The paper introduces a self-expressive autoencoding framework that transforms a pretrained LLM into a high-efficiency token compressor/decompressor. By fine-tuning with LoRA and an extended vocabulary of discrete "Z-tokens," the model achieves up to 18× compression ratio while significantly accelerating inference and reducing memory overhead.
Executive Summary
TL;DR: Researchers have unlocked a "hidden language" within LLMs. By teaching a model to translate natural text into a compact, internal symbolic space called Z-tokens, they have achieved massive context reduction (up to 18×) without the typical performance "cliff" associated with context pruning. This allows the LLM to function as both a compressor and a decompressor, essentially "thinking" in shorthand before expanding back to natural language.
Background: Historically, handling long context has been an arms race against the $O(N^2)$ complexity of attention. While methods like ICAE or AutoCompressor attempted to squash context into fixed vectors, they acted as "black boxes." This paper treats compression not as a side-task, but as a translation task between human English and the LLM's own internal abstractions.
The Motivation: Why Heuristics Fail
Traditional context management follows two flawed paths:
- Pruning/Merging: Deleting tokens that "look" unimportant. The problem? A token that seems redundant to a similarity algorithm might be the pivot for a complex logical inference later.
- Continuous Embeddings: Squashing text into a fixed-size vector. This is "lossy" by design—it doesn't matter if the input is a 10-word sentence or a 1000-word essay; it gets the same "storage space," leading to information bottlenecks.
The authors' Insight: Natural language is already a form of compression (e.g., the phrase "Industrial Revolution" replaces pages of historical data). Why not let the LLM invent its own "idioms" (Z-tokens) to represent complex spans of text?
Methodology: Speaking in Z-Tokens
The framework consists of three stages: Compression, Latent Reasoning, and Decompression.
1. The Variable-Length Advantage
Unlike previous methods, the compressor uses an autoregressive head. It doesn't output a fixed number of tokens; it generates as many Z-tokens as it needs based on the semantic density of the input.
- Simple text: Compressed aggressively.
- Complex/Dense text: Receives more Z-tokens for fidelity.
2. Discretization via Gumbel-Softmax
To keep the system differentiable while maintaining a discrete "vocabulary" for the Z-tokens, the researchers used a Gumbel-Softmax estimator with a pass-through gradient. This ensures that during inference, the Z-tokens are actual symbolic IDs, not fuzzy vectors.
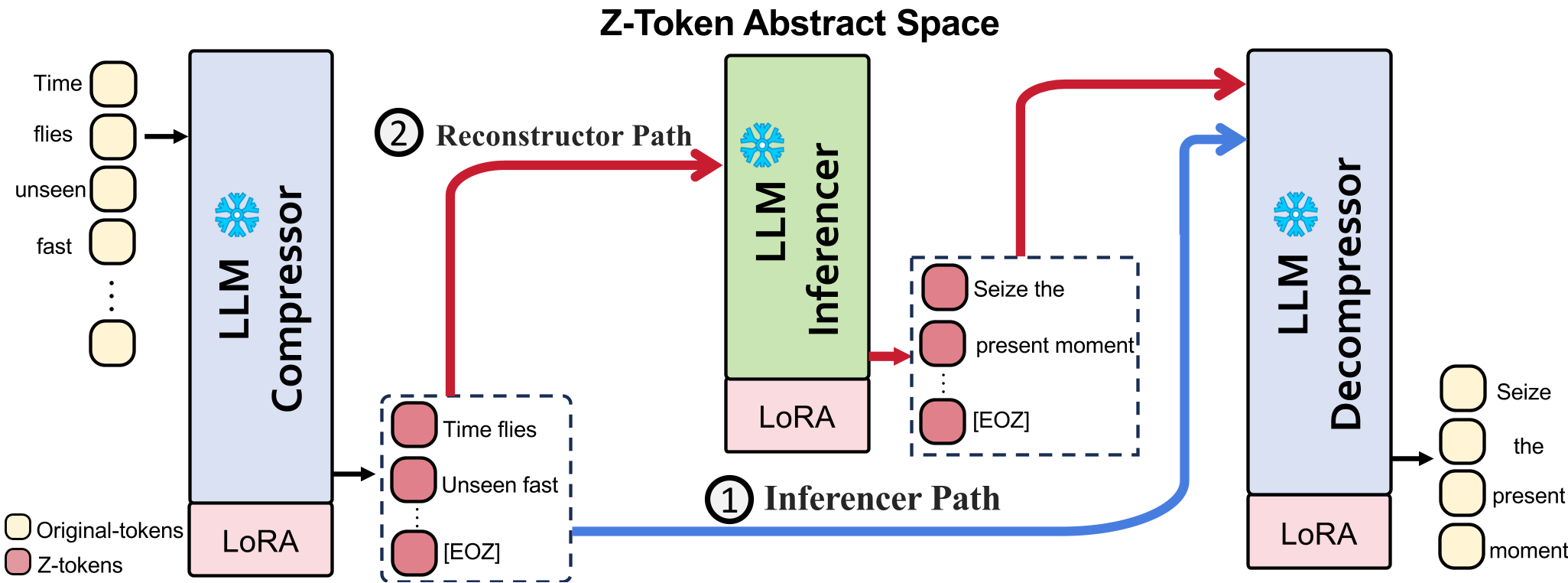 Figure 1: The dual paradigm of the decompressor. It can either reconstruct the original text for human readability or act as an 'Inferencer' to answer questions directly from the shorthand.
