The paper introduces Large Reward Models (LRMs), a framework that adapts foundation Vision-Language Models (specifically Qwen3-VL) into dense, frame-level reward generators to bridge the performance gap in robotic Reinforcement Learning. By fine-tuning on a multi-domain dataset of 24 sources, LRMs provide online feedback that allows robots to surpass the limitations of imitation learning and achieve SOTA results in zero-shot manipulation tasks.
TL;DR
Researchers from USC and Toyota Research Institute have introduced Large Reward Models (LRMs), a breakthrough framework that transforms general-purpose Vision-Language Models (VLMs) into precision reward generators for robots. By providing dense, frame-level feedback across three distinct "cognitive" dimensions, LRMs allow robots to refine their behaviors online, significantly outperforming existing VLM-rewarders and narrowing the gap with privileged simulator "oracle" rewards—all without a single line of manual reward code.
The Core Challenge: The "Reward Gap" in Robotics
In the quest for generalist robots, Imitation Learning (IL) has been the go-to starting point. However, IL policies often plateau; they can mimic, but they can't easily "correct" themselves when things go slightly off-script. Reinforcement Learning (RL) is the solution for continuous refinement, but RL requires a Reward Function.
Traditionally, these functions are either:
- Hand-coded: Brittle and task-specific (e.g., measuring the exact distance between a gripper and a mug).
- Episode-level VLM scores: Too slow and "blurry." They tell the robot it failed after the episode is over, which is useless for fixing a slip-up in the middle of a motion.
LRMs solve this by providing instant, frame-by-frame guidance.
Methodology: The Tri-Faceted Reward Engine
The authors specialized a Qwen3-VL-8B backbone using a diverse dataset from 24 sources (including human videos and multi-robot data). The innovation lies in not asking the VLM a single question, but utilizing three distinct reward "modalities":
- Temporal Contrastive Reward (): Compares two frames ( and ) to see which is closer to the goal. This provides a relative gradient that is robust to visual noise.
- Absolute Progress Reward (): Regresses a value from 0.0 to 1.0. It acts as a "spatial-temporal speedometer" for the task.
- Task Completion Reward (): A binary "anchor" that confirms if the semantic requirements of the goal are met.
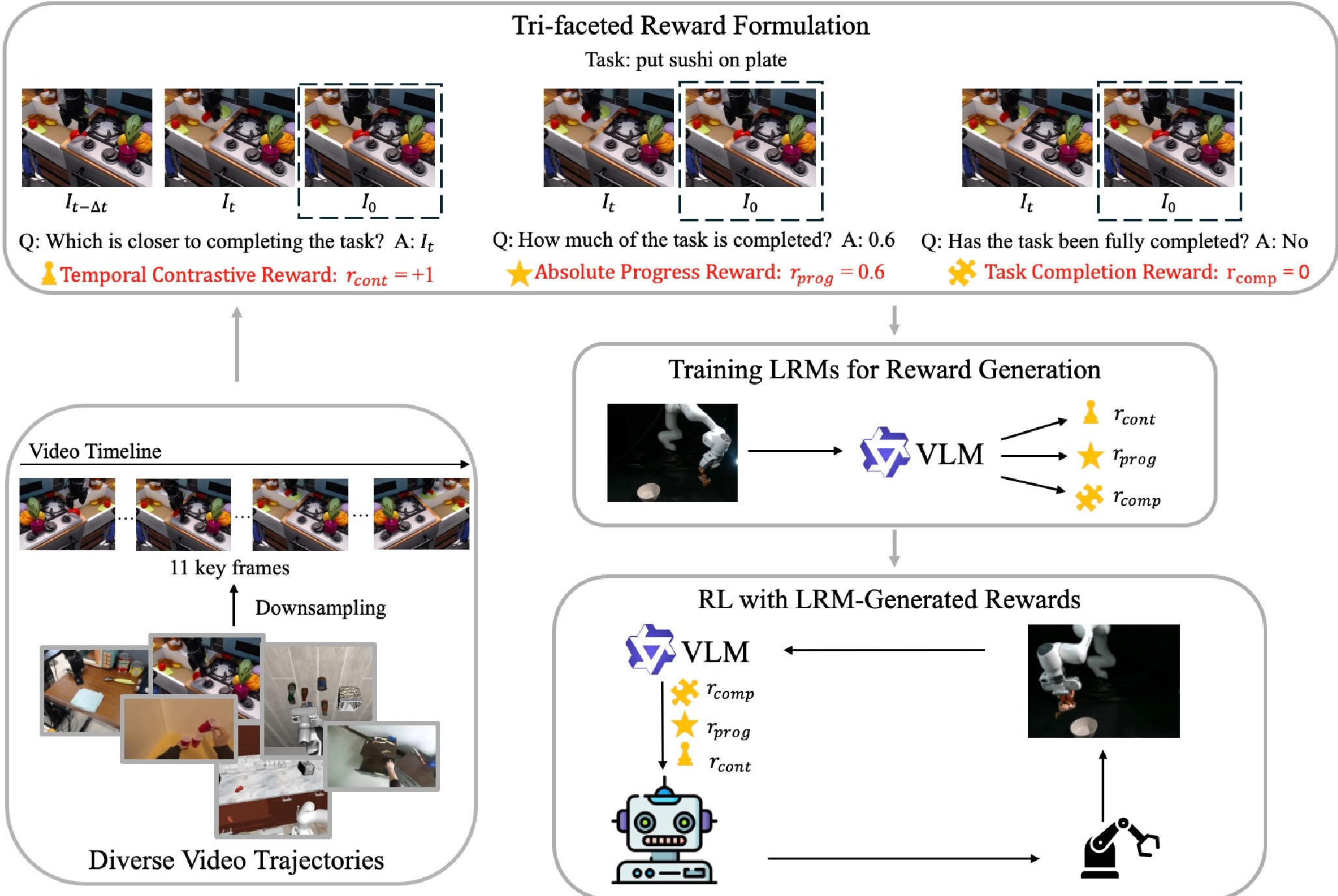 Figure 1: The LRM framework architecture. Note the use of LoRA for specialization and the integration of diverse data sources.
