本文提出了 LatentFlowSR,一种基于潜空间条件流匹配(CFM)的音频超分辨率框架。该方法通过预训练的噪声鲁棒自编码器将低资源音频映射至连续潜空间,并利用 U-Net 结构的 CFM 模型在潜空间内高效生成高频细节,实现了涵盖语音、音效、音乐等多种音频类型的 SOTA 性能。
TL;DR
传统的音频超分往往在语音任务上“偏科”,且在追求高采样率时面临计算爆炸。LatentFlowSR 通过在噪声鲁棒的潜空间中引入条件流匹配 (Conditional Flow Matching, CFM),不仅在语音、音效、音乐三大场景全面超越现有 SOTA(如 AudioSR, FlashSR),更将推理计算量(FLOPs)降低到了惊人的 1G 以下。
1. 痛点:音频超分不只是“猜”频谱
音频超分辨率(Audio SR)的核心任务是补全信号丢失的高频分量。目前的瓶颈主要有三:
- 维度灾难:直接在波形域生成,序列长度动辄数万点,效率极低。
- 信息丢失:在 Mel 谱域建模虽然快,但相位信息的丢失会造成人工伪影(Artifacts)。
- 泛化性差:以前的模型多是为语音设计的(Speech-centric),面对音效、交响乐等具有复杂非周期波形的信号时,重建出的高频部分往往听起来非常“假”。
2. 核心直觉:潜空间中的“直线”飞行
LatentFlowSR 的成功源于它对生成路径的重新设计。作者认为与其在复杂的波形表面爬行,不如在压缩后的潜空间里开辟一条“直线”。
2.1 噪声鲁棒自编码器 (NRAE)
为了建立一个高质量的潜空间,作者设计了一个基于 Snake 激活函数的自编码器。关键创新在于:在训练自编码器时主动向 Latent 注入高斯噪声。
- Insight:生成模型预测出的 Latent 往往与 Ground Truth 存在微小偏移。如果 Decoder 只看完整无缺的 Latent,一旦预测有偏差,输出音频质量会断崖式下跌。注入噪声训练逻辑上类似于“数据增强”,让 Decoder 学会了容错。
