本文深入研究了后期交互(Late Interaction)检索模型的底层动态,重点分析了多向量评分中的“长度偏见”以及 MaxSim 算子之外的 token 相似度分布。研究对比了以 ColBERT 为代表的双向编码器模型与新型因果(Causal)编码器模型在 NanoBEIR 评测集上的表现。
TL;DR
在追求更精准检索的道路上,以 ColBERT 为代表的 Late Interaction (后期交互) 模型通过 MaxSim 算子实现了细粒度的语义匹配。然而,本文揭示了一个残酷的现实:如果你在多向量(Multi-vector)检索中使用 Causal (因果) 编码器,模型会产生不可避免的 长度偏见 (Length Bias) —— 它会盲目地认为越长的文档越相关。相比之下,双向(Bi-directional)模型虽然表现更稳健,但在极端长文本下依然存在风险。
1. 痛点:被“注水”的长文本骗了?
近年来,随着大模型(LLM)的兴起,许多团队尝试直接利用因果 LLM 生成 Embedding。但在后期交互框架下,这引入了一个致命的数学逻辑悖论。
在 Late Interaction 检索中,得分由以下 MaxSim 公式决定:
研究直觉:对于因果模型(如 GPT 系列),增加 token 只是在原本的嵌入集合中添加新向量,而不会改变已有向量的表示。这意味着 max 操作的结果只会单调递增。换句话说,文档越长,包含“高分 token”的概率就越大,即使这些 token 与查询完全无关。
2. 架构解析:因果 vs 双向
作者将模型分为四类进行实测,试图寻找偏见的根源:

- 因果多向量 (Causal Multi-vector):如
jina-embeddings-v4,它是长度偏见的重灾区。 - 双向多向量 (Bi-directional Multi-vector):如
ModernColBERT,由于全注意力机制的存在,后续 token 会改变前文的 Contextualized Embedding,从而在理论上抵消偏见。
3. 实验见证:多给点字,分就越高?
实验在 NanoBEIR 数据集上展开,结果触目惊心。
