本文提出了 LaMP,一个双专家 Vision-Language-Action (VLA) 框架,通过引入稠密 3D 场景流(Scene Flow)作为潜在运动先验,显著增强了机器人的操纵能力。该方法在 LIBERO 和 SimplerEnv 等多个基准测试中刷新了 SOTA 记录,尤其在长程任务和 OOD 鲁棒性上表现优异。
TL;DR
传统的 Vision-Language-Action (VLA) 模型往往像是在“看图说话”,试图直接从 2D 像素跳跃到控制指令。LaMP (Latent Motion Prior) 引入了一个革命性的中间层:稠密 3D 场景流。通过让模型先预见物体将如何移动,再决定如何操作,LaMP 在 LIBERO 全套基准测试和真实世界复杂任务(如折叠毛巾、制作早餐)中表现出了跨代级的稳定性,尤其在处理位置偏移和相机变动等 OOD 场景时,鲁棒性提升了近 10%。
背景定位
目前大火的 VLA 模型(如 OpenVLA, π0)虽然具备极强的语义理解能力,但在物理世界的“几何直觉”上却不尽如人意。它们在面对需要精准深度感知和触觉反馈的任务时,常因缺乏 3D 建模而导致动作崩坏。LaMP 的出现,标志着 VLA 从单纯的语义回归向“语义+几何预测”双驱动演进。
痛点深挖:2D 语义与 3D 物理的断层
人类在移动物体前,大脑会隐式地生成世界模型:物体朝哪动?哪里会发生接触?现有的 VLA 往往错在:
- 维度缺失:纯 2D 视觉特征在处理 tight-clearance(窄间隙)任务时无法提供深度信息。
- 隐式学习困难:仅靠动作标签(Action Labels)反向推理 3D 动力学,效率低且容易因环境扰动而失效。
- 计算冗余:如果要生成完整的视频或多步未来点云,计算延迟会让机器人推理变得极其缓慢。
核心方法:Motion Expert 与门控运动导引