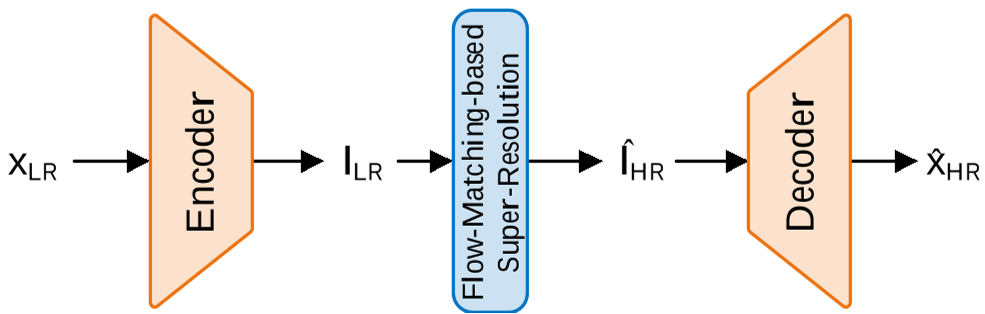 图 1: LatentFlowSR 整体框架,包含低分辨率编码、潜空间 CFM 补全、高分辨率解码三阶段。
图 1: LatentFlowSR 整体框架,包含低分辨率编码、潜空间 CFM 补全、高分辨率解码三阶段。
2.2 U-Net 驱动的流匹配
在潜空间中,如何从随机噪声转换到高质量信号?LatentFlowSR 弃用了多步耗时的扩散模型(Diffusion),选择了条件流匹配 (CFM)。
- ODE Solver:通过训练一个 U-Net 预测速度场,将概率分布的转移路径“拉直”。
- 推理加速:得益于 CFM 的确定性路径,该模型仅需 1 步(Euler Solver)即可完成高质量推理。
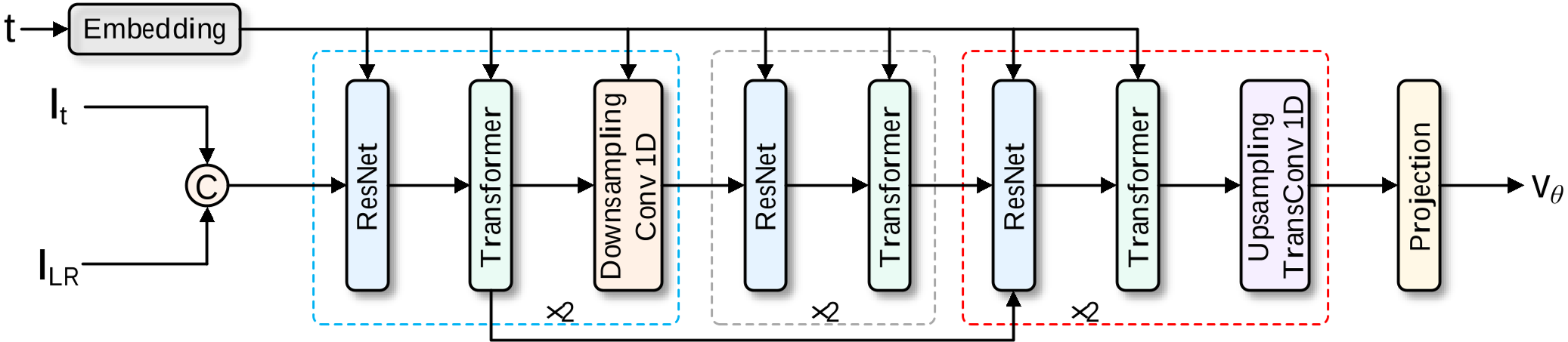 图 2: 速度场估计网络架构,结合了 ResNet 的局部特征提取和 Transformer 的全局建模。
图 2: 速度场估计网络架构,结合了 ResNet 的局部特征提取和 Transformer 的全局建模。
3. 实验战绩:全能选手的压制力
在针对语音(VCTK)、环境音(ESC-50)和音乐(MUSDB18-HQ)的全面评测中,LatentFlowSR 展现了统治级的通用性。
3.1 跨品类音质评测
在 8kHz -> 44.1kHz 的极端挑战下,LatentFlowSR 在客观指标 LSD(对数谱距离)和 ViSQOL(主观感官评价模拟)上均位居榜首。
- 音乐场景:LSD 相比最强基线 FlashSR 降低了约 0.3 点。
- 鲁棒性:在未见过的音效数据集上,主观 MOS 评分比低分辨率输入提升了 80% 以上。
