本文提出 UniReasoner 框架,将 LLM 作为“通用推理器”引入文本生成图像系统。该方法采用 Draft-Evaluate-Diffuse (草图-评估-扩散) 管线,在维持扩散模型底座不变的情况下,显著提升了生成结果的语义一致性。
TL;DR
即使是最强的多模态 LLM,也会在绘画时“数不清苹果”或“放错位置”。本文提出的 UniReasoner 框架洞察到了 LLM “眼高手低”(视觉验证强、直接生成弱)的特性,通过 “先画草图、自我批评、再精修成图” 的三步走策略,在不增加扩散模型负担的前提下,大幅刷新了图像生成的一致性标准。
1. 痛点:为什么 LLM “懂判别”却“画错”?
在当前的统一多模态模型(如 BAGEL)中,我们常观察到一个讽刺的现象:你让模型画“4 个苹果”,它画了 5 个;但当你把这张画丢回给它并问“这里有几个苹果”时,它能准确回答“5 个”。
这种理解-生成差距 (Understanding-Generation Gap) 表明,模型内部的知识是充足的,但单次、线性的生成过程(从 Text Embedding 直接映射到 Pixels)无法有效激活这些细粒度的推理约束。

2. 核心直觉:从编码器到“通用推理器”
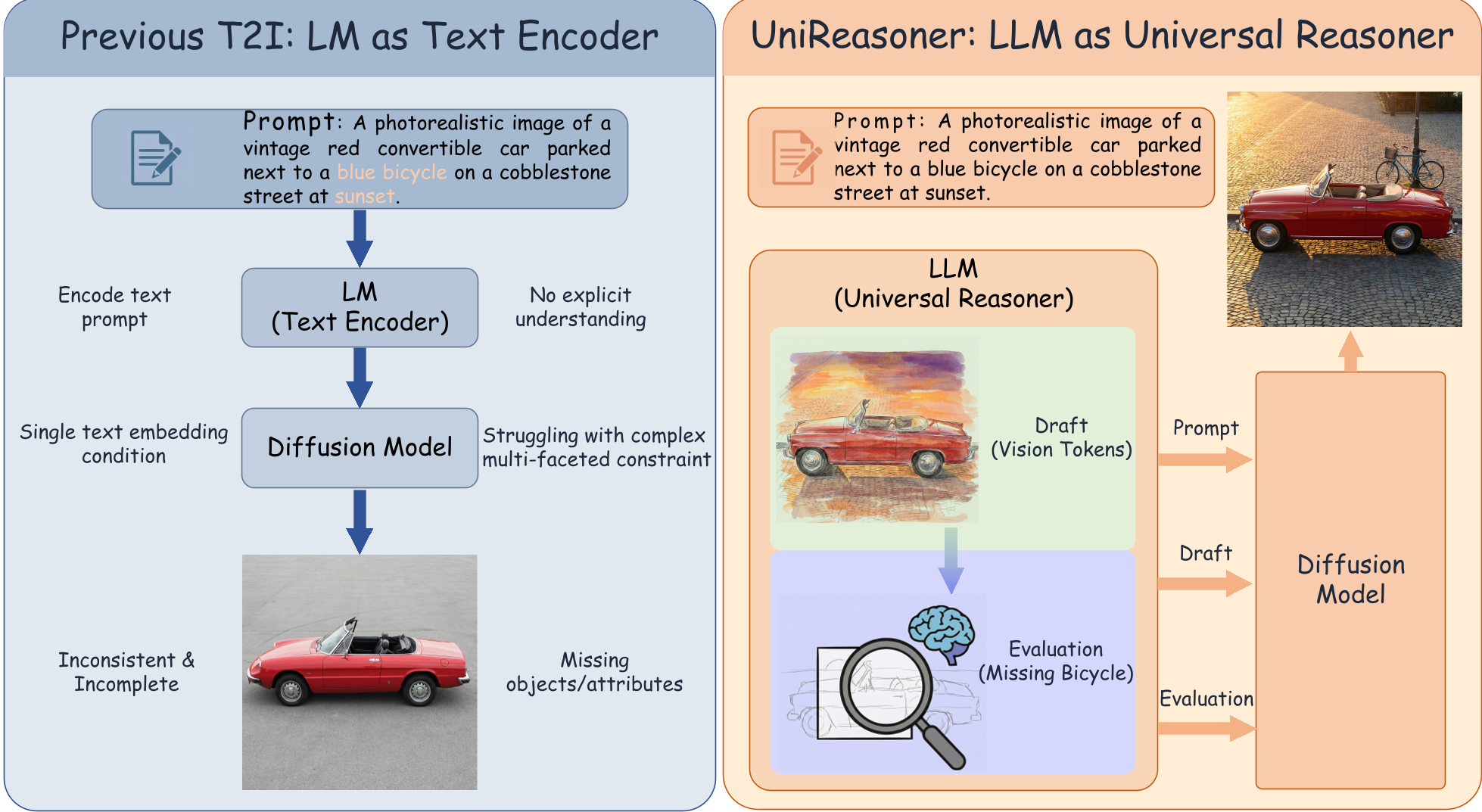
UniReasoner 的核心设计哲学是将 LLM 从一个被动的“翻译官”(Text Encoder)转变为主动的“监工”。它不再指望扩散模型一次性理解复杂的 Prompt,而是通过以下三个环节进行推理闭环:
第一步:视觉草图 (Visual Drafting)
LLM 首先生成一组离散的视觉 Token。这些 Token 基于 SigLIP-2 的离散化表示,它们不像像素那样精细,但蕴含了极强的语义分布。这相当于在动笔前,模型先给出了一个“排版方案”。
第二步:落地自评 (Grounded Evaluation)
这是最关键的一步。LLM 会审视自己刚才生成的草图,并问自己:“这个草图满足 Prompt 吗?”。如果发现草图里少了一个杯子或颜色错了,它会生成一段具体的文字说明(如“左侧缺少一个蓝色的瓶子”)。这种显式的纠错信号将 LLM 的判断力转化成了可操作的指令。
