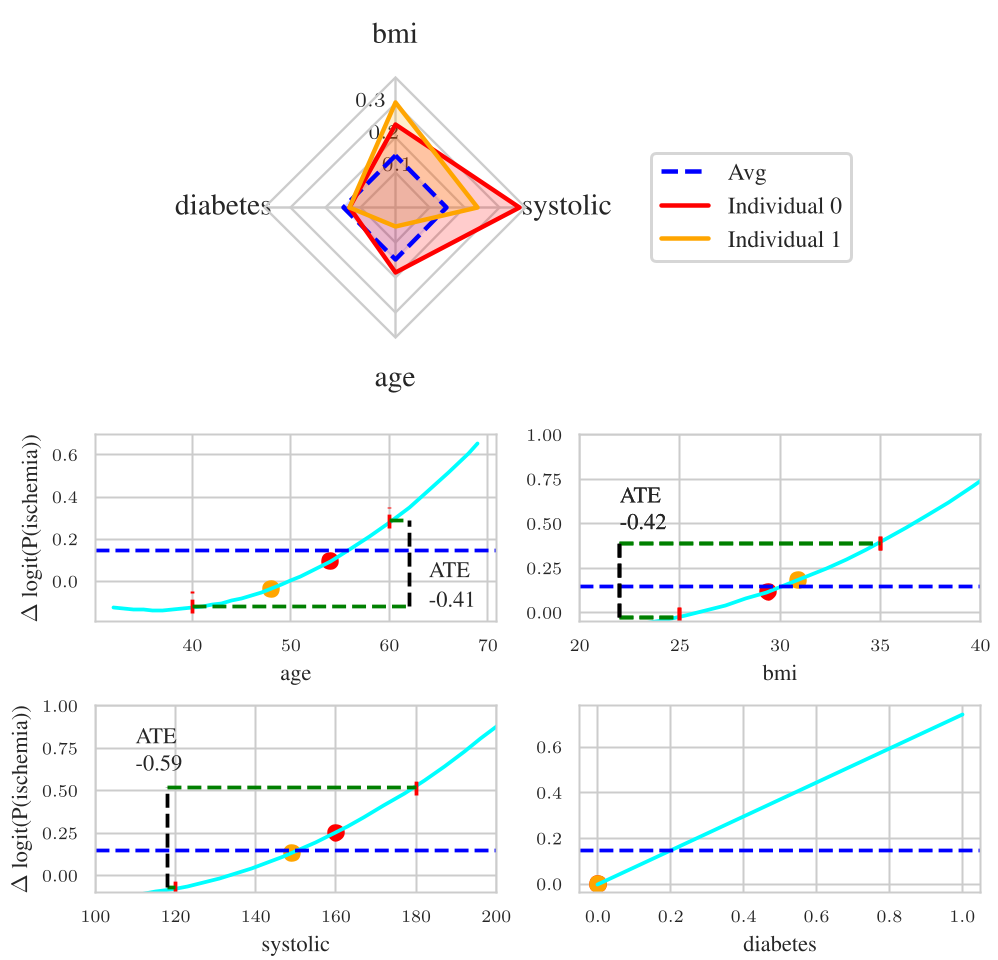 Fig 3: Probability Radar Plots (PRP) and Partial Dependence Plots (PDP) allowing clinicians to audit specific patient risks.
Fig 3: Probability Radar Plots (PRP) and Partial Dependence Plots (PDP) allowing clinicians to audit specific patient risks.
Critical Analysis & Conclusion
Takeaway: KaCGM proves that we don't need to sacrifice performance for interpretability in tabular causal tasks. By using KANs, the model becomes a "glass-box" that can be symbolically audited.
Limitations:
- Additivity Bias: If the true world is highly "entangled" (non-additive or heteroscedastic), KaCGM will struggle compared to black-box Causal Flows.
- Scalability: While powerful for tabular data (10-50 variables), extracting symbolic expressions for graphs with hundreds of nodes remains a challenge.
Future Work: The authors suggest integrating KANs into Normalizing Flow architectures, potentially creating a "Universal Interpretable Approximator" for even more complex causal systems.