Figure 1: The dual paradigm of the decompressor. It can either reconstruct the original text for human readability or act as an 'Inferencer' to answer questions directly from the shorthand.
Experiments: Does it actually work?
The results are striking across Wikipedia, HotpotQA, and NarrativeQA.
Performance & Fidelity
On the Wikipedia reconstruction task, the Z-token approach achieved a BLEU-4 score of 99.31 (at 4x nominal compression). This effectively means the reconstruction is nearly perfect, a feat previous fixed-embedding models struggled with.
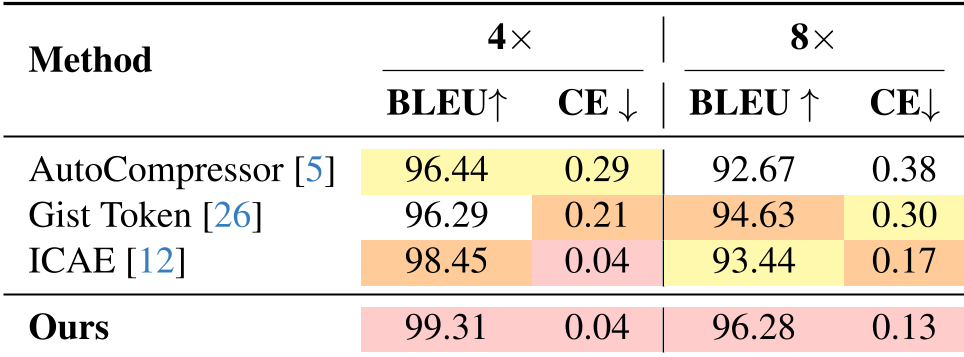 Table 2: Comparison against SOTA baselines. The 'Ours' row shows superior retention of BLEU score even as compression increases.
Table 2: Comparison against SOTA baselines. The 'Ours' row shows superior retention of BLEU score even as compression increases.
Efficiency Gains
By operating in the Z-token space (where 1024 tokens might be represented by just 128), the model achieved a 2.1× speedup in total inference time and significant memory savings—dropping KV cache requirements substantially.
Deep Insight: The Polysemy of Z-Tokens
The most fascinating finding is the interpretability analysis. Z-tokens are not a 1:1 mapping to words. Instead, they are polysemous semantic units.
- The same Z-token might appear in different contexts to represent "Government Intervention."
- In one context, it decodes to "fiscal restructuring"; in another, to "economic reforms."
This suggests the LLM has developed its own conceptual ontology, where tokens represent high-level ideas rather than specific strings.
Critical Analysis & Future Outlook
Strengths:
- Variable Length: Adapting to density is the "holy grail" of compression.
- Interpretability: The fact that Z-tokens are discrete allows us to measure "semantic consistency," proving the model isn't just hallucinating shorthand.
Limitations:
- Window Coordination: For extremely long books, the model currently relies on sliding windows. A "global" Z-token mechanism to resolve dependencies across windows is still missing.
- Task-Awareness: The current compression is general. Future versions could be "task-aware"—compressing more heavily for summarization and more lightly for legal fact-checking.
Conclusion: This work proves that the "quadratic wall" of Transformers can be tunnelled through. By allowing LLMs to develop their own internal, efficient symbolic language, we move closer to models that can process million-token contexts with the efficiency of a human reader.