Figure 1: The LRM framework architecture. Note the use of LoRA for specialization and the integration of diverse data sources.
To ensure the model doesn't just "guess," the authors utilized Chain-of-Thought (CoT) reasoning. The LRM must first describe the physical changes it sees (e.g., "The hand is now grasping the toy") before outputting a numerical reward.
Experimental Breakthroughs
The LRM was tested on the ManiSkill3 benchmark—a grueling environment for robots. Critically, the LRM had never seen these environments during training (Zero-shot).
1. Superiority over SOTA
The LRM outperformed current leaders in the field, including RoboReward and Robometer.
| Modality | Success Rate (%) | | :--- | :--- | | LRM (Task Completion) | 60.93% | | RoboReward-8B | 59.06% | | Robometer-4B | 56.56% | | SFT Baseline (No RL) | 56.88% |
2. Real-World Self-Improvement
In a physical "pick-and-place" task, a robot initially trained via imitation often failed to precisely place a toy inside a bowl. By using the LRM as an autonomous judge, researchers filtered successful trajectories and performed RL refinement. The result? The success rate jumped from 38.3% to 51.7%.
 Figure 2: The LRM-refined policy (right) successfully places the giraffe in the bowl, whereas the imitation baseline (left) misses the target.
Figure 2: The LRM-refined policy (right) successfully places the giraffe in the bowl, whereas the imitation baseline (left) misses the target.
Deep Insight: Why Does This Work?
The secret is the Emergent Synchronization. As the robot's policy improves through RL, its movements become more "legible" to the LRM. Because the LRM was trained on human and expert robot data, it "expects" certain physical transitions. When the robot starts moving in a way that creates these clear semantic markers, the reward signal becomes even cleaner, creating a virtuous cycle of improvement.
Critical Analysis & Future Outlook
Takeaway: This work proves that we no longer need to write manual reward functions. Foundation models already "understand" what a successful task looks like; we just need to extract that knowledge in a format that RL algorithms can digest (dense, frame-level signals).
Limitations: While powerful, querying an 8B parameter model every few steps is computationally expensive. The "Interval-Hold" strategy used here (querying every steps) is a smart workaround, but for ultra-high-speed dynamics (e.g., catching a falling object), a more distilled, lightweight reward-head might be necessary.
Conclusion: Large Reward Models represent the "Missing Link" between massive VLM pre-training and real-world physical dexterity.