第三步:联合扩散 (Joint Diffusion)
扩散模型(实验中采用 SANA/FLUX 等)此时不再只盯着原始 Prompt 看,它同时参考:
- 原始 Prompt(全局意图)
- 视觉草图(空间锚点)
- 评估报告(纠错指令)
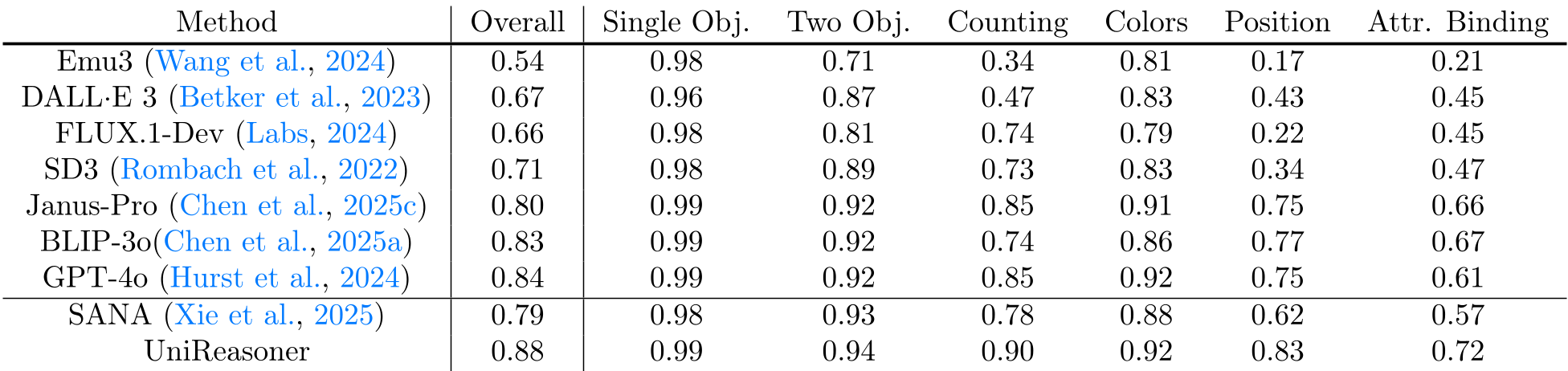
3. 实验战绩:不改底座,暴力提分
UniReasoner 最令人印象深刻的一点是它的兼容性。作者冻结了扩散模型底座(SANA),仅通过改变输入层,就实现了质的飞跃。
- GenEval 榜单:在最具挑战性的“计数”和“位置”任务上,UniReasoner 相比 baseline 提升了 10~20 个百分点。
- 语义保真度:多源条件输入(Text + Draft + Eval)被证明比单纯的 Prompt 扩写(Prompt Rewriting)有效得多,因为它提供了视觉空间上的实体化参考。
4. 深度洞察
为什么离散化的 SigLIP Token 比 VQGAN 的 Token 更好用? 论文指出,基于重建任务的 VQGAN 关注的是像素复原,而 SigLIP 关注的是语义。对于 LLM 这种“文字生物”来说,SigLIP 的 Token 更容易被自回归地预测,也更容易与其内部的语义空间挂钩。这意味着,草图本身就携带了高层次的逻辑,而非混乱的噪声。
5. 总结与局限
UniReasoner 成功地将 LLM 的角色从“信息压缩器”转变为“生成决策者”。它不需要海量的重新训练,而是利用现有的 LLM 推理路径闭合了生成循环。
局限性:
- 推理开销:由于引入了草图生成和文字评估两个额外的自回归步骤,首屏出图的延迟(Latency)会有所增加。
- 训练依赖:构建“反面教材”(Hard-Negative Mining)来训练评估器需要高质量的 Vision-Language 模型支持。
未来的视觉生成系统可能不再是单向的“输入-生成”,而是充满了这种推理、验证与修正的对话式过程。