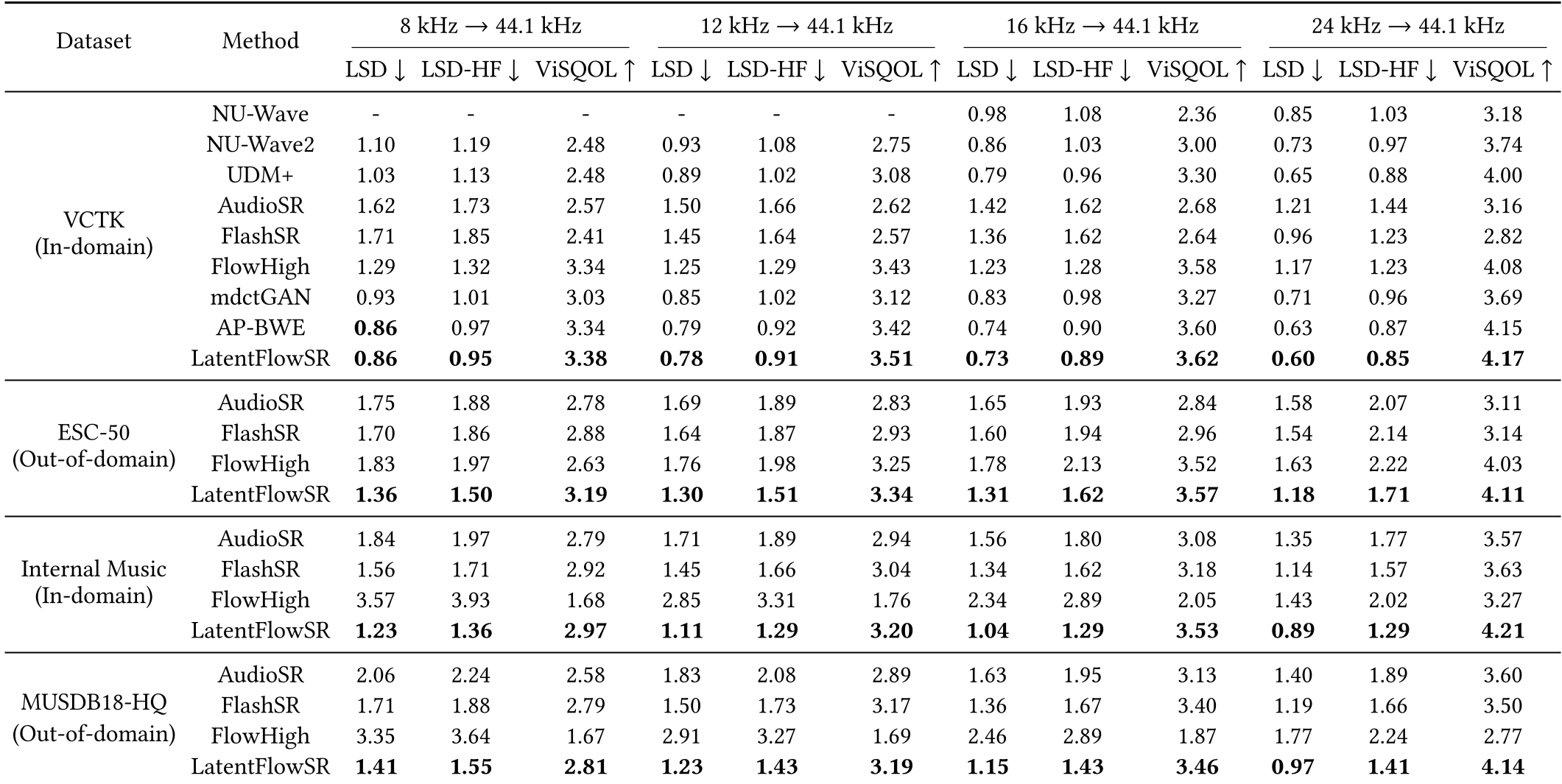 表 1: 不同音频类型下的超分性能对比,LatentFlowSR(最后一行)在各项指标上保持领先。
表 1: 不同音频类型下的超分性能对比,LatentFlowSR(最后一行)在各项指标上保持领先。
3.2 恐怖的计算效率
下表对比了目前主流超分模型的复杂度。LatentFlowSR 的参数量仅为 AudioSR 的 4.2%,计算量(FLOPs)则仅为其 0.08%。甚至在与同样使用流匹配但基于 Mel 谱的项目 FlowHigh 相比时,计算量也缩减了 25 倍。
 表 2: 模型复杂度分析,展示了潜空间建模带来的效率红利。
表 2: 模型复杂度分析,展示了潜空间建模带来的效率红利。
4. 深度洞察:为什么潜空间胜过 Mel 谱?
传统的音频生成任务(如 TTS)高度依赖 Mel 谱。但本论文的消融实验(Ablation Study)给出了不同建议:
- 连续胜过离散:使用连续潜空间的效果优于 DAC 这种基于 VQ-VAE 的离散空间(LSD 从 1.29 降至 1.24)。
- 噪声鲁棒是刚需:去掉噪声训练后(w/o NR),效果明显下滑,验证了现实推理中 Latent 漂移的影响。
- 效率降维打击:将超分任务下放到压缩后的潜空间,由于时域深度被大幅压缩,使得轻量化 U-Net 能够捕获全局长程依赖,同时保持低功耗。
5. 总结与展望
LatentFlowSR 不仅是一个 SOTA 级别的音频超分模型,它更向社区传递了一个信号:音频生成的下一站可能是更加精炼的潜空间 CFM 建模。 它的极低延迟特性使其非常有潜力集成到实时通讯协议(如 Zoom, Discord)或复旧音樂修复插件中。
局限性:尽管目前在 44.1kHz 表现卓越,但在更高的 48kHz 或 96kHz 专业母带级超分场景下,潜空间的压缩比与重建损失之间的平衡点仍需进一步探索。