LaMP 提出了一个优雅的双专家架构,将“运动先验”与“动作执行”解耦:
1. Motion Expert (运动专家)
它不是在预测像素,而是在预测一个 $K imes T imes 3$ 的 3D 位移网格 $(\Delta u, \Delta v, \Delta d)$。该专家基于 Conditional Flow Matching 训练,能够捕捉物体在三维空间中的连续位移。
2. 一步去噪策略 (One-step Denoising)
这是 LaMP 推理效率的关键。模型不需要像普通的扩散模型那样迭代 50 步来生成完美的运动图,而是只运行 1 个去噪步 并提取其特征。这些隐状态 zm 已经包含了足够的任务相关动力学信息。
3. Gated Cross-Attention (门控交叉注意力)
为了保护 VLM 预训练的语义知识不被几何噪声冲淡,作者设计了一个学到的“闸门” $g$。初始时闸门接近关闭,通过训练,模型自主决定在哪些需要空间精度的时刻(如抓取的瞬间)引入 3D 几何特征。
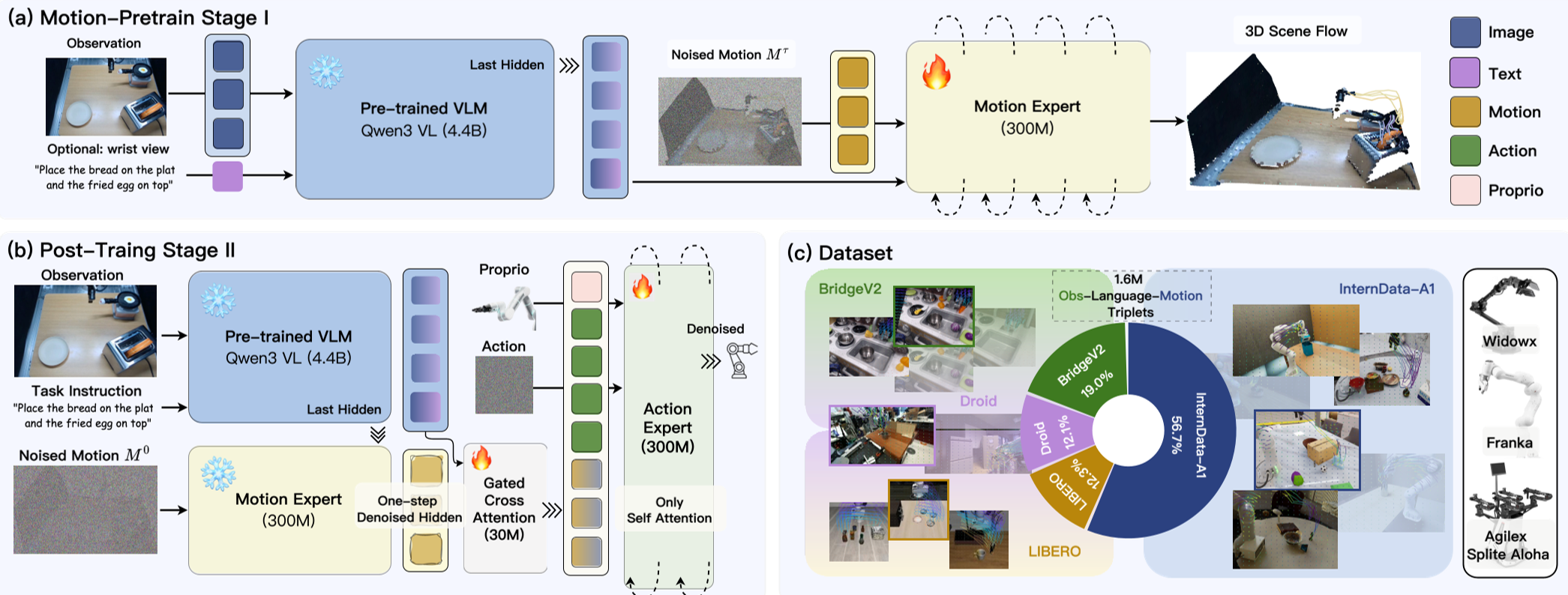 图 1:LaMP 整体流程:(a) 运动预训练,(b) 动作后训练,(c) 数据固化。
图 1:LaMP 整体流程:(a) 运动预训练,(b) 动作后训练,(c) 数据固化。
实验战绩:全线突破
SOTA 对比
在 LIBERO 仿真环境中,LaMP 几乎在所有子项中都处于领先地位。特别是在 LIBERO-Long (长程任务) 中,它的表现远超 π0.5 和 GR00T。这证明了拥有“运动预见性”能有效减少长链条动作中的误差积累(Compounding Errors)。
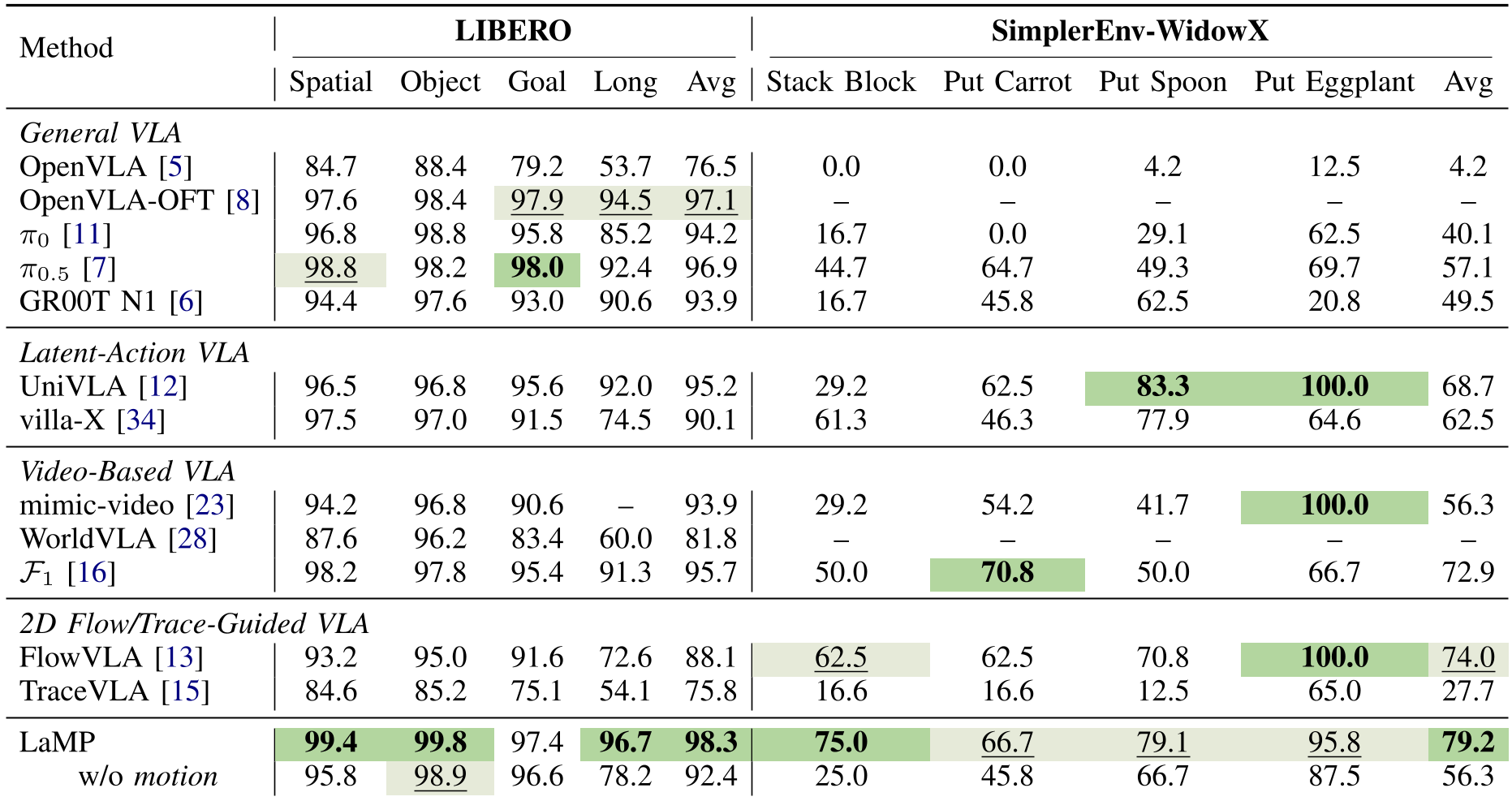
消融实验:为什么 3D 场景流不可或缺?