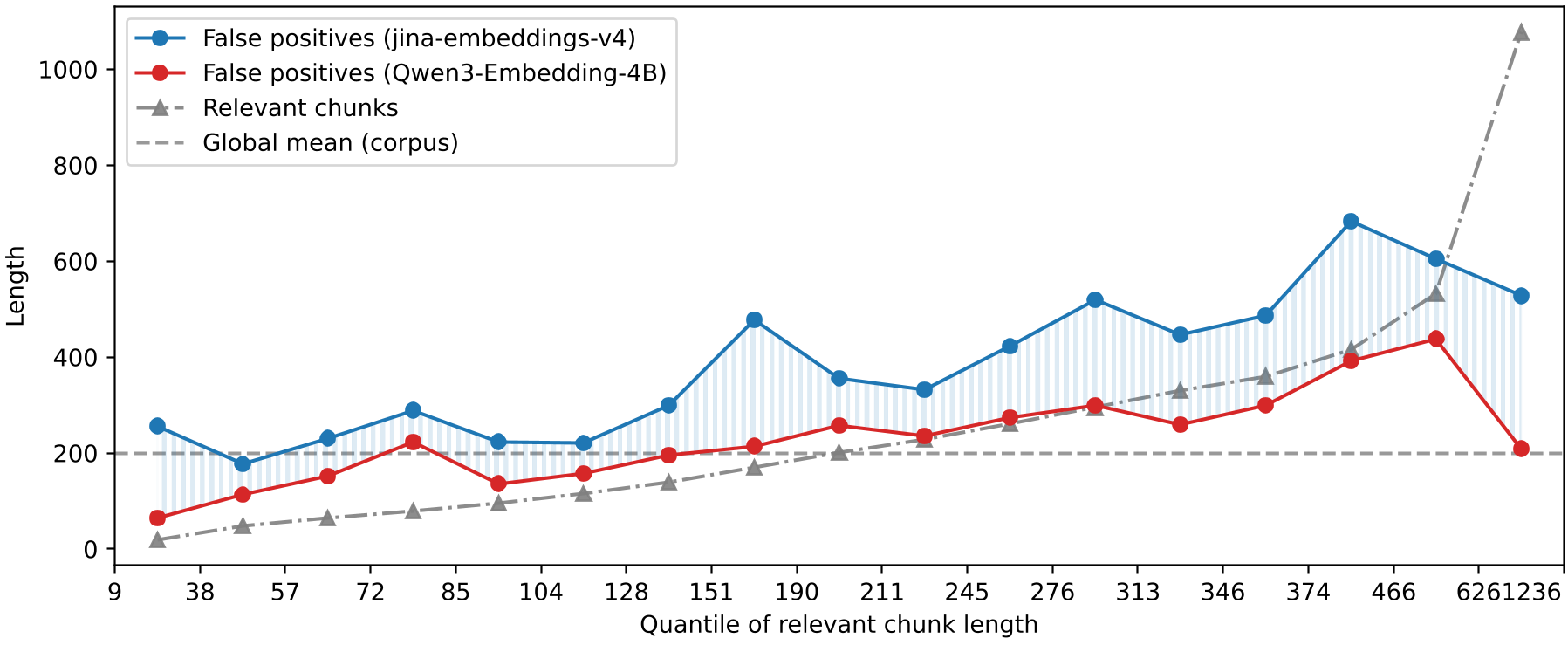
从上图可以看出,因果多向量模型检索出的 False Positives (误报) 长度远超真实相关文档的长度(图中蓝色柱状远高于绿色)。而单向量模型(Qwen3)则表现得非常克制。这证明了多向量表示 + 因果架构是产生偏见的“罪魁祸首”。
在 nDCG 的损耗测试中(如下图):
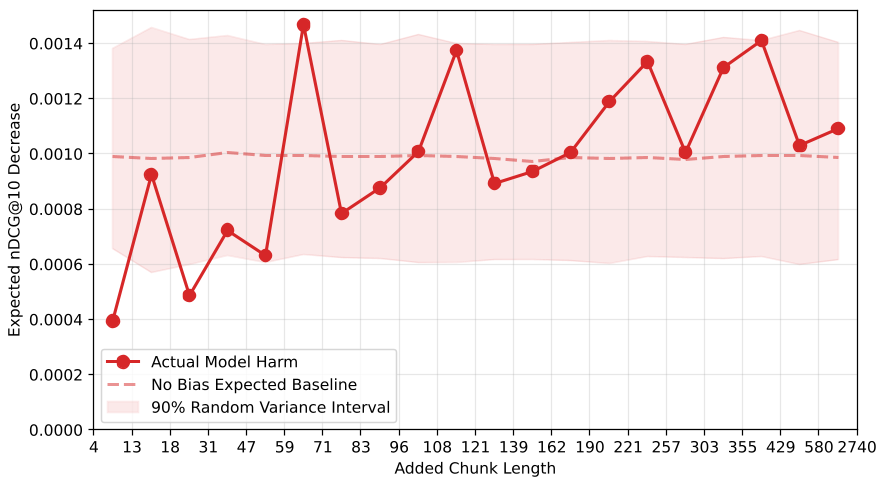 我们可以看到
我们可以看到 jina-embeddings-v4 (a) 的排名能力随着文档变长而显著下降,而双向模型 (c, d) 虽然在中间区域稳健,但在处理极长文本时仍显露疲态。
4. 相似度分布:MaxSim 真的浪费信息了吗?
许多人质疑 MaxSim 只取每个查询 token 匹配到的最高分,是否太浪费了?如果一个文档有 10 个 0.8 分的匹配点,难道不比只有 1 个 0.9 分匹配点的文档更相关吗?
作者分析了检索失败样本的 token 相似度分布曲线:
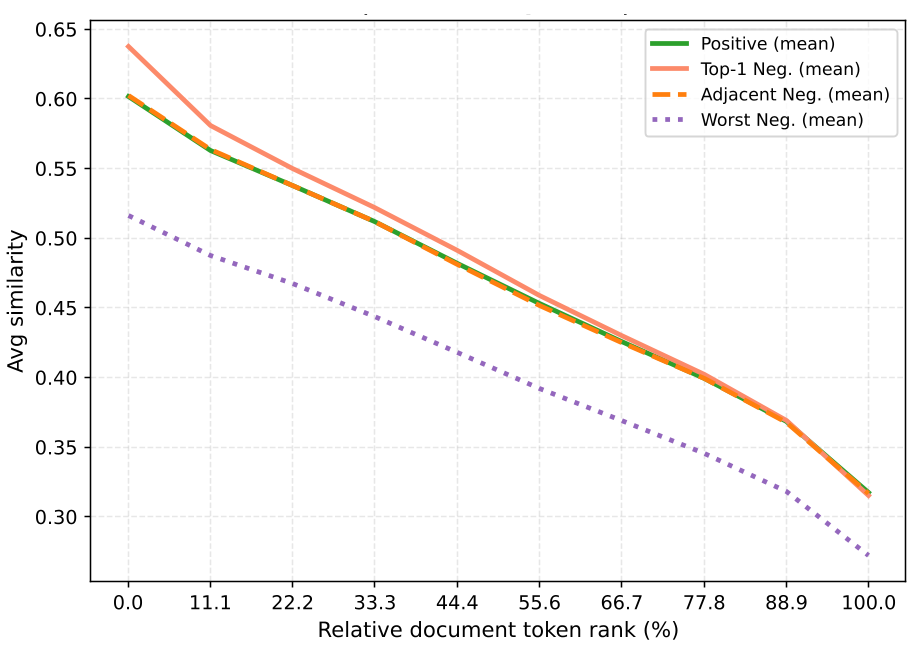
结论令人惊讶:除了极个别数据集(如 Argunana),大部分情况下,正样本和负样本在 Top-1 之后的相似度得分曲线几乎是重合的。这意味着在当前的 Late Interaction 范式下,除了最强的那个匹配点,剩下的信息基本都是“噪声”。
5. 总结与启示
这篇工作给了 IR 社区两个关键信号:
- 别盲信因果 LLM 生成 IR Embedding:在 Multi-vector 场景下,传统的双向 Bertram 类架构(或其现代变体 ModernVBERT)依然是更科学的选择。
- 算子优化空间有限:想要通过修改
MaxSim算子(例如引入 Top-K 均值)来大幅提升通用检索性能可能行不通,因为 token 级别的区分度在 Top-1 之后迅速坍缩。
局限性:该研究主要基于 NanoBEIR 这种小规模 benchmark,在工业级超大规模语料库上的动态可能更加复杂,值得深度开发者关注。