作者对比了“无运动先验”和“2D 光流先验”两种变体。结果显示:
- 去掉运动专家:在堆叠方块任务中成功率从 75.0% 暴跌至 25.0%。
- 仅使用 2D 光流:在深层交互任务(如把勺子放进碗里)中显著落后于 3D 方案。这验证了核心直觉:物理操纵本质上是 3D 的。
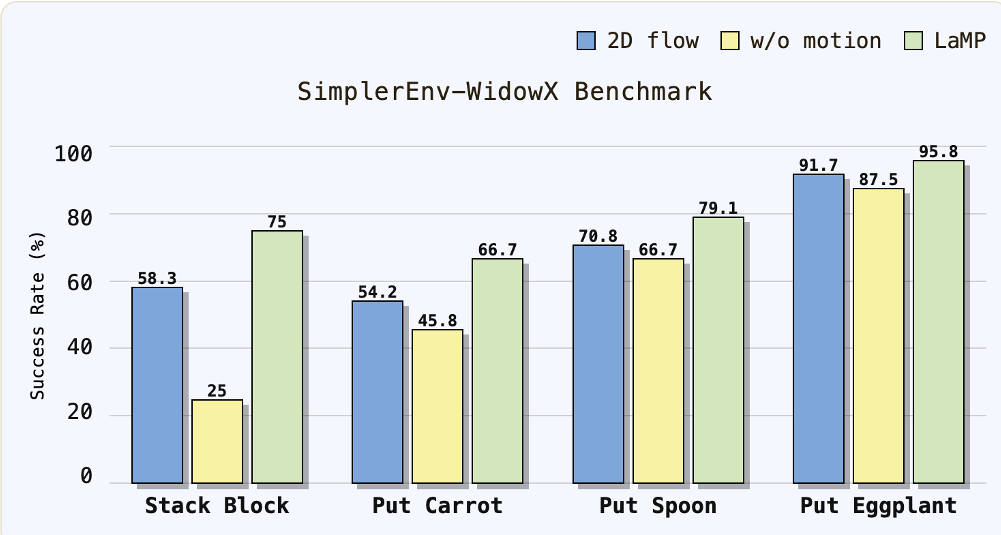 图 2:3D 几何 vs 2D 像素的性能对比,证明了深度信息对接触式任务的关键作用。
图 2:3D 几何 vs 2D 像素的性能对比,证明了深度信息对接触式任务的关键作用。
深度洞察
LaMP 的成功之处在于它找到了一种轻量化集成物理模型的方法。它没有试图去做一个极其笨重的世界模型(World Model),而是将其简化为一个增强特征的“运动先验”。
- 优点:兼具 VLM 的强语义和 3D 模型的高精度,且一步去噪保证了实时的推理速度(可在线部署)。
- 局限性:目前的运动栅格 (20x20) 分辨率仍较低,对于极其纤细的物体(如缝纫针)可能感知不足。未来结合多尺度栅格或自适应采样将是重要的优化方向。
总结
LaMP 展示了 3D 场景流不仅是动作的结果,更是动作的先导。通过将 3D 几何 foresight 注入 VLA 框架,机器人终于开始“带着脑子”去规划每一寸位移。这为构建更通用、更稳健的具身智能体提供了一条极其清晰的路径。
 图 3:真实世界任务演示。红色轨迹显示了模型在动作执行前对未来 3D 路径的预测,这正是 LaMP 稳健性的源泉。
图 3:真实世界任务演示。红色轨迹显示了模型在动作执行前对未来 3D 路径的预测,这正是 LaMP 稳健性